
34
AWS open source news and updates #77
Newsletter #77.
This week we have more new open source projects including schema-manager, maildog, ddbcereal, ecr-scan-reporter and more. This weeks AWS and community blog posts cover topics such as PartiQL, ConsoleMe, Yor, Kubernetes, Debezium, Apache Kafka, Apache Spark, Redis, HPC and more. Also, don't miss the great video on getting up and running with Amazon EMR on Apache Airflow.
Observability (o11y) newsletter
If you had not already signed up for this, then perhaps now is a great time. Colleague Michael Hausenblas has been curating this essential weekly list of everything you need to know about Observability in the o11y newsletter. You can subscribe via https://o11y.news/ and you can check out last weeks edition here
This really is a great way to stay on top of all things Observability.
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Damon Cortesi, Justin Turner Arthur, Dominic Nightingale, John Preston, Edmund Hung, Taylor Smith, Jones Zachariah Noel, Bhuvanesh R, Viktor Pankov, Ian Lim, Seungjune Kim, Ben Smith, José Lorenzo Cuéncar, Nina Vogl, Matthew Miller, Brendan Bouffler, Sukhpreet Kaur Bedi, Elizabeth Nguyen, Melody Yang, Shiva Achari, Avnish Jain, Justin Garrison, Jesse Butler, Matt Auerbach, Abhinav Krishna Vadlapatla, Pablo Redondo Sanchez and Johannes Kupser.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
These are the latest projects from the last week or so that popped up on my radar. Check them out.
schema-manager
maildog
ddbcereal
ecr-scan-reporter

ucsd_robo_car_aws_deepracer

aws-groundstation-cli-contact-control
amazon-ivs-chime-messaging-ugc-demo

Yor
Yor is an open-source tool that helps add informative and consistent tags across infrastructure-as-code frameworks such as Terraform, CloudFormation, and Serverless. In this post, Best Practices for AWS Tagging With Yor Taylor Smith shows you how you can use it to apply some best practices to your AWS environments. This is a must read post this week, great stuff.
PartiQL
PartiQL is an open source project that provides a SQL-compatible query language that makes it easy to efficiently query data, regardless of where or in what format it is stored. In this post, DynamoDB with PartiQL Jones Zachariah Noel shows you how you can use this with AWS DynamoDB, and how this can make it easier for developers to with a SQL background to get started with DynamoDB.
Debezium
ConsoleMe
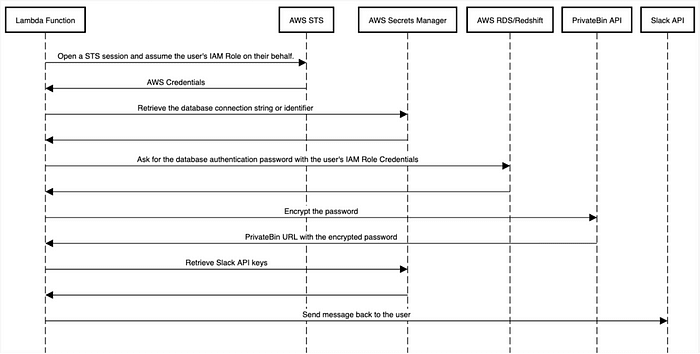
ConsoleMe is an open source web service from Netfix that makes AWS IAM permissions and credential management easier for end-users and cloud administrators, providing numerous ways to log in to the AWS Console. This post, Improving database security at FollowAnalytics with AWS IAM database authentication and ConsoleMe from Hugo Henley shares how he has used ConsoleMe to provide secure access to his databases.
Kubernetes
A couple of posts this week worth diving deep into.
First up we have Catching up with Managed Node Groups in Amazon EKS from Jesse Butler who brings you up to speed with the updates from Managed Node Groups in Amazon EKS, including feature updates, AMI changes and version support and a look ahead to what is coming soon.
Following that we have Justin Garrison with Amazon EKS now supports Kubernetes 1.21, everything you need to know about the latest version supported. The post covers highlights and new features worth knowing about, feature deprecations, some upgrade consideration and end of life reminders.
AWS Copilot
AWS Copilot CLI is a tool for developers to build, release and operate production ready containerized applications on AWS App Runner, Amazon ECS, and AWS Fargate. In this post, Fast forward on your first serverless container deployment on AWS, Johannes Kupser shows you how you can use it to deploy your first containerised application on AWS. He shows you how it makes it easy not just to initially deploy the application, but to redeploy once you have made changes.
AWS Amplify
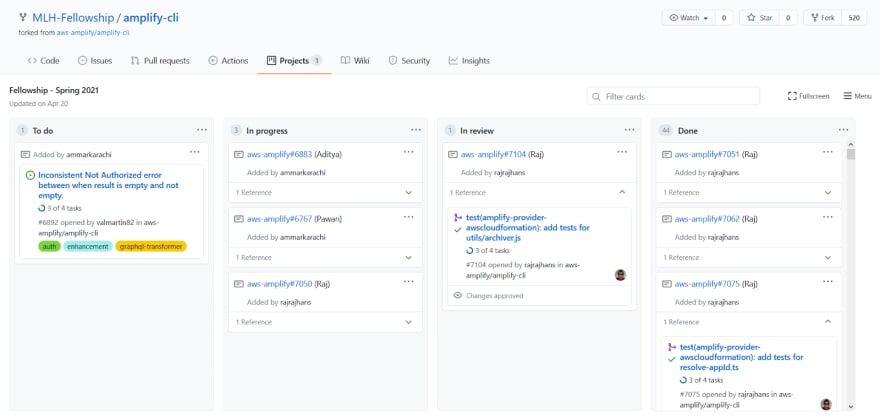
Matt Auerbach shared last week this post, MLH Fellows Spring 2021, that brings us up to speed with the latest cohort of students that are part of the Major League Hacking (MLH) Fellowship, and their work as part of the Amplify cli. The post covers introductions to the four Amplify Fellows, a description of their projects and what they learned.
Apache Spark
Apache Spark is an open-source, distributed data processing framework capable of performing analytics on large-scale datasets, enabling businesses to derive insights from all of their data whether it is structured, semi-structured, or unstructured in nature. However, for organisations accustomed to SQL-based data management systems and tools, adapting to the modern data practice with Apache Spark may not come as quickly as they would like.
In this post, Build a SQL-based ETL pipeline with Apache Spark on Amazon EKS, from Melody Yang, Shiva Achari, and Avnish Jain, show you how you can use another open source data processing framework, Arc, to address this challenge. Arc is an opinionated framework for defining predictable, repeatable and manageable data transformation pipelines and takes a SQL first approach. This enables you to combine the best of both worlds, abstracting the Apache Spark and container technologies, so you can build a modern data solution on AWS managed services simply and efficiently. [hands on]

Apache Flink
Apache Flink is an open-source framework and engine for processing data streams. In this post, Secure multi-tenant data ingestion pipelines with Amazon Kinesis Data Streams and Kinesis Data Analytics for Apache Flink Abhinav Krishna Vadlapatla and Pablo Redondo Sanchez show you how you can use Apache Flink to continuously process messages in near-real time and store them in Amazon S3. [hands on]
Redis and Memcached
Elizabeth Nguyen provides news about some new training videos that you can use to learn about how to set up, run, and scale in-memory data stores in the cloud with Redis or Memcached via Amazon ElastiCache. The training materials will walk you through key use cases, Redis and Memcached data structures, caching patterns, and more.
If this sounds like something you want to dive deeper into, go ahead and check out the post, Get started with Amazon ElastiCache for Redis and Memcached: Introducing the ElastiCache learning path
PostgreSQL
Sukhpreet Kaur Bedi wrote this post last week, Schedule jobs with pg_cron on your Amazon RDS for PostgreSQL or Amazon Aurora for PostgreSQL databases that provides you some reasons why you might want to use pg_gron, and then how you can use pg_cron to automate some maintenance tasks on your RDS for PostgreSQL or Aurora PostgreSQL workloads. [hands on]
AWS ParallelCluster
José Lorenzo Cuéncar and Nina Vogl show you how to bring up an HPC cluster, prepare, install, and run applications and visualise the results, all without needing a single piece of hardware in the blog post, How to put a supercomputer in the hands of every scientist

Bonus
Also, check out this Tweet thread from Brendan Bouffler that provides some additional info on how AWS ParallelCluster was able to support a global Hackathon. Some great nuggets in there.
AWS Serverless Application Model (SAM)
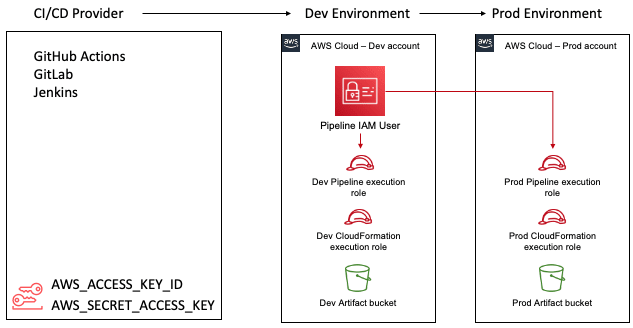
AWS Serverless Application Model (SAM) is an open-source framework for building serverless applications. In this post, Introducing AWS SAM Pipelines: Automatically generate deployment pipelines for serverless applications, Ben Smith shares news of the public preview of AWS SAM Pipelines, a new capability of AWS Serverless Application Model (AWS SAM) CLI. AWS SAM Pipelines makes it easier to create secure continuous integration and deployment (CI/CD) pipelines for your organisations preferred continuous integration and continuous deployment (CI/CD) system. This post covers how you can do that with GitLab CI/CD, but others are supported (GitHub Actions, Jenkins and AWS CodePipeline) [hands on]
Apache Airflow
Damon Cortesi put this video together last week showing you how you to use Amazon EMR on EC2 and EKS with Amazon Managed Workflows for Apache Airflow.
AWS SDK for Java
We have released the AWS SDK for Java 2.17, which removes the SDK’s external dependency on the popular third-party JSON library, Jackson. This means that AWS SDK for Java 2.x no longer requires an external copy of Jackson-databind, Jackson-core, or Jackson-dataformat-cbor in order to function. This release does not change any of the public AWS SDK APIs.
Read more in the blog post from Matthew Miller, The AWS SDK for Java 2.17 removes its external dependency on Jackson
Open Data Lakes with Presto, Apache Hudi & AWS Glue and S3 – the next generation of analytics
July 27th at 10am PT/ 1pm ET
Sign up for this roundtable discussion where experts from each layer in this stack – Presto, AWS, and Apache Hudi – will discuss why they are seeing a pronounced adoption to this next generation of cloud data lake analytics and how these technologies enable open, flexible, and highly performant analytics in the cloud.
Read more and register here
Cloud Native Day
23rd September, Bern Switzerland
What is this, an in person event returning? A stellar line up including our own Michael Hausenblas, an event looking at CNCF projects and the future of IT. Find out more and to view prices/register, by clicking here.
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on [@AWSOpen](https://twitter.com/AWSOpen
34