
19
Scrape Google Organic Search with Python
Contents: intro, imports, what will be scraped, code, links, outro.
This blog post is a continuation of Google's web scraping series. Here you'll see examples of how you can scrape Google Organic Search Results using Python. An alternative SerpApi solution will be shown.
import lxml, requests
from bs4 import BeautifulSoup
from serpapi import GoogleSearchTitle, link, displayed link, snippet

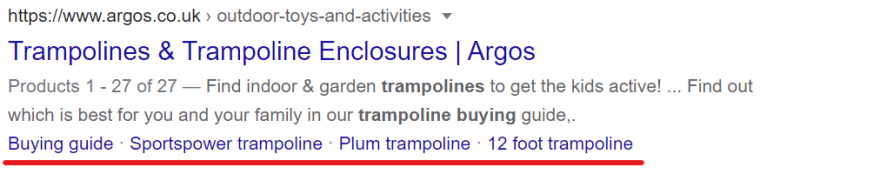
Inline sitelinks
Expanded sitelinks

Headers
Make sure you specified HTTP header user-agent so Google won't block your requests, otherwise it will block it eventually. Why? Without a headers it might think that your request is a request from a bot (script) which it is.
Example of passing headers into request:
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
requests.get('https://www.google.com/search', headers=headers)
# other codeimport requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "apple",
"hl": "en",
}
html = requests.get("https://www.google.com/search", params=params, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')
# container with all needed data
for result in soup.select('.tF2Cxc'):
title = result.select_one('.DKV0Md').text
link = result.select_one('.yuRUbf a')['href']
displayed_link = result.select_one('.TbwUpd.NJjxre').text
snippet = result.select_one('#rso .lyLwlc').text
# inline sitelinks
for i in soup.select('.HiHjCd a'):
print(i.text)
# expanded sitelinks
for t in soup.select('.usJj9c'):
text = t.select_one('.r').text
text_link = t.select_one('.r a')['href']
snippet = t.select_one('.st').text
print(f'{text}\n{text_link}\n{snippet}\n')SerpApi is a paid API with a free trial of 5,000 searches.
The difference is that all that needs to be done is just to iterate over a ready made, structured JSON instead of coding everything from scratch, and selecting correct selectors which could be time consuming at times.
from serpapi import GoogleSearch
import json # just for prettier output
params = {
"api_key": "YOUR_API_KEY",
"engine": "google",
"q": "buy trampoline",
"hl": "en"
}
search = GoogleSearch(params)
results = search.get_dict()
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google",
"q": "cyber security",
"hl": "en",
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['organic_results']:
title = result['title']
link = result['link']
displayed_link = result['displayed_link']
snippet = result['snippet']
try:
inline_sitelinks = result['sitelinks']['inline']
except:
inline_sitelinks = None
try:
expanded_sitelinks = result['sitelinks']['expanded']
except:
expanded_sitelinks = None
print(f"{title}\n{link}\n{displayed_link}\n{snippet}\n")
print(json.dumps(expanded_sitelinks, indent=2, ensure_ascii=False))
print(json.dumps(inline_sitelinks, indent=2, ensure_ascii=False))
-----------------
# organic
'''
Trampolines - Sports & Outdoors - The Home Depot
https://www.homedepot.com/b/Sports-Outdoors-Trampolines/N-5yc1vZc455
https://www.homedepot.com › Sports & Outdoors
Get free shipping on qualified Trampolines or Buy Online Pick Up ... Round Trampoline with Safety Enclosure Basketball Hoop and Ladder.
'''
# expanded sitelinks
'''
[
{
"title": "Store",
"link": "https://m.dji.com/",
"snippet": "Mavic Series - Refurbished Products - Buy Osmo Series - ..."
}
]
'''
# inline sitelinks
'''
[
{
"title": "Pure Fun",
"link": "https://www.homedepot.com/b/Sports-Outdoors-Trampolines/Pure-Fun/N-5yc1vZc455Zdeo"
}
]
'''If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.

19