
33
Build a event-driven app with Micronaut, Kafka and Debezium
In this article we'll be building a event-driven app in Java using the Micronaut framework.
For the purposes of this article, it's fine to understand that:
- an event is a representation of a change in an state in a component, e.g.: user updated his name, new message saved at the database, the same as "user sent a new message", which is the same as "new message sent from user A to user B", etc.
- a event-driven architecture is an architecture based on reaction to events.
In this kind of architecture we have 3 key actors:
- Producers: the ones that create the events or, in other words, sends messages informing that something happened; these messages may contain a payload with relevant information for processing the event;
- Brokers: delivers the messages from producers to consumers
- Consumers: the ones that process (react to) the messages to perform a specific task.
Please note that a single service / app, may have different kinds of actors, e.g.: a chat backend app that consume new messages events and produces unread messages notification events.
The nature of these architectures makes them ideal to be employed for async processing and/or at apps with high load.
There are many resources that address every details and aspects of event-driven architectures, it's use cases, pros, cons, etc. I'll find them they linked among the article.
I was trying to come up with a "real-world example app" of an event-driven architecture that covered the basic aspects of such architectures and was simple enough to implement. It was when I remembered one example that Design Data-Intensive Applications uses to describe the concept of "load" on a system: the "fan-out" of tweets at Twitter.
I saw it as the example I was looking for. Maybe not as simple as I wanted to, but that's ok... I guess, please tell me later hahaha.
Anyways, what is this "fan-out" thing? Twitter has two main operations:
- Post a tweet: a user publishes a new message to it's followers (4.6 k requests/sec on average, over 12 k requests/sec at peak)
- Home timeline: a user views tweets published recently by users it follows (300 k requests/sec)
Twitter's scaling problems are not due to tweet posts, since it's ok to handle 12k write requests, but because of the "fan-out" to deliver it's tweets to users timelines, since each user follows many people and each user is followed by many people.
Fan-out is a term borrowed from electronic engineering, where it describes the number of logic gate inputs that are attached to another gate’s output. The output needs to supply enough current to drive all the attached inputs. In transaction processing systems, we use it to describe the number of requests to other services that we need to make in order to serve one incoming request.
Consider the following relational schema:
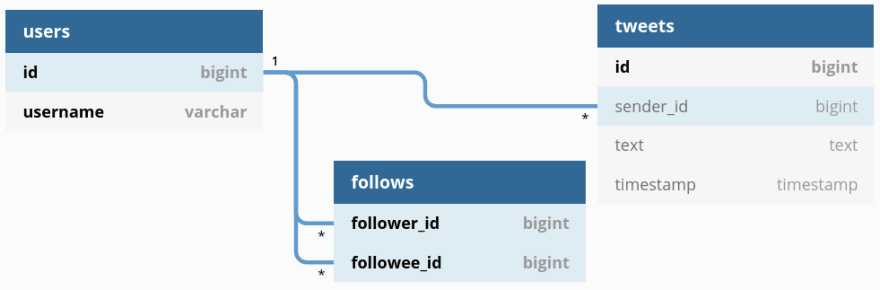
Probably the simplest approach to implement these operations would be to
- Post a tweet: simply insert the new tweet into the global tweets table.
- Home timeline: find all people the user follows and find their recent tweets. Something like:
SELECT tweets.*,
users.*
FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = CURRENT_USER
ORDER BY tweets.timestamp
LIMIT TIMELINE_SIZE;Although simple, this approach is not as fast as we would like, given the fan-out stuff.
Another approach (and the one that Twitter switched to after struggling to keep up with timeline loads, btw) is to keep, for each user, a cache for it's home timeline:
- Post a tweet: find all people that follows the tweet author and insert the new tweet at their home timeline caches.
- Home timeline: just read from the cache.
The second approach works because we have almost twice timelines reads as we have tweet posts, so it's ok to make an extra work when publishing.
We'll build a back-end system that implements the second approach.
This system should allow Users to (1) post tweets and (2) retrieve their home timelines. For simplicity, we'll not handle user creation, nor authentication / authorization, assuming that another component / service handles it so that we can focus on (1) and (2).
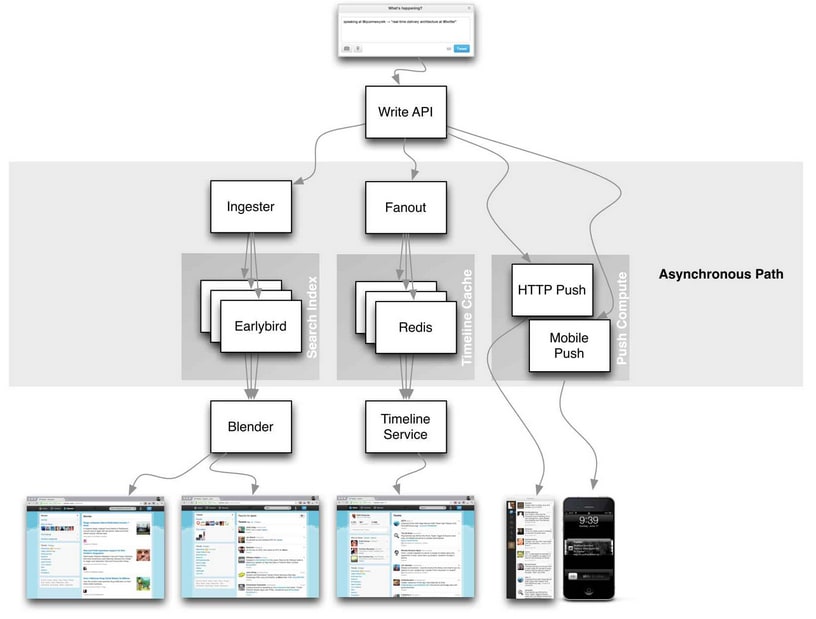
The diagram below illustrates the components of our system and how the data flows between them:

- the Tweets API allows our users to post / edit / delete tweets
- our database will be a PostgreSQL instance
- we'll use Debezium for change data capture with a Kafka Connect to publish tweet events to Kafka, which we'll use as a broker.
- we'll do so by using the "outbox pattern"
- the Tweets Delivery Worker, that will update user's home timeline caches upon new tweet events consumed from Kafka
- the Timeline Cache may simply be a in-memory cache, such as a Redis instance, and timeline requests are made to Tweets API, which, then, reads the cache to retrieve timeline tweets data and return it back to the user
You'll find the complete code available here.
We'll use the Micronaut framework.
To setup locally our external dependencies (like Postgres, Debezium, Kafka and Redis) we'll use Docker Compose.
version: '2.2'
services:
postgres:
container_name: postgres
image: 'postgres:11.2-alpine'
ports:
- 5432:5432
environment:
- POSTGRES_DB=tweets
- POSTGRES_PASSWORD=pass
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 5s
timeout: 3s
retries: 7
redis:
container_name: redis
image: 'redis:6.0-alpine'
hostname: redis
ports:
- '6379:6379'
zookeeper:
container_name: zookeeper
image: 'confluentinc/cp-zookeeper:4.0.3'
ports:
- "2181:2181"
environment:
- ZOOKEEPER_CLIENT_PORT=2181
kafka:
container_name: kafka
image: 'confluentinc/cp-kafka:4.0.3'
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_BROKER_ID: 1
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
depends_on:
- zookeeper
schema-registry:
container_name: schema-registry
image: 'confluentinc/cp-schema-registry:4.0.3'
environment:
- SCHEMA_REGISTRY_KAFKASTORE_CONNECTION_URL=zookeeper:2181
- SCHEMA_REGISTRY_HOST_NAME=schema-registry
- SCHEMA_REGISTRY_LISTENERS=http://schema-registry:8081
ports:
- "8081:8081"
wait-for-dependencies:
image: dadarek/wait-for-dependencies
container_name: wait-for-dependencies
scale: 0
command: redis:6379 schema-registry:8081 kafka:9092 zookeeper:2181 postgres:5432I like using https://dbdiagram.io to create my DB schema diagrams. It's quick and simple and has options to export the schema to SQL. 🆒

This schema is a huge simplification of what a "real-world app" would use, but have just what we need to implement our system and to exemplify a few concepts.
We have the Users table, along with the Follows relationship table, that records the users that a user follows, as the name suggests, and the global Tweets table (another suggestive name here :P).
Any changes to the database are called migrations. We keep these changes into versioned files so that we can make use of all goods version control gives us: keep track of how the db schema changed over time, allowing us to rebuild our database from scratch, making clear the current state of our database and easier to undo things when we need to (rollbacks), etc.
These concepts were borrowed from Flyway, the tool we'll use to manage our migrations, and you can read more about them here, with illustrated examples and all.
Here's the SQL file exported from dbdiagram and that we'll use as our V1__Init.sql migration:
CREATE TABLE "users" (
"id" BIGSERIAL UNIQUE,
"username" varchar UNIQUE,
PRIMARY KEY ("id", "username")
);
CREATE TABLE "follows" (
"follower_id" bigint,
"followee_id" bigint,
PRIMARY KEY ("follower_id", "followee_id")
);
CREATE TABLE "tweets" (
"id" SERIAL PRIMARY KEY,
"sender_id" bigint,
"text" text,
"timestamp" timestamp
);
ALTER TABLE "follows" ADD FOREIGN KEY ("follower_id") REFERENCES "users" ("id");
ALTER TABLE "follows" ADD FOREIGN KEY ("followee_id") REFERENCES "users" ("id");
ALTER TABLE "tweets" ADD FOREIGN KEY ("sender_id") REFERENCES "users" ("id");We have the option to run Flyway from within our app container, but we won't do it. Instead, we'll run flyway from it's own container. We'll do this to avoid concurrency issues: imagine we have dozens of instances of our app starting up, each one running flyway to validate and update the migrations, feel free to imagine the chaos created in case of issues while migrating as well.
Doing so is simple and we'll do using the Flyway Docker image.
Place the migration file at postgres/migrations and add the migration container setup to the docker-compose.yml:
migration:
container_name: migration
image: 'flyway/flyway:6.0.2-alpine'
command: -url=jdbc:postgresql://postgres:5432/tweets -user=postgres -password=pass migrate
volumes:
- ./postgres/migrations:/flyway/sql:Z
depends_on:
postgres:
condition: service_healthyThen we can connect to the local postgres instance and check that the tables were created:
$ psql -h localhost -d tweets -U postgres
Password for user postgres:
psql (12.6, server 11.2)
Type "help" for help.
tweets=# \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------------+-------+----------
public | flyway_schema_history | table | postgres
public | follows | table | postgres
public | tweets | table | postgres
public | users | table | postgres
(4 rows)The Micronaut guide is very detailed and helped me a lot while developing this example API. It has lots of examples with good coverage for everyday use of the framework.
This layer will be in charge of creating an abstraction for manipulating the data at the database or any other persistence mechanism. We'll do that by creating some components:
- Models: that create an abstraction for the entities being manipulated and it's relationships. We'll use Hibernate to create these abstractions.
- Data Transfer Objects (DTOs): classes that encapsulate data that will transfer between layers (I know that's not the Martin Fowler's definition...)
- Data Access Objects (DAOs): these are abstractions to the persistence mechanism. This will expose data operations without exposing details of the database. So we'll be able to update and retrieve data easily. We'll use JPA to provide these operations.
Here, we used Lombok and Java Persistence annotations to create our Tweet model, with a default constructor, getters, setters and especifying the database schema, table and it's fields.
We also used the @EqualsAndHashCode with @EqualsAndHashCode.Exclude at the id to make our tests easier when comparing models, since the id field is generated automatically.
package com.georgeoliveira.tweets.common.tweets.models;
import java.sql.Timestamp;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.AccessLevel;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import lombok.Setter;
import lombok.experimental.FieldDefaults;
@Entity
@Table(schema = "public", name = "tweets")
@Getter
@Setter
@RequiredArgsConstructor
@FieldDefaults(level = AccessLevel.PRIVATE)
@EqualsAndHashCode
public class Tweet {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@EqualsAndHashCode.Exclude
Long id;
Long senderId;
String text;
Timestamp timestamp;
}The best resource about Hibernate available is this blog.
We'll use Lombok to create our Tweet DTO with a builder:
package com.georgeoliveira.tweets.common.tweets.dtos;
import java.time.LocalDateTime;
import lombok.Builder;
import lombok.Value;
@Value
@Builder(toBuilder = true)
public class TweetDto {
Long id;
Long senderId;
String text;
LocalDateTime timestamp;
}Mappers are components that make conversions between classes:
package com.georgeoliveira.tweets.common.tweets.mappers;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.models.Tweet;
import java.sql.Timestamp;
import java.time.ZoneOffset;
public class TweetMapper {
public static TweetDto fromModel(Tweet tweet) {
return TweetDto.builder()
.id(tweet.getId())
.senderId(tweet.getSenderId())
.text(tweet.getText())
.timestamp(tweet.getTimestamp().toInstant().atOffset(ZoneOffset.UTC).toLocalDateTime())
.build();
}
public static Tweet fromDto(TweetDto tweetDto) {
Tweet tweet = new Tweet();
tweet.setId(tweetDto.getId());
tweet.setSenderId(tweetDto.getSenderId());
tweet.setText(tweetDto.getText());
tweet.setTimestamp(Timestamp.from(tweetDto.getTimestamp().toInstant(ZoneOffset.UTC)));
return tweet;
}
}Here we'll use the JPA annotations and extend the JpaRepository interface for our model:
package com.georgeoliveira.tweets.common.tweets.dal.dao;
import com.georgeoliveira.tweets.common.tweets.models.Tweet;
import io.micronaut.data.annotation.Repository;
import io.micronaut.data.jpa.repository.JpaRepository;
@Repository
public interface TweetsDao extends JpaRepository<Tweet, Long> {}To add more database access abstractions we change this DAO file, for example: let's say we want to add a method to retrieve all tweets by a particular sender, we could add a method signature:
List<Tweet> findAllBySenderId(Long senderId);More details from possibilities available at Micronaut Data are described here
In our DAL abstraction, we provide a method to persist a tweet at our database.
package com.georgeoliveira.tweets.common.tweets.dal;
import com.georgeoliveira.tweets.common.tweets.dal.dao.TweetsDao;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.mappers.TweetMapper;
import com.georgeoliveira.tweets.common.tweets.models.Tweet;
import javax.inject.Inject;
import javax.inject.Singleton;
import javax.transaction.Transactional;
@Singleton
public class TweetsDal {
@Inject TweetsDao tweetsDao;
@Transactional
public TweetDto persistTweet(TweetDto tweetDto) {
Tweet tweet = TweetMapper.fromDto(tweetDto);
Tweet persistedTweet = tweetsDao.save(tweet);
return TweetMapper.fromModel(persistedTweet);
}
}Transactions ensures that our methods executions are atomic. The classic example is:
UserTransaction utx = entityManager.getTransaction();
try {
utx.begin();
businessLogic();
utx.commit();
} catch(Exception ex) {
utx.rollback();
throw ex;
}The begin() call starts a transaction, and everything fro now on is considered atomic. When the commit() happens, then the information is persisted and the transaction is finished. If any error happens inside businessLogic() , the catc() flow is triggered and then a rollback happens, ensuring nothing is persisted and so the transaction also finishes.
We used @Transactional so that we can benefit from the Micronaut's HibernateTransactionManager that handles transactions management for us.
Our Tweets Service instance uses the DAL to persist a tweet constructed using the data from the POST request body:
package com.georgeoliveira.tweets.api.services;
import com.georgeoliveira.tweets.api.dtos.PostTweetRequestDto;
import com.georgeoliveira.tweets.api.mappers.TweetRequestMapper;
import com.georgeoliveira.tweets.common.tweets.dal.TweetsDal;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import javax.inject.Inject;
import javax.inject.Singleton;
@Singleton
public class TweetsService {
@Inject TweetsDal tweetsDal;
public TweetDto publishTweet(PostTweetRequestDto request) {
TweetDto tweetDto = TweetRequestMapper.fromPostRequest(request);
TweetDto persistedTweetDto = tweetsDal.persistTweet(tweetDto);
return persistedTweetDto;
}
}This body has the format of:
package com.georgeoliveira.tweets.api.dtos;
import io.micronaut.core.annotation.Introspected;
import javax.validation.constraints.NotBlank;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Positive;
import lombok.Builder;
import lombok.Value;
@Value
@Builder(toBuilder = true)
@Introspected
public class PostTweetRequestDto {
@NotNull @NotBlank Long senderId;
@NotNull @NotBlank String text;
@NotNull @Positive Long timestamp;
}Again, we use Lombok to create a builder for this class along with some validation constraints for it's fields.
It's mapper is:
package com.georgeoliveira.tweets.api.mappers;
import com.georgeoliveira.tweets.api.dtos.PostTweetRequestDto;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
public class TweetRequestMapper {
public static TweetDto fromPostRequest(PostTweetRequestDto postTweetRequestDto) {
return TweetDto.builder()
.id(null)
.senderId(postTweetRequestDto.getSenderId())
.text(postTweetRequestDto.getText())
.timestamp(
LocalDateTime.from(
Instant.ofEpochMilli(postTweetRequestDto.getTimestamp()).atZone(ZoneOffset.UTC)))
.build();
}
}We use the @Controller annotation to create our Tweets Controller with our POST /tweets route. We also use the @Validated annotation to ensure constraints over fields are applied.
package com.georgeoliveira.tweets.api.controllers;
import com.georgeoliveira.tweets.api.dtos.PostTweetRequestDto;
import com.georgeoliveira.tweets.api.services.TweetsService;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import io.micronaut.http.HttpResponse;
import io.micronaut.http.annotation.Body;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Post;
import io.micronaut.validation.Validated;
import java.util.Objects;
import javax.inject.Inject;
import javax.validation.Valid;
@Validated
@Controller("/tweets")
public class TweetsController {
@Inject TweetsService tweetsService;
@Post
public HttpResponse<Long> postTweet(@Valid @Body PostTweetRequestDto request) {
TweetDto tweet = tweetsService.publishTweet(request);
if (Objects.nonNull(tweet)) {
return HttpResponse.created(tweet.getId());
}
return HttpResponse.notFound();
}
}This controller uses our Service to publish the tweet.
We can build the project by running:
$ ./gradlew build -x testThen, run it by doing:
$ java -jar build/libs/tweets-all.jarAnd, finally, call the API by doing:
$ curl -L -X POST 'http://localhost:8080/tweets' -H 'Content-Type: application/json' --data-raw '{
"sender_id": 12356,
"text": "xalala",
"timestamp": 1619626150979
}'Please note that, as the Tweets table references the Users table, the senderId must be a valid user, so, first we must populate the Users table manually:
$ psql -h localhost -d tweets -U postgres
Password for user postgres:
psql (12.6, server 11.2)
Type "help" for help.
tweets=# INSERT INTO users(username) VALUES ('my_username');
INSERT 0 1
tweets=# SELECT id, username FROM users WHERE username = 'my_username';
id | username
----+-------------
1 | my_username
(1 row)Now that we are able to handle requests to publish tweets, how do we trigger the tweet event to be published to Kafka?
We'll define a generic "event" schema that will be used by Debezium to publish the events that will trigger our system's flows to Kafka. This schema will be defined using Apache Avro:
protocols/avro/events/key.avro
{
"type": "record",
"name": "Key",
"namespace": "com.georgeoliveira.events",
"fields": [
{
"name": "aggregate_id",
"type": [
"null",
"string"
],
"default": null
}
]
}protocols/avro/events/value.avro
{
"type": "record",
"name": "Value",
"namespace": "com.georgeoliveira.events",
"fields": [
{
"name": "event_id",
"doc": "A valid V4 UUID. Each event has a unique id.",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "aggregate_id",
"doc": "The id of the whole aggregate that had any of the nested entities or the root entity edited.",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "type",
"doc": "The type of the event, eg. \"create\" or \"update\".",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "aggregate",
"doc": "The whole aggregate that had any of the nested entities or the root entity edited.",
"type": [
"null",
"string"
],
"default": null
}
]
}The fields comments give you an explanation of the utility and importance of each field, but let's expand a discussion on the aggregate and type fields.
The aggregate will contain the payload with the relevant data needed to process the event. So, for example, if the we're developing a chat app and the event is "new message sent", the aggregate could be a JSON like:
{
"sender_id": ...,
"recipient_id": ...,
"message": ....
}Our aggregates for the tweets events will have the tweet payload:
{
"id": ...,
"sender_id": ...,
"text": ...,
"timestamp": ...
}We use the type field to store the type of event that occurred so that different consumers can decide how to process it, e.g., the post_tweet event may trigger the delivery processing, but the edit_tweet may not.
In order to create a schema for the aggregate payload, we define a protocol buffer message type to represent a Tweet:
protocols/proto/tweets/tweet.proto
syntax = "proto3";
package com.georgeoliveira.tweets.proto;
option java_outer_classname = "TweetProtobuf";
message Tweet {
int64 id = 1;
int64 sender_id = 2;
string text = 3;
int64 timestamp = 4;
}So whenever a event is published, we ensure that the aggregate field has the schema that the consumers expect. Also, these schemas can be versioned, so we can keep track of it's evolution.
The protocols folder can be a git repository that is included in our system as submodule, this way it's development can continue independently of the app and other related components can include them too.
We have defined the event schema and protobuffers, and all, but for now you must be wondering "how the hell do we actually publish the event????". Well, here is where the Outbox Pattern comes in.
In this pattern, for each entity whose changes over it triggers any behaviour in our system, we have a database table called "The Outbox Table" of that entity. In our example case, for every new tweet published, we want to trigger the delivery flow, so that we'll need a "Tweet Outbox Table" for the entity "Tweet" from the table tweets.
This table must be generic so that it has the same schema as the Value avro schema that we defined earlier, as shown in our second migration V2__AddTweetsOutboxTable.sql:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE tweets_outbox (
event_id UUID DEFAULT uuid_generate_v4(),
aggregate_id TEXT,
type TEXT,
aggregate JSONB,
created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW()
);Along with the outboxes, we'll need a Change Data Capture (CDC) app to monitor changes on the outbox tables and publish new entries as messages to our broker. This way, whenever we want to publish an event, we simply insert it at the outbox table.
The CDC app we'll use is Debezium. We'll use the Debezium PostgreSQL Connector as a Kafka Connecttor, so that the messages are published to Kafka. To do, so we need to:
- Configure our PostgreSQL instance to allow connections from Debezium.
- Setup the Kafka Connector with the Debezium PostgreSQL Connector plugin
First thing we need to to is to enable Logical Decoding at our PG instance:
Logical decoding is the process of extracting all persistent changes to a database's tables into a coherent, easy to understand format which can be interpreted without detailed knowledge of the database's internal state.
We do this by installing this plugin called wal2json, which is done by following it's README's instructions, that describes how to enable logical replication.
It's important to know these steps in case you need to perform these steps in a managed or VM instance at yout job or whatever.
For the purposes of this article, we'll use a Postgres Docker image provided by Debezium that already comes with these instalations and configurations: https://github.com/debezium/docker-images/tree/master/postgres/12-alpine .
This image repository is also a good summary of all configurations needed.
For the purposes of this article, we'll use the Debezium Connect Docker image https://github.com/debezium/docker-images/tree/master/connect/1.5:
connect:
image: 'debezium/connect:1.5'
ports:
- "8083:8083"
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=connect_configs
- OFFSET_STORAGE_TOPIC=connect_offsets
- STATUS_STORAGE_TOPIC=connect_statuses
depends_on:
- kafka
- postgresFor more detailes, please refer to this article.
Next, we need to setup the connector that will listen to changes at the Tweets Table. For that, we'll use the Debezium's REST API:
curl -d @"connector-config.json" \
-H "Content-Type: application/json" \
-X POST http://connect:8083/connectorswhere connector-config.json is:
{
"name": "tweets_outbox_connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"slot.name": "tweets_outbox_connector",
"transforms": "unwrap,ValueToKey,SetKeySchema,SetValueSchema",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.ValueToKey.type": "org.apache.kafka.connect.transforms.ValueToKey",
"transforms.ValueToKey.fields": "aggregate_id",
"transforms.SetValueSchema.type": "org.apache.kafka.connect.transforms.SetSchemaMetadata$Value",
"transforms.SetValueSchema.schema.name": "com.georgeoliveira.events.Value",
"transforms.SetKeySchema.type": "org.apache.kafka.connect.transforms.SetSchemaMetadata$Key",
"transforms.SetKeySchema.schema.name": "com.georgeoliveira.events.Key",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081/",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081/",
"plugin.name": "wal2json_rds",
"database.server.name": "postgres",
"database.dbname": "tweets",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "pass",
"schema.include.list": "public",
"table.include.list": "public.tweets_outbox"
}
}And we can see the connector status by running
$ curl http://connect:8083/connectors/tweets_outbox_connector/statusIt's important to note that if everything goes wrong with the postgres or Kafka that Debezium is connected to, the connector will stop working and will not return to the "running" state on it's own. We'll need to manually recreate it.
To delete a connector, besides calling the DELETE method at Debezium's API, by doing:
curl -X DELETE http://debezium.debezium/connectors/tweets_outbox_connector -vwe need to delete the postgres replication slots:
select pg_drop_replication_slot('tweets_outbox_connector');To test that outbox events are being published, let's insert some data into the outbox table and try to consume from kafka:
$ psql -h localhost -d tweets -U postgres
Password for user postgres:
psql (12.6)
Type "help" for help.
tweets=# insert into tweets_outbox(aggregate_id, type, aggregate) values ('1', 'test', '{"test":"this is a test"}');
INSERT 0 1
tweets=#Using kafkacat to consume from the Kafka topic postgres.public.tweets_outbox, we get something like:
$ kafkacat -C -b kafka:9092 -t postgres.public.tweets_outbox
H71dbed94-c3db-410e-b7a0-7b0a120e8617test4{"test": "this is a test"}����߹�
% Reached end of topic postgres.public.tweets_outbox [0] at offset 1Whenever a tweet is posted, we publish this event by inserting the related data at the outbox table.
We can also publish this event by using a database trigger. In our tweets example, which is very simple, it works nicelly, but for more complex schemas and it's relationships, things get more complicated and setting up these trigger rules can be a headache. It's simpler, then, to just insert at the outbox table whenever we want to, using it's own DAL.
This DAL structure is very similar to the one we already defined for Tweets.
Tweet Outbox Model
package com.georgeoliveira.tweets.common.tweets.outbox.models;
import com.vladmihalcea.hibernate.type.json.JsonBinaryType;
import java.sql.Timestamp;
import java.util.UUID;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.AccessLevel;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import lombok.Setter;
import lombok.experimental.FieldDefaults;
import org.hibernate.annotations.Type;
import org.hibernate.annotations.TypeDef;
import org.hibernate.annotations.TypeDefs;
@Entity
@Table(schema = "public", name = "tweets_outbox")
@Getter
@Setter
@RequiredArgsConstructor
@FieldDefaults(level = AccessLevel.PRIVATE)
@EqualsAndHashCode
@TypeDefs({@TypeDef(name = "jsonb", typeClass = JsonBinaryType.class)})
public class TweetOutbox {
@Id
@Column(name = "event_id")
@GeneratedValue(strategy = GenerationType.AUTO)
@EqualsAndHashCode.Exclude
UUID eventId;
@Column(name = "aggregate_id")
String aggregateId;
@Column(name = "type")
String type;
@Type(type = "jsonb")
@Column(name = "aggregate", columnDefinition = "jsonb")
String aggregate;
@Column(name = "created_at", insertable = false)
@EqualsAndHashCode.Exclude
Timestamp createdAt;
}And the mapper:
package com.georgeoliveira.tweets.common.tweets.outbox.mappers;
import com.georgeoliveira.campaigns.proto.TweetProtobuf;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.outbox.dtos.EventType;
import com.georgeoliveira.tweets.common.tweets.outbox.models.TweetOutbox;
import com.googlecode.protobuf.format.JsonFormat;
import java.time.ZoneOffset;
public class TweetOutboxMapper {
public static TweetOutbox toOutboxModel(TweetDto tweetDto, EventType eventType) {
TweetProtobuf.Tweet tweetProto = toProto(tweetDto);
String aggregate = toAggregate(tweetProto);
TweetOutbox tweetOutbox = new TweetOutbox();
tweetOutbox.setType(eventType.toString());
tweetOutbox.setAggregate(aggregate);
tweetOutbox.setAggregateId(String.valueOf(tweetDto.getId()));
return tweetOutbox;
}
private static TweetProtobuf.Tweet toProto(TweetDto tweetDto) {
return TweetProtobuf.Tweet.newBuilder()
.setId(tweetDto.getId())
.setSenderId(tweetDto.getSenderId())
.setText(tweetDto.getText())
.setTimestamp(tweetDto.getTimestamp().toInstant(ZoneOffset.UTC).toEpochMilli())
.build();
}
private static String toAggregate(TweetProtobuf.Tweet tweetProto) {
JsonFormat jsonFormat = new JsonFormat();
return jsonFormat.printToString(tweetProto);
}
}There are some new steps, because we're using the protobuffers we defined earlier. First, we map our tweet dto to a protobuffer, then we map this protobuffer to a json string and then finally set it as the aggregate field of the outbox.
Tweet Outbox DAO
package com.georgeoliveira.tweets.common.tweets.outbox.dal.dao;
import com.georgeoliveira.tweets.common.tweets.outbox.models.TweetOutbox;
import io.micronaut.data.annotation.Repository;
import io.micronaut.data.jpa.repository.JpaRepository;
import java.util.UUID;
@Repository
public interface TweetsOutboxDao extends JpaRepository<TweetOutbox, UUID> {}Tweet Outbox DAL
package com.georgeoliveira.tweets.common.tweets.outbox.dal;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.outbox.dal.dao.TweetsOutboxDao;
import com.georgeoliveira.tweets.common.tweets.outbox.dtos.EventType;
import com.georgeoliveira.tweets.common.tweets.outbox.mappers.TweetOutboxMapper;
import com.georgeoliveira.tweets.common.tweets.outbox.models.TweetOutbox;
import javax.inject.Inject;
import javax.inject.Singleton;
@Singleton
public class TweetsOutboxDal {
@Inject TweetsOutboxDao tweetsOutboxDao;
public void sendToOutbox(TweetDto tweetDto, EventType eventType) {
TweetOutbox tweetOutbox = TweetOutboxMapper.toOutboxModel(tweetDto, eventType);
tweetsOutboxDao.save(tweetOutbox);
}
}Service
We need to modify our Tweets Service to send the tweet events to outbox whenever a tweet is published:
package com.georgeoliveira.tweets.api.services;
import com.georgeoliveira.tweets.api.dtos.PostTweetRequestDto;
import com.georgeoliveira.tweets.api.mappers.TweetRequestMapper;
import com.georgeoliveira.tweets.common.tweets.dal.TweetsDal;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.outbox.dal.TweetsOutboxDal;
import com.georgeoliveira.tweets.common.tweets.outbox.dtos.EventType;
import javax.inject.Inject;
import javax.inject.Singleton;
@Singleton
public class TweetsService {
@Inject TweetsDal tweetsDal;
@Inject
TweetsOutboxDal tweetsOutboxDal;
public TweetDto publishTweet(PostTweetRequestDto request) {
TweetDto tweetDto = TweetRequestMapper.fromPostRequest(request);
TweetDto persistedTweetDto = tweetsDal.persistTweet(tweetDto);
tweetsOutboxDal.sendToOutbox(persistedTweetDto, EventType.PUBLISH_TWEET);
return persistedTweetDto;
}
}Now that we are able to publish tweets and have it to trigger a tweet event to be published to kafka, we'll implement the event-driven part of our architecture, the one that receives these events and then performs an action.
In our case, we'll:
- consume tweet events from kafka
- add these events to the author's followers timelines
To do that, we'll need:
- a kafka consumer for tweet events
- an abstraction for timelines
- a way to persist the timelines
We could use our postgres instance to persist the timelines, but we're interested in some sort of cache from where we can retrieve these data rapidly, which seems to be a good fit for Redis.
We'll implement this in two parts:
- The consumer, with two components:
- a listener: that will be connected to Kafka and will receive the events from a topic
- a processor: that will process the event received at the listener
- A DAL for the timelines, that will be an abstraction for our Redis instance. This DAL will have the same components from other DALs we already created for this project.
This component is an abstraction for Redis, and we'll use it to persist the user's timelines.
In order to do this, we need to define a schema for how we'll store the data into Redis.
For the key, we'll simply use the user_id.
For the value part, we'll use a byte array representation of a protobuffer:
syntax = "proto3";
package com.georgeoliveira.tweets.proto;
option java_outer_classname = "TimelineProtobuf";
import "tweets/tweet.proto";
message Timeline {
int64 user_id = 1;
repeated com.georgeoliveira.tweets.proto.Tweet tweets = 2;
}We'll use Lombok to create our Timeline DTO with a builder:
package com.georgeoliveira.tweets.common.timelines.dtos;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import java.util.List;
import lombok.Builder;
import lombok.Value;
@Builder(toBuilder = true)
@Value
public class TimelineDto {
Long userId;
List<TweetDto> tweetsList;
}Here is our mapper that creates TimelineDto from a list of TweetDto and maps TimelineDto to byte arrays.
package com.georgeoliveira.tweets.common.timelines.mappers;
import com.georgeoliveira.tweets.common.timelines.dtos.TimelineDto;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.mappers.TweetMapper;
import com.georgeoliveira.tweets.proto.TimelineProtobuf;
import java.util.List;
import java.util.stream.Collectors;
import org.apache.commons.lang3.tuple.Pair;
public class TimelineMapper {
public static TimelineDto fromList(Long userId, List<TweetDto> tweetsList) {
return TimelineDto.builder().userId(userId).tweetsList(tweetsList).build();
}
public static Pair<Long, byte[]> toUserIdTimelineByteArrayPair(TimelineDto timelineDto) {
return Pair.of(timelineDto.getUserId(), toTimelineByteArray(timelineDto));
}
private static byte[] toTimelineByteArray(TimelineDto timelineDto) {
return toProto(timelineDto).toByteArray();
}
private static TimelineProtobuf.Timeline toProto(TimelineDto timelineDto) {
return TimelineProtobuf.Timeline.newBuilder()
.setUserId(timelineDto.getUserId())
.addAllTweets(
timelineDto
.getTweetsList()
.stream()
.map(tweetDto -> TweetMapper.toProto(tweetDto))
.collect(Collectors.toList()))
.build();
}
}To access Redis, we'll use the Lettuce Client.
First, we'll define a [TimelineCommands interface](https://lettuce.io/core/release/reference/index.html#redis-command-interfaces), that defines the methods that we'll use to interact with Redis:
package com.georgeoliveira.tweets.common.timelines.dal.dao;
import io.lettuce.core.dynamic.Commands;
import io.lettuce.core.dynamic.annotation.Command;
public interface TimelineCommands extends Commands {
@Command("SET")
void set(String userId, byte[] timelineByteArray);
@Command("GET")
byte[] get(String userId);
}Then we'll define a Factory that will set up a Singleton with a instance of that interface that is connected to our Redis:
package com.georgeoliveira.tweets.common.timelines.dal.dao.factories;
import com.georgeoliveira.tweets.common.timelines.dal.dao.TimelineCommands;
import io.lettuce.core.RedisClient;
import io.lettuce.core.dynamic.RedisCommandFactory;
import io.micronaut.context.annotation.Factory;
import io.micronaut.context.annotation.Value;
import javax.inject.Singleton;
@Factory
public class TimelineCommandsFactory {
@Value("${redis.host}")
private String REDIS_HOST;
@Singleton
TimelineCommands timelineCommands() {
RedisClient redisClient = RedisClient.create(REDIS_HOST);
RedisCommandFactory commandFactory = new RedisCommandFactory(redisClient.connect());
return commandFactory.getCommands(TimelineCommands.class);
}
}Finally, our DAL that wraps the other components is:
package com.georgeoliveira.tweets.common.timelines.dal;
import com.georgeoliveira.tweets.common.timelines.dal.dao.TimelineCommands;
import com.georgeoliveira.tweets.common.timelines.dtos.TimelineDto;
import com.georgeoliveira.tweets.common.timelines.mappers.TimelineMapper;
import javax.inject.Inject;
import javax.inject.Singleton;
import org.apache.commons.lang3.tuple.Pair;
@Singleton
public class TimelinesDal {
@Inject TimelineCommands timelineCommandsDao;
public void persistTimeline(TimelineDto timelineDto) {
Pair<Long, byte[]> userIdTimelinePair =
TimelineMapper.toUserIdTimelineByteArrayPair(timelineDto);
timelineCommandsDao.set(
String.valueOf(userIdTimelinePair.getLeft()), userIdTimelinePair.getRight());
}
}The processor is the component that will implement the flow for the fan-out approach described at the beginning of this article:
Post a tweet: find all people that follows the tweet author and insert the new tweet at their home timeline caches.
Let's break down this flow into:
- find all people that follows the tweet author
- insert the new tweet at their timelines
For the first part, we'll need an abstraction for the User table, so that it can retrieve user followers:
Here's our User model:
package com.georgeoliveira.tweets.common.users.models;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import lombok.AccessLevel;
import lombok.EqualsAndHashCode;
import lombok.Getter;
import lombok.RequiredArgsConstructor;
import lombok.Setter;
import lombok.experimental.FieldDefaults;
@Entity
@Table(schema = "public", name = "users")
@Getter
@Setter
@RequiredArgsConstructor
@FieldDefaults(level = AccessLevel.PRIVATE)
@EqualsAndHashCode
public class User {
@Id @EqualsAndHashCode.Exclude Long id;
String username;
@OneToMany(fetch = FetchType.EAGER)
@JoinTable(
name = "follows",
joinColumns = {@JoinColumn(name = "followee_id")},
inverseJoinColumns = {@JoinColumn(name = "follower_id")})
List<User> followers = new ArrayList<>();
}Note the followers field that maps the follows association table and will allow us to retrieve a user's followers. Also note that we only mapped what is useful to this very specific flow that we are building, and so many features required to model a "real user" were left behind.
Here's is our DTO for users:
package com.georgeoliveira.tweets.common.users.dtos;
import java.util.List;
import lombok.Builder;
import lombok.Value;
@Value
@Builder(toBuilder = true)
public class UserDto {
Long id;
String username;
List<UserDto> followers;
}And the mapper:
package com.georgeoliveira.tweets.common.users.mappers;
import com.georgeoliveira.tweets.common.users.dtos.UserDto;
import com.georgeoliveira.tweets.common.users.models.User;
import java.util.stream.Collectors;
public class UserMapper {
public static UserDto fromModel(User user) {
return UserDto.builder()
.id(user.getId())
.username(user.getUsername())
.followers(
user.getFollowers().stream().map(UserMapper::fromModel).collect(Collectors.toList()))
.build();
}
}And the DAO:
package com.georgeoliveira.tweets.common.users.dal.dao;
import com.georgeoliveira.tweets.common.users.models.User;
import io.micronaut.data.annotation.Repository;
import io.micronaut.data.jpa.repository.JpaRepository;
@Repository
public interface UsersDao extends JpaRepository<User, Long> {}And, finally, the DAL:
package com.georgeoliveira.tweets.common.users.dal;
import com.georgeoliveira.tweets.common.users.dal.dao.UsersDao;
import com.georgeoliveira.tweets.common.users.dtos.UserDto;
import com.georgeoliveira.tweets.common.users.mappers.UserMapper;
import java.util.Collections;
import java.util.List;
import javax.inject.Inject;
import javax.inject.Singleton;
@Singleton
public class UsersDal {
@Inject UsersDao usersDao;
public List<UserDto> getUserFollowers(Long userId) {
return usersDao
.findById(userId)
.map(UserMapper::fromModel)
.map(UserDto::getFollowers)
.orElse(Collections.emptyList());
}
}For the second part of the flow, we already defined an DAL that persists timelines to the cache, but we still need to implement a way to retrieve the tweets from the timeline of a particular user.
To do this, we'll modify our TweetsDal component by adding the methodgetTimelineForUser:
public List<TweetDto> getTimelineForUser(Long userId, Long timelineSize) {
return tweetsDao
.findTimelineTweetsByUserId(userId, timelineSize)
.stream()
.map(TweetMapper::fromModel)
.collect(Collectors.toList());
}and the DAO with a native query that retrieves the tweets from the timeline:
@Query(
value =
"SELECT * FROM tweets t JOIN follows f ON f.followee_id = t.sender_id WHERE f.follower_id = :userId ORDER BY timestamp DESC LIMIT :limit",
nativeQuery = true)
List<Tweet> findTimelineTweetsByUserId(Long userId, Long limit);With these methods, we're allowed to retrieve the tweets list for a user's timeline and build the TimelineDto using the mapper we defined earlier.
Finally, the processor is:
package com.georgeoliveira.tweets.worker.processors;
import com.georgeoliveira.tweets.common.timelines.dal.TimelinesDal;
import com.georgeoliveira.tweets.common.timelines.dtos.TimelineDto;
import com.georgeoliveira.tweets.common.timelines.mappers.TimelineMapper;
import com.georgeoliveira.tweets.common.tweets.dal.TweetsDal;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.users.dal.UsersDal;
import com.georgeoliveira.tweets.common.users.dtos.UserDto;
import java.util.List;
import java.util.function.Consumer;
import java.util.stream.Collectors;
import javax.inject.Inject;
import javax.inject.Singleton;
@Singleton
public class TweetsProcessor implements Consumer<TweetDto> {
@Inject TimelinesDal timelinesDal;
@Inject TweetsDal tweetsDal;
@Inject UsersDal usersDal;
@Override
public void accept(TweetDto tweetDto) {
List<UserDto> authorFollowers = usersDal.getUserFollowers(tweetDto.getSenderId());
List<TimelineDto> timelineDtos =
authorFollowers
.stream()
.map(UserDto::getId)
.map(
userId ->
TimelineMapper.fromList(userId, tweetsDal.getTimelineForUser(userId, 100L)))
.collect(Collectors.toList());
timelineDtos.forEach(timelineDto -> timelinesDal.persistTimeline(timelineDto));
}
}This component listens to tweet events and, for each one, triggers the processor flow:
package com.georgeoliveira.tweets.worker.listeners;
import com.georgeoliveira.events.Key;
import com.georgeoliveira.events.Value;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import com.georgeoliveira.tweets.common.tweets.mappers.TweetMapper;
import com.georgeoliveira.tweets.worker.processors.TweetsProcessor;
import io.micronaut.configuration.kafka.annotation.KafkaListener;
import io.micronaut.configuration.kafka.annotation.OffsetReset;
import io.micronaut.configuration.kafka.annotation.Topic;
import java.io.IOException;
import javax.inject.Inject;
import org.apache.kafka.clients.consumer.ConsumerRecord;
@KafkaListener(offsetReset = OffsetReset.EARLIEST)
public class TweetsListener {
@Inject TweetsProcessor tweetsProcessor;
@Topic("${topics.tweets}")
void listen(ConsumerRecord<Key, Value> event) throws IOException {
TweetDto tweetDto = TweetMapper.fromRecord(event);
tweetsProcessor.accept(tweetDto);
}
}Note the offsetReset strategy defined as OffsetReset.EARLIEST which makes the listener that a consumer will start reading the earliest available records for the topic. More details on offset management are available here.
Let's define a route that will allow us to retrieve timeline tweets, as we said earlier at the second point of the fan-out approach:
Home timeline: just read from the cache.
🤷
To "just read from the cache", a few components are required. The structure is the same we used when building the tweets API.
We first need to add a fromByteArray method to the TimelineMapper:
public static Optional<TimelineDto> fromByteArray(byte[] timelineByteArray) {
try {
TimelineProtobuf.Timeline timelineProto =
TimelineProtobuf.Timeline.parseFrom(timelineByteArray);
TimelineDto timelineDto = fromProto(timelineProto);
return Optional.of(timelineDto);
} catch (InvalidProtocolBufferException | NullPointerException e) {
return Optional.empty();
}
}This method will be used by the new method that we'll add to the TimelinesDal:
public Optional<TimelineDto> getUserTimeline(Long userId) {
byte[] timelineByteArray = timelineCommandsDao.get(String.valueOf(userId));
return TimelineMapper.fromByteArray(timelineByteArray);
}Finally, this new method will be used by the service:
package com.georgeoliveira.tweets.api.services;
import com.georgeoliveira.tweets.common.timelines.dal.TimelinesDal;
import com.georgeoliveira.tweets.common.timelines.dtos.TimelineDto;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import java.util.Collections;
import java.util.List;
import javax.inject.Inject;
import javax.inject.Singleton;
@Singleton
public class TimelinesService {
@Inject TimelinesDal timelinesDal;
public List<TweetDto> getUserTimelineTweets(Long userId) {
return timelinesDal
.getUserTimeline(userId)
.map(TimelineDto::getTweetsList)
.orElse(Collections.emptyList());
}
}The controller uses the service to retrieve a list of tweets of a timeline from the requested user:
package com.georgeoliveira.tweets.api.controllers;
import com.georgeoliveira.tweets.api.services.TimelinesService;
import com.georgeoliveira.tweets.common.tweets.dtos.TweetDto;
import io.micronaut.http.HttpResponse;
import io.micronaut.http.HttpStatus;
import io.micronaut.http.annotation.Controller;
import io.micronaut.http.annotation.Get;
import io.micronaut.http.annotation.PathVariable;
import java.util.List;
import javax.inject.Inject;
@Controller("/timelines")
public class TimelinesController {
@Inject TimelinesService timelinesService;
@Get("/{userId}")
HttpResponse<List<TweetDto>> getUserTimeline(@PathVariable Long userId) {
List<TweetDto> tweetDtoList = timelinesService.getUserTimelineTweets(userId);
if (tweetDtoList.isEmpty()) {
return HttpResponse.noContent();
}
return HttpResponse.status(HttpStatus.FOUND).body(tweetDtoList);
}
}Let's see it working by building the project:
$ ./gradlew build -x testThen running it:
$ java -jar build/libs/tweets-all.jarThen setting up another user to follow the one we created earlier:
tweets=# insert into users(username) values('cool_user');
INSERT 0 1
tweets=# insert into follows(follower_id, followee_id) values(2, 1);
INSERT 0 1Then publishing a tweet from user 1:
$ curl -L -X POST 'http://localhost:8080/tweets' -H 'Content-Type: application/json' --data-raw '{
"sender_id": 1,
"text": "my new tweet",
"timestamp": 1619626150979
}And finally retrieving the timeline for user 2:
$ curl http://localhost:8080/timelines/2
[{"id":2,"text":"my new tweet","timestamp":[2021,4,28,16,9,10,979000000],"senderId":1}]We just created a event-driven app using Micronaut, Kafka and Debezium using many patterns applied in "real-world" applications.
We also saw many of the complexities added to our project because we chose to use Kafka as a broker. For smaller applications, that may be ok, but for "greater" and more complex ones, might be better to consider creating an event store of your own.
33