
25
Find an audio within another audio in 10 lines of Python
One of the fun (and sometimes handy) digital audio processing problems is to find an audio fragment within another, longer, audio recording. Turns out, a decent solution only takes about 10 lines of Python code.
What we essentially want is an offset of the short clip from the beginning of the longer recording. In order to do that, we need to measure similarity of two signals at various points of the longer signal - this is called cross-correlation and has applications beyond audio processing or digital signal processing in general. We will use well-known libraries such as NumPy that implement all the algorithms for us, we will basically need to just connect the plumbing, if you will.
Well, actually the solution will take a bit more than 10 lines of Python, mostly because I'm generous with whitespace and want to actually build a handy CLI tool. We'll start with the
main() implementation:def main():
parser = argparse.ArgumentParser()
parser.add_argument('--find-offset-of', metavar='audio file', type=str, help='Find the offset of file')
parser.add_argument('--within', metavar='audio file', type=str, help='Within file')
parser.add_argument('--window', metavar='seconds', type=int, default=10, help='Only use first n seconds of a target audio')
args = parser.parse_args()
offset = find_offset(args.within, args.find_offset_of, args.window)
print(f"Offset: {offset}s" )
if __name__ == '__main__':
main()Here we define the interface of our CLI tool that takes two audio files as arguments as well as the portion of target signal we want to use for calculations - up to 10 seconds is a reasonable default. Next step is to actually implement
find_offset function.First, we'll use a library called
librosa to read both of our audio files, match sampling rate and convert them to raw samples in float32 format (almost) regardless of the original audio format. The last part is accomplished with ffmpeg which is used basically everywhere where AV processing is involved.y_within, sr_within = librosa.load(within_file, sr=None)
y_find, _ = librosa.load(find_file, sr=sr_within)Next line is where the actual magic happens - we perform cross-correlation of the parent signal and the target signal (or a
window of it) using Fast Fourier Transform (FFT) method:c = signal.correlate(y_within, y_find[:sr_within*window], mode='valid', method='fft')What we get is an array of numbers, each of them representing similarity of the target audio to the longer recording at each point of it. If we plot it, it'll look something like this:
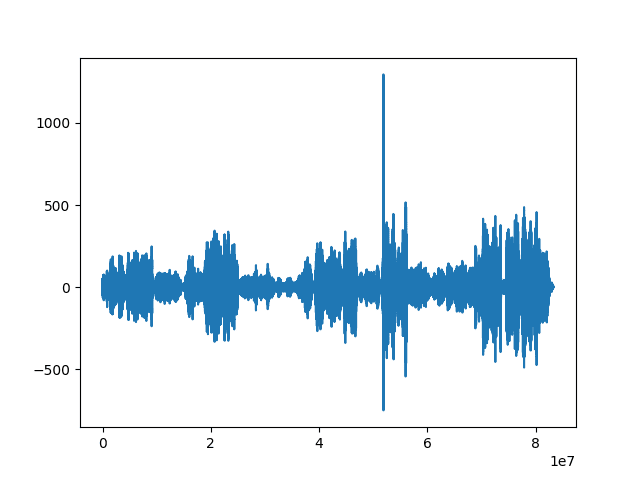
X axis represents indexes of parent audio samples and if it has a sampling rate of 16 kHz, every second is represented by 16000 samples. We can see a sharp peak - this is where our signals are the most similar.
X axis represents indexes of parent audio samples and if it has a sampling rate of 16 kHz, every second is represented by 16000 samples. We can see a sharp peak - this is where our signals are the most similar.
The last thing we need to do is to find an index of a sample where similarity of two signals is the highest and divide it by the sampling rate - that'll be the offset (in seconds) that we want.
peak = np.argmax(c)
offset = round(peak / sr_within, 2)I'm a big heavy metal and Black Sabbath fan so I'll use an audio from their lesser known live DVD called Cross Purposes Live. I used the Mac tool called
From that show I particularly like the song called Cross of Thorns and if I cut a clip of it and run the CLI tool we just programmed with it and the full recording, I'll get an offset of
PullTube to download the video clip and ffmpeg to extract the audio and convert it to WAV at the 16 kHz sampling rate.From that show I particularly like the song called Cross of Thorns and if I cut a clip of it and run the CLI tool we just programmed with it and the full recording, I'll get an offset of
3242.69 seconds which is precisely the moment the song starts in the Youtube video. Voilà!You can find the full source code on Github.
--
Thanks to Frank Vessia @frankvex for making this cover image available freely on Unsplash 🙏
https://unsplash.com/photos/Z3lL4l49Ll4
Thanks to Frank Vessia @frankvex for making this cover image available freely on Unsplash 🙏
https://unsplash.com/photos/Z3lL4l49Ll4
25