
48
How To Build a Tweet Manager with Django, Tweepy and Fauna.
Authored in connection with the Write with Fauna program.
Tracking and managing tweet analytics has never been easier. This article will guide you to build a tweet management application using the Django web framework and Tweepy, then implementing the database with Fauna. This tweet manager will allow users to track tweet analytics, trends you tweeted, and save a report of the current tweet information in the database for easy reference.
To fully understand this tutorial, you are required to have the following in place:
With the above prerequisites out of the way, we can now begin building our tweet management application.
Fauna is a client-side serverless database that uses GraphQL and the Fauna Query Language (FQL) to support various data types and particularly relational databases in a serverless API. You can learn more about Fauna in their official documentation here. If this is the first time you hear about Fauna, visit my previous article here for a brief introduction.
To make use of the Twitter official API, you need to set up your Twitter developer account. Go to https://developer.twitter.com and signup if you haven’t. To sign up, you will need to provide detailed information on how you want to utilize your access to the Twitter API. After providing the information, you will need to wait for Twitter to verify and enable your account.
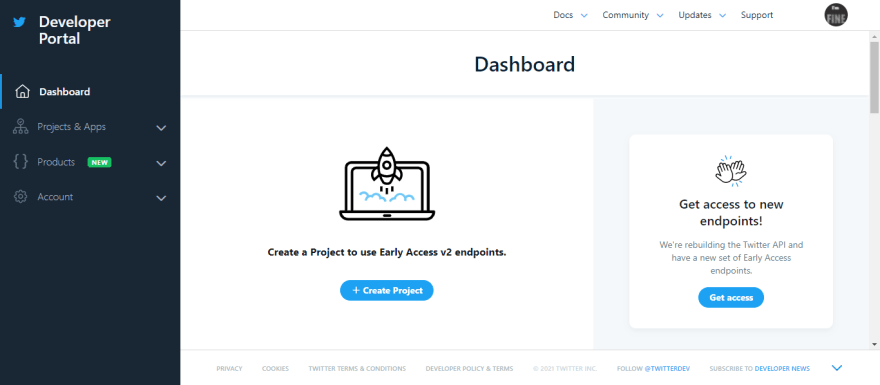
When your account is verified, go to your developer dashboard, as seen in the image above.
At this point, you need to create a project which can house multiple applications. Click on
create project then give your project a name, use case, and a description.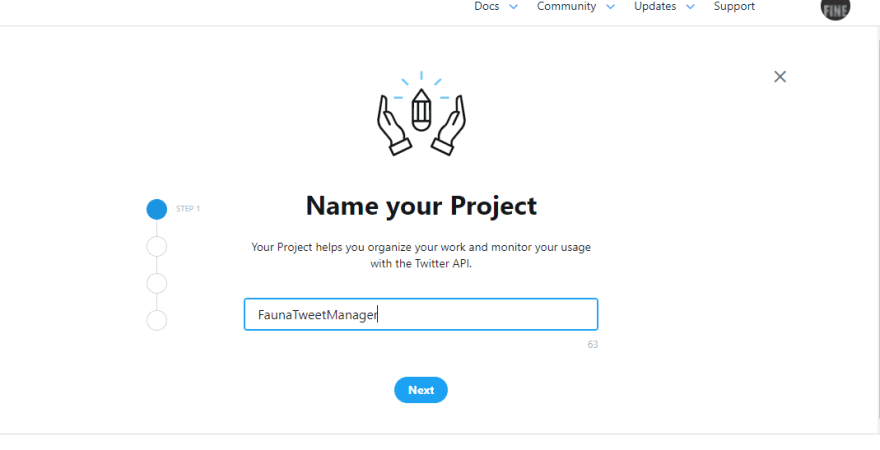

Now you need to create an application. To do this, click on “create a new app” and provide a name for your application.

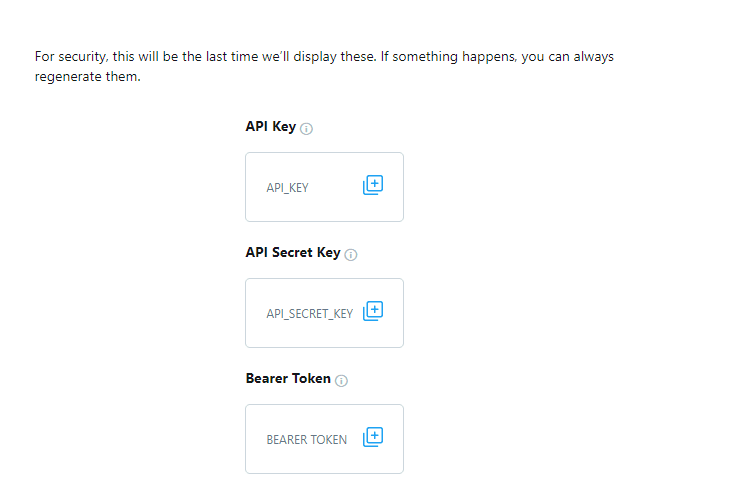
After creating your Twitter application, you will see a page with your application keys, as seen in the image below. Copy and save them somewhere you can easily retrieve them.
Go to the Project menu to then open your project. In the apps section, click on the key icon, then generate an
access token and access secret token for your application at the bottom of the page displayed.
Click on the generate button, then copy and save the access_token and access_secret_token somewhere you can easily retrieve them.
To create a Fauna database, you have first to create an account. After making one, you can create a new database by clicking on the
CREATE DATABASE button on the dashboard.
After clicking on the button as shown in the image above, you need to give your database a name then save it.
Create two collections in your database, the
Followers collection, and the TweetsReport collection. The Followers collection will store the current number of followers the user has in the database, while the TweetsReport will store the reports generated in the database. For the History days and TTL use the default values provided and save.Create two indexes for your collections;
report_index and followers_index. The report_index index will allow you to scroll through data in the TweetsReport collection. It has one term, which is the status field. This term will enable you to match data with the status for easy querying.The
followers_index will allow you to scroll through data in the Followers collection. This index will also allow matching with the status field to perform queries.Below are what your indexes will look like after saving them.

To generate an API key, go to the security tab on the left side of your dashboard, then click
New Key to create a key. You will then be required to provide a database to connect to the key. After providing the information required, click the SAVE button.
Fauna will present you with your secret key in the image above (hidden here for privacy) after saving your key. Make sure to copy your secret key from the dashboard and save it somewhere you can easily retrieve it for later use.
Now you will be learning how to implement the various functionalities of the tweet management application.
Run the code below in your command line to clone the repo containing the Django app on Github and install all required libraries.
#cloning the repo
git clone https://github.com/Chukslord1/FAUNA_TWEETS_MANAGER.git
# installing tweepy
pip install django
# installing tweepy
pip install tweepy
# installing faunadb
pip install faunadbWe will be doing all our application logic in the
views.py file for our Django application. Go to your views.py to see the code below.from django.shortcuts import render,redirect
from django.contrib import messages
from django.core.paginator import Paginator
from django.http import HttpResponseNotFound
from faunadb import query as q
import pytz
from faunadb.objects import Ref
from faunadb.client import FaunaClient
import hashlib
import datetime
import tweepy
from django.http import JsonResponse
import jsonTo initialize the Fauna client and Tweepy, copy the code below and provide the API keys you created earlier where necessary in your
views.py file. On the first line in the code below, we initialized our Fauna client by providing our secret key. In the following few lines, we initialized out Tweepy API by providing our api key, api secret key, access token, access token secret, username and screen name which is the same as the username.client = FaunaClient(secret="fauna_secret_key")
api_key = "api_key"
api_secret = "api_secret"
access_token = "access_token"
access_token_secret= "access_token_secret"
username= "username"
screen_name=username
auth = tweepy.OAuthHandler(api_key, api_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
user=api.me()The index page is where all the data needed is rendered to the user on the dashboard. Also, this is where our application will generate the tweet reports. We will be focusing on building the logic of this page.
Firstly, we query the Tweepy for all tweets created that week. The code below implements this functionality.
# querying tweets created this week
tmpTweets = api.user_timeline(screen_name=username,count=100, include_rts = True)
today = endDate = datetime.datetime.now()
startDate = today - (datetime.timedelta(today.weekday() + 1))
tweets=[]
for tweet in tmpTweets:
if endDate >= tweet.created_at >= startDate:
tweets.append(tweet)
words.extend(set(tweet.text.lower().split()) & all_trends)# querying for the current trends in your location you tweeted on
COUNTRY_WOE_ID = 23424908 #where on earth id of Nigeria
all_trends = set()
country_trends = api.trends_place(COUNTRY_WOE_ID)
trends = json.loads(json.dumps(country_trends, indent=1))
for trend in trends[0]["trends"]:
all_trends.add((trend["name"].lower().replace("#","")))
tweeted_keywords=(sorted([(i, words.count(i)) for i in set(words)], key=lambda x: x[1], reverse=True))Next, we queried Tweepy for all the followers we have made since the last page visit. We saved the current number of followers in our
Followers collection to get the new followers. The code below implements this functionality.#querying number of new followers since last page visit
# checking if the number of followers is saved. if not, save it
try:
previous_follower = client.query(q.get(q.match(q.index("followers_index"), True)))
previous_follower_count = client.query(q.get(q.match(q.index("followers_index"), True)))["data"]["follower_count"]
except:
follower_count_create = client.query(q.create(q.collection("Followers"),{
"data": {
"follower_count": user.followers_count,
"created_at": datetime.datetime.now(pytz.UTC),
"status":True
}
}))
previous_follower_count=user.followers_countIn the code above, we calculated the number of followers, then updated the document in the
Followers collection if the number of followers retrieved from the database and the one retrieved from Tweepy are different since the last page visit.# calculating new followers since last page visit
new_followers=user.followers_count-previous_follower_count
#updating the database if there is a change in followers since last visit
if previous_follower_count == user.followers_count:
pass
else:
follower_count_update = client.query(q.update(q.ref(q.collection("Followers"), previous_follower["ref"].id()), {
"data": {
"follower_count": user.followers_count,
"created_at": datetime.datetime.now(pytz.UTC),
"status":True,
}
}))Lastly, we created the report creation logic. The code below implements this functionality.
# generating a report for the tweets currently and saving in the database
if request.method=="POST":
generate=request.POST.get("generated")
report_date= datetime.datetime.now(pytz.UTC)
report_details = "Number of followers :"+str(user.followers_count) + "\n Number following :"+str(user.friends_count) + "\n Number of Tweets This Week :"+str(len(tweets)) + "\n New Followers: "+str(new_followers)+ "\n Trends You Tweeted On:"+str(tweeted_keywords)
if generate == "True":
report_create = client.query(q.create(q.collection("TweetsReport"), {
"data": {
"report_date": report_date,
"report_details": report_details,
"status": True
}
}))In the code above, when the user sends a POST request, the data required to create the report is collated and saved in the
TweetsReport collection by making a query from the Fauna client.The final code for our index view should be similar to the one below.
def index(request):
# querying tweets created this week
tmpTweets = api.user_timeline(screen_name=username,count=100, include_rts = True)
today = endDate = datetime.datetime.now()
startDate = today - (datetime.timedelta(today.weekday() + 1))
tweets=[]
new_followers=0
words=[]
all_trends = set()
COUNTRY_WOE_ID = 23424908
country_trends = api.trends_place(COUNTRY_WOE_ID)
trends = json.loads(json.dumps(country_trends, indent=1))
for trend in trends[0]["trends"]:
all_trends.add((trend["name"].lower().replace("#","")))
for tweet in tmpTweets:
if endDate >= tweet.created_at >= startDate:
tweets.append(tweet)
words.extend(set(tweet.text.lower().split()) & all_trends)
tweeted_keywords=(sorted([(i, words.count(i)) for i in set(words)], key=lambda x: x[1], reverse=True))
try:
previous_follower = client.query(q.get(q.match(q.index("followers_index"), True)))
previous_follower_count = client.query(q.get(q.match(q.index("followers_index"), True)))["data"]["follower_count"]
except:
follower_count_create = client.query(q.create(q.collection("Followers"),{
"data": {
"follower_count": user.followers_count,
"created_at": datetime.datetime.now(pytz.UTC),
"status":True
}
}))
previous_follower_count=user.followers_count
new_followers=user.followers_count-previous_follower_count
if previous_follower_count == user.followers_count:
pass
else:
follower_count_update = client.query(q.update(q.ref(q.collection("Followers"), previous_follower["ref"].id()), {
"data": {
"follower_count": user.followers_count,
"created_at": datetime.datetime.now(pytz.UTC),
"status":True,
}
}))
if request.method=="POST":
generate=request.POST.get("generated")
report_date= datetime.datetime.now(pytz.UTC)
report_details = "Number of followers :"+str(user.followers_count) + "\n Number following :"+str(user.friends_count) + "\n Number of Tweets This Week :"+str(len(tweets)) + "\n New Followers: "+str(new_followers)+ "\n Trends You Tweeted On:"+str(tweeted_keywords)
if generate == "True":
report_create = client.query(q.create(q.collection("TweetsReport"), {
"data": {
"report_date": report_date,
"report_details": report_details,
"status": True
}
}))
context={"followers":user.followers_count,"following":user.friends_count,"weekly_tweet":len(tweets),"new_followers":new_followers}
return render(request,"index.html",context)
The user can view all the reports they have generated and saved to the database on this page.
def reports(request):
get_reports= client.query(q.paginate(q.match(q.index("report_index"), True)))
all_reports=[]
for i in get_reports["data"]:
all_reports.append(q.get(q.ref(q.collection("TweetsReport"),i.id())))
reports=client.query(all_reports)
context={"reports":reports}
return render(request,"reports.html",context)In the code above, we made a query to the Fauna client to retrieve all documents in the
TweetsReport collection where the status field is True using the reports_index index and Fauna’s paginate method. This data is then rendered in context to the user interface to be viewed by the user.
Here, we imported the required modules and defined our app’s URLs connected to our created views.
from django.conf import settings
from django.conf.urls.static import static
from django.urls import path, include
from . import views
app_name = "App"
urlpatterns = [
path("", views.index, name="index"),
path("index", views.index, name="index"),
path("reports", views.reports, name="reports"),
]This article taught you how to build a tweet management application with Fauna's serverless database, Tweepy, and Django. We saw how easy it is to integrate Fauna into a Python application, query data from Twitter using Tweepy, and save them.
The source code of our tweet manager is available on Github. If you have any questions, don't hesitate to contact me on Twitter: @LordChuks3.
48