
31
How to Build a Predictive Machine Learning Site With React and Python (Part One: Model Development)
What we’ll be building.

We will be building a machine learning model that will predict whether a candidate will or will not be hired based on his or her credentials. This is part one out of a three-part series we will be developing. This part is only concerned with developing the machine learning model.
Prediction algorithms have evolved into a profitable source of solutions to our modern-day challenges as a result of thorough development processes, phases, and time.
These machine learning algorithms have been a tremendous boost in dealing with various challenges in our timeline. The human resources (HR) department inside organizations and businesses definitely will appreciate these improvements. With a machine learning model trained to identify worthy candidates for a job, a huge chunk of errors and losses can be avoided by an organization.
Machine learning prediction algorithms have come to stay and with more data, algorithms, and strategies being developed and refined I believe the future of business is a lot brighter.
To properly digest this tutorial, a good understanding of the following tools is required.
- Python
- Anaconda

Firstly, let's discuss what machine learning is. To simply state, machine learning is a sub-field in the area of artificial intelligence saddled with the responsibility of making a machine intelligent through training on datasets.
Secondly, an algorithm is a step-by-step computational instruction designed to solve a problem. This procedure is based upon some mathematical formulas and equations. These mathematical-based algorithms are geared to learn patterns and statistics from a well-defined dataset.
Lastly, prediction is the ability to forecast outcomes. It's kind of what a prophet will do, however, while a prophet predicts by inspirations, a machine learning algorithm predicts by historic data.

To build a machine learning model, a machine learning algorithm must be used to learn the statistics and patterns buried within the dataset.
Choosing a Development Environment
To proceed with building a machine learning model, the appropriate development environment must be put in place. Like before the building of a house, a good environment that will allow your machine learning code to run is required.
Choosing a machine learning development environment is predicated on your familiarity with a machine learning programing language. The two most popular programming languages for doing this is Python and R.
For this article, we'll be using the Python programing language, however, choosing a programing language alone is not enough, a development environment is also needed for this task. Anaconda does this very well. Anaconda is a data science and machine learning development package. It comes shipped with all the necessary libraries, programs, and configurations that will get you developing your model in a few minutes.
For installation guidance, visit their website and documentation page, or you can visit my Git Repo for the installation procedure.
To setup the environment use the following steps:
1. Head to [Anaconda](https://www.anaconda.com/products/individual) Site
2. On the page download Anaconda for your operating system.
3. Install the Anaconda package to your computer.
4. Visit [https://downgit.github.io/](https://downgit.github.io/).
5. Paste `https://github.com/Daltonic/predictive/tree/main/model` in the field thereon and click on the download button.
6. Unzip **model.zip** and place contents in a unique folder. You should have something like this.You should have a structure such as the one in the image below.

Next, Open Anaconda Navigator and lunch Spyder from the options.

You should have a structure such as the one in the image below.

Good, let’s proceed to import the libraries we will need.
Importing Libraries
There are different kinds of Python libraries available on the web and each has its use and area of applicability. For what we're building, we will just need three libraries namely Pandas, Numpy, and Scikit-learn.
# Importing Libraries
import pandas as pd
import numpy as npNow, create a folder called “machine-learning” and within it create another folder called “predictive” and save the code on the Spyder Editor in the folder you last created (predictive).
The rest of the libraries we will be using will be imported as we go. Let’s proceed to import the dataset for this model.
Copy the file named hireable.csv within the model.zip file to the folder called “predictive”. See the image below for guidance.

Once you have it in the folder named predictive, proceed by pasting the code snippet below in the opened Spyder Editor.
# Importing Dataset
dataset = pd.read_csv('hirable.csv')Here we used the Pandas library to read our CSV file into the program. By checking the variable explorer, here is how our dataset currently looks.

We don’t need all the columns, we only need are the following columns.
- gender
- degree_p
- mba_p
- workex
- etest_p
- status
We will proceed by doing some clean-up on the dataset.
Cleaning up the Dataset
Paste the code snippet below in your Spyder code editor to have your data cleaned up.
# Cleaning up dataset
dataset = dataset.drop([
"sl_no",
"ssc_p",
"ssc_b",
"hsc_p",
"hsc_b",
"hsc_s",
"specialisation",
"salary",
"degree_t"
], axis=1)
dataset = dataset.rename(columns = {'degree_p': 'bsc', 'mba_p': 'msc'})
dataset['gender'] = dataset.gender.replace(['M', 'F'], [1, 2])
dataset['workex'] = dataset.workex.replace(['Yes', 'No'], [1, 0])
dataset['status'] = dataset.status.replace(['Placed', 'Not Placed'], [1, 0])The above codes will drop most of the unnecessary columns, rename some hard-to-read columns and apply the suiting values to each row of the column.
The BSc and MSc scores are not in the format required for this model. We want to use CGPA systems and not percentages for those two columns. Let’s create a function to downscale these numbers to the appropriate values using the snippet below.
# Downscalling Method For BSc & MSc grades
def downscale(score):
return score/10/2
degrees = ['bsc', 'msc']
for col in degrees:
dataset[col] = downscale(dataset[col])Great work, now let’s proceed to separate the dataset into dependent and independent variables.
Separating Dataset into variables
This is a crucial step in developing a predictive machine learning model. We want to see how a, b, c, d can tell us about z. The objective in separating the dataset into X(n…) and Y variables is to see the relationship and how X(n…) affects the outcome of Y.
While X is the independent variable containing one or many columns (n…) of data, Y is an independent variable and it contains one column which is the outcome.
The above explanation can be implemented in Python using the Pandas package as seen in the code snippet below.
# Separating into dependent and independent variables
X = dataset.drop(['status'], axis=1)
y = dataset.statusNow we have X and Y variables containing the following columns.
- gender
- bsc
- workex
- etest_p
- msc
Terrific, we have successfully done the separation, let’s go a step further to splitting these variables into training and testing sets.
Splitting Variables into Training and Testing Sets
This step is very important if we must build and train our model to learn from our dataset. We split data into training and testing sets so that our model can learn the statistics and patterns. Afterward, it will be subjected to testing by feeding it with the test dataset. This will tell us the extent of learning our model has attained from the training dataset. We will be using the Scikit-learn library splitter method to achieve this. The split will be in the ratio of 80% - 20%, where 80% of the dataset will be for training and 20% will be for testing. See the codes below.
# Splitting dataset into trainig and testing
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,train_size=0.8,random_state=1)What’s happening here is that sklearn is an entire module and it contains classes and methods. We use the train_test_split method found in the model_selection module to split our variables.
Fitting Training Variables to a Machine Learning Algorithm
Here is the part we give breath to our machine learning model. We are using the machine learning algorithm called “RandomForestClassifier” of the sklearn library. Without explaining much of the math behind this algorithm, this algorithm will learn from the training dataset and be able to perform classification and prediction based on the intelligence it has gathered from the training dataset. Observe the code snippet below.
# Fitting with random forest model
from sklearn.ensemble import RandomForestClassifier
model=RandomForestClassifier(n_estimators=100)
model.fit(X_train,y_train)Impressive, we are almost done with building our model, let’s test this just created model and see how its performing.
Model Prediction and Testing
We can’t be so sure of the performance of our predictive machine learning model until it undergoes some testing. We will be using the classification_report and metrics method of the sklearn library to check the accuracy report of our model just after we have tested it. The code block below implements this operation.
# Prediction and testing
y_pred=model.predict(X_test)
# Report and Accuracy Score
from sklearn import metrics
from sklearn.metrics import classification_report
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
print("Classification Report RF:\n",classification_report(y_test,y_pred))By running the above code block, you should have a score similar to mine, see the image below.
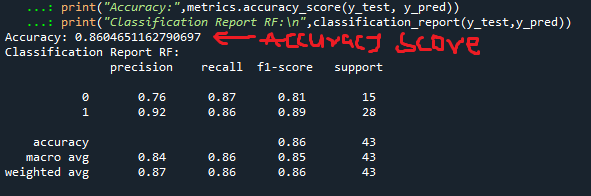
Our model has an accuracy score of about 86%. It **was able to predict **76% instances of truly negative values of variable Y and 92% instances of truly positive values for variable Y.
We can also proceed further to test it on an entirely new dataset with the following codes.
# Model testing on new data
# [[gender, bsc, workex, etest_p, msc]]
# Sample 1
sample = np.array([[0, 2.9, 1, 78.50, 3.7]])
model.predict(sample)
# Sample 2
sample = np.array([[0, 2.9, 1, 78.50, 3.7]])
model.predict(sample)The above code block will produce the result showcased in the image below.
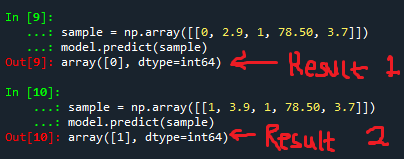
As you can see from the above outputs, the first candidate when subjected to the model, predicted that he wouldn’t be hired due to his credentials, whereas the second candidate was hired.
Now let’s finish up by saving our model for other usages.
Saving Your Model
To preserve your model for future use such as deploying to a production server we must save the model to a file. To store your model in a file, we use a package called “Pickle”. The below code snippet describes how to implement it.
# Saving model
import pickle
pickle.dump(model, open('hireable.pkl', 'wb'))You can use the codes below to load up your data. This is not important for this tutorial but it will be vital for part two of this article which is to develop an API for communicating with this model.
loaded_model = pickle.load(open('hireable.pkl', 'rb'))
result = loaded_model.score(X_test, y_test)
print(result)Congratulations!!!
You have just completed one out of three-part series on building a machine learning predictive site with React and Python. You can get the source code for this project on my Git Repo here.
To conclude, handling the process of hiring an employee manually can be tedious, time-consuming, and error-prone. However, with predictive machine learning models trained to handle this sort of task, the job of hiring a new employee will be greatly simplified. As time goes, more companies and businesses will increasingly utilize more predictive machine learning models to solve their business problems such as the model we just built.
Gospel Darlington is a remote Fullstack web developer, prolific with technologies such as VueJs, Angular, ReactJs, and API development. He takes a huge interest in the development of high-grade and responsive web applications.
Gospel Darlington currently works as a freelancer developing apps and writing tutorials that teach other developers how to integrate software products into their personal projects.
31