
18
What is Data Wrangling? Definition, Benefits and data wrangling operations.
Data wrangling, also known as data munging and data cleaning enables businesses tackle complex data with less time, make concrete and timely solutions and also produce more accurate results.
This article provides you with a detailed understanding of;
- What is data wrangling?
- Benefits of data wrangling.
- Data wrangling operations.
Data wrangling is the process of cleaning, organizing and transforming raw data into a desired format to make it appropriate and valuable for various purposes.
- Data wrangling acts as preparation stage for data mining mining process which involves data gathering.
- Data wrangling improves usability by converting it into compatible format.
- Enables users process large volumes of data easily.
- Enables users cleanse data from noise, flawed and missing elements.
- Helps business users make timely and concrete decisions.
1.Data manipulation.
Includes sorting, merging, grouping, and altering the data.
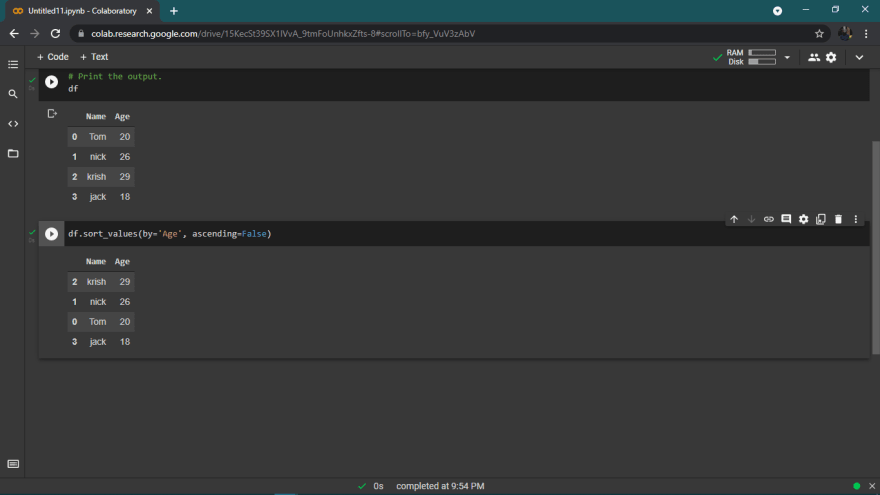
Sorts a dataframe in ascending (default) or descending order.
Uses sort_values function.
It uses quicksort by default for sorting and can be replaced with mergesort or heapsort using kind property.
Example.
Sorting a column in a dataframe in descending order as shown;
Merge function is used to combine two dataframes.
concat function combines two dataframes into a new one.
For example when we have two dataframes df1 and df2 we can concatenate them into one dataframe as follows;
p = [df1, df2]
result = pd.concat(p)
display(result)Grouping is used to aggregate the data into different categories.
A groupby operation involves combining of splitting the object, applying a function, and combining the results.
Read more about groupby()
2.Data Filtration.
Data Filtration is the process of choosing a smaller part of your data set and using that subset for viewing or analysis.
Given a dataset with several columns, you can choose columns that are useful by filtering the column names as shown;
result=df.filter(items=['Name', 'Course'])
result3.Dealing with missing values.
On my previous article, I wrote about ways to handle missing values in a dataset.
Handling missing values in python
4.Encoding data.
Not all datasets have numeric data and since most machine learning models accept numerical values, encoding categorical variables is an important operation in data wrangling.
Categorical variables are usually represented as strings or categories and are finite in number.
There are many ways of encoding categorical data. In this article we are going to look at label encoding technique.
Example.

From the above code, ' Gender ' column has categorical variables . Using label encoder each label is converted into an integer value.
5.Normalization.
A dataset may contain data with multiple features and each has a different unit of measurement. Normalization involves converting all possible features to the same standard scale.
Min-Max scaling is a commonly used technique in normalizing the data where the data is scaled to a fixed range - usually 0 to 1.
18