
22
Multidimensional Scalability Model for Application
This blog is about how to observe scaling problems in a multidimensional way. Scale cube is an influential and straightforward concept that can be a vehicle to focus on scalability-related discussions, approaches, and implementations. Let’s start by going over the different ways of scaling an application, including its benefits and drawbacks. In the end, I will use one of my applications as a case study to demonstrate these dimensions to draw a picture of how they fit in the real world.

The cube model defines three ways to scale our applications: X, Y, and Z. Progress on each axis solve different scalability problems; to bring the right scalability balance for our application, we will move the needle to varying lengths on these three axes.
Here the method of scaling is by cloning or replicating. It is one of the popular ways to scale an application. It involves running multiple application instances doing the same task. The load balancer distributes requests among the N identical instances of the application, and each instance works 1/N of the load.
The x-axis approach is easy to implement in most cases. You take the same code that existed in a single instance implementation and put it on as multiple instances. If your application is “stateless,” you simply load balance all of the inbound requests to any of the N systems. If your application is “stateful,” the implementation is slightly more complex. Making your application cluster-friendly is the demanded effort before cloning.
This approach is an excellent way of improving the capacity and availability of an application. On the downside, x-axis implementations are limited by the growth of a monolithic application, and they do not scale well with increases in data or application size. Further, they do not allow engineering teams to scale well, as the code base is monolithic, and it can become comparatively complex over time.
Y-axis scaling splits your application into multiple services by the separation of work responsibility. Travelling in Y-axis is a journey towards a pure microservices architecture. The common challenge with the idea of microservices architecture is with the term micro. Instead of debating on “What should we define as the size of micro?”, it is better to see this scaling as a functional decomposition to give the application multiple deployable modules. Application complexity and business capability can help decide the modules.
Y-axis scaling has a blind spot. What I mean by this is, at a very high level, it is often possible to implement a y-axis split in production without actually breaking the codebase itself. However, a clean separation at the codebase is needed to get the most benefits of this approach.
“There is only one codebase per app…” — 12factor app.
The Y-axis scaling tends to be more costly to implement for the brownfield application than the X-axis scaling. Still, it solves different kinds of issues than availability issues addressed by X-axis scaling. In addition to handling matters related to increasing development and application complexity, Y-axis splits support creating fault-isolative architectural structures.
Of course, this approach comes with its own set of new challenges to handle. It should be considered while making a trade-off — the number of distinct sub-applications increases the complexity around operations and shared-data management.
In general, when Engineering teams start to lose development velocity, that indicates an opportunity to scale further in the Y-axis. If the application is too large for any developer to understand fully, that is also a signal for decomposition.
Z-axis scaling is about scale by splitting similar things based on a “looked up” value, a.k.a attribute. This scaling also runs multiple instances of the application, but unlike X-axis scaling, each instance is responsible for only a subset of the data or the workload. In the later section, we will see this with an example.
Very often, this approach offers a first-class scaling at the fine grain. An increase in fault isolation and scaling at the partition level are the key benefits of this approach. This approach can be combined with x-axis scaling to bring availability along with partition level fault isolation.
Though we may not be creating multiple instances in the z-axis right away, it is best to keep this as a vision or end goal while making significant design decisions for your application. It is very well possible that different customers have a different level of priority and weightage to a different partition of your application. For example, if I have to scale one partition much higher than the other partitions to serve customer-specific usage patterns better, designing application architecture to support z- scaling is essential.
An interesting observation is that: Z-axis is a little easy from a design perspective for a greenfield project. But, this scaling tends to be the most costly for brownfield applications.
(Each scaling axis solution should handle caching strategy differently to get even more out of these approaches. This is another topic for another time)
This section will demonstrate how the scalability cube perspective helped boost my application scalability needs; let’s call this app App-X (intentionally, I am skipping the business use case here to keep it simple).
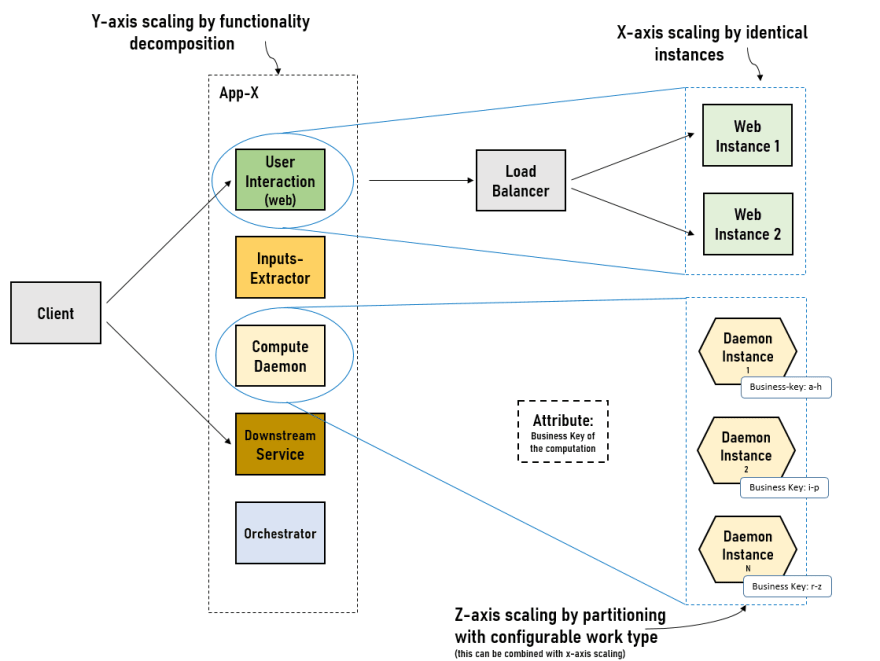
When the application development team started with a two-pizza size (group small enough to be fed with two pizzas), App-X as one application is a good starting point. When the App-X was relatively small, monolithic architecture had many benefits: simple to develop, easy to make radical changes to the application, and straightforward to deploy. In an initial couple of years, the application went through constant changes to the data model as the requirements start to grow; monolithic made it easy for the high-velocity agility.
However, over time, to manage the growing complexity, decomposition is a necessary step. Functionally decomposing extensive application into multiple independently deployable modules is an ongoing process for any application. The App-X now has numerous components for various work modules — one for computing-unit, one for UI, one for input-extraction, one for calculator services, one for the reuseable internal library, and one for downstream services orchestrator and so on. Even the clear separation at the codebase level is what we achieved.
The significant benefit of this scaling is to provide high availability. Hence, we started with a user-facing component of App-X. This application is not a simple stateless application. So, it has to go through the pre-step of making the app cluster-friendly. Then, this component has been containerized and enhanced to work with active-active mode. However, for the computation component of App-X, it could use more than this one-dimensional scaling. Y- and Z- axis scaling can be much more beneficial to this component.
Similar to how x-axis scaling requires your application to be stateless or cluster-friendly, z-axis scaling also needs pre-step if the application is designed in a traditional N-tier layered architecture with centralized execution control. That was a case in App-X.
To enable the z-axis capability, the computational component should be stripped independently based on the attribute (in App-X, it was partitioned by business attribute); this needs a redesign of the computational-unit-driver to move to hexagonal architecture style from layered architecture style. In that context, a small scale spike was done to make the sub-component of the computation unit to be independently launchable. The idea is to create configurable swim lanes. We will go over this in detail, maybe in another blog. For now, let's see splitting by attribute as just an example to demonstrate how the z-axis scaling will look like.
This approach will enable us to scale computational-unit-internal workload in isolation and on-demand. And, This will provide much more control over the execution of work units and pave a step towards a configurable concurrent model.
The cube model is not something new; in fact, this was first published a decade back in ‘The Art of Scalability’ book. However, it is worth rehashing these concepts when tackle scalability needs.
- For a greenfield project, it is vital to architect your application to support scalability in a multidimensional way, even if you will not launch the n-instances of your app on day one. Because bringing these capabilities later is very costly. So, make it cluster-friendly, make it as modular as possible, make it independently launchable and deployable units by design.
- For a brownfield project, deciding when-to scale, what-direction-to scale, how many splits to create is not straightforward. It is both science and art. However, using incident and production issues history analysis to spot the scale bottlenecks could be a good starting point to figure out the scalability directions.
22