
36
How to use openpyxl: A python module for excel files
Hi Everyone,
This is my first blog, when I thought about what topic can I start for my first blog, I decided let me go with
openpyxl a python module for excel .Having said that lets start, before we start:
Sample excel we are using as below:
File Name : sampleData.xlsx
Sheet1: 
Sheet2: 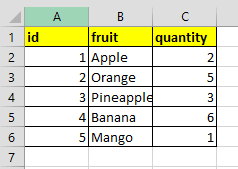
- Installing
- Loading the Workbook
- Working with Sheets
- Retrieving Cell Values
- Retrieving Multiple Values
- Converting data into Python structures
Run the below code in your Python terminal to install
You can install globally or in virtual environment, I usually prefer virtual environment
openpyxl.You can install globally or in virtual environment, I usually prefer virtual environment
pip install openpyxlAfter its installed, we need to import into our python code
(create new python file .py)
import openpyxlLets write below code to load our first excel
# loading workbook
from openpyxl import load_workbook
# NOTE: loading the excel we need
wb = load_workbook(filename='sampleData.xlsx')
print(wb)In above code imported
load_workbook method to read the excel file & stores it in variable "wb"Note the file we are accessing must be in the same folder we are working from.
Output: 
Below code has logic for:
# Working with Sheets
from openpyxl import load_workbook
# NOTE: loading the excel we need
wb = load_workbook(filename='sampleData.xlsx')
# NOTE: get the sheetnames from the excel we read
print(wb.sheetnames) # OUTPUT: ['Sheet1', 'Sheet2']
# NOTE: shows which sheet is currently active
print(wb.active) # OUTPUT: <Worksheet "Sheet1">
# NOTE: we can assign which sheet to be activated, it starts from left to right from the index 0,1 so on...
wb.active = 0
print(wb.active) # OUTPUT: <Worksheet "Sheet1">
wb.active = 1
print(wb.active) # OUTPUT: <Worksheet "Sheet2">
# NOTE: above we saw we can access via index location, now lets access the sheet with the sheet name
sheet = wb['Sheet2']
print(sheet) # OUTPUT: <Worksheet "Sheet2">
print(sheet.title) # OUTPUT: Sheet2Below code has logic for:
# Retrieving Cell Values
from openpyxl import load_workbook
# NOTE: loading the excel we need
wb = load_workbook(filename='sampleData.xlsx')
sheet = wb['Sheet1']
# NOTE: from active sheet we are trying to fetch the value from cell B3
cell_coordinates = sheet['B3']
# NOTE: fetch value, row & column for the cell coordinates
print(cell_coordinates.value) # OUTPUT: Jojo
print(cell_coordinates.row) # OUTPUT: 3
print(cell_coordinates.column) # OUTPUT: 2
print(cell_coordinates.coordinate) # OUTPUT: B3
# NOTE: What if we fetch the empty cell value?
print(sheet['B9'].value) # OUTPUT: None
# NOTE: Return Value using cell
print(sheet.cell(row=2, column=2).value) # OUTPUT: ShijoBelow code has logic for:
# Retrieving Multiple Values
from openpyxl import load_workbook
# NOTE: loading the excel we need
wb = load_workbook(filename='sampleData.xlsx')
sheet = wb['Sheet2']
# NOTE: fetches all the 'A' colum that has data
# OUTPUT: (<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>)
print(sheet['A'])
# NOTE: fetches range of columns without index
print(sheet['A:C'])
'''
OUTOUT:
((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>),
(<Cell 'Sheet2'.B1>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.B6>),
(<Cell 'Sheet2'.C1>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.C6>))
'''
# NOTE: fetches range of columns with index
print(sheet['1:3'])
'''
OUTPUT:
((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>),
(<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>),
(<Cell 'Sheet2'.A3>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.C3>))
'''
# fetch row & column objects
for row in sheet.rows:
print(row)
'''
OUTPUT:
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>)
(<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>)
(<Cell 'Sheet2'.A3>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.C3>)
(<Cell 'Sheet2'.A4>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.C4>)
(<Cell 'Sheet2'.A5>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.C5>)
(<Cell 'Sheet2'.A6>, <Cell 'Sheet2'.B6>, <Cell 'Sheet2'.C6>)
'''
for col in sheet.columns:
print(col)
'''
OUTPUT:
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>)
(<Cell 'Sheet2'.B1>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.B6>)
(<Cell 'Sheet2'.C1>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.C6>)
'''
# Show values only
for row in sheet.iter_rows(values_only=True):
print(row)
'''
OUTPUT:
('id', 'fruit', 'quantity')
(1, 'Apple', 2)
(2, 'Orange', 5)
(3, 'Pineapple', 3)
(4, 'Banana', 6)
(5, 'Mango', 1)
'''
for col in sheet.iter_cols(values_only=True):
print(col)
'''
OUTPUT:
('id', 1, 2, 3, 4, 5)
('fruit', 'Apple', 'Orange', 'Pineapple', 'Banana', 'Mango')
('quantity', 2, 5, 3, 6, 1)
'''# Converting data into Python structures
import json
from openpyxl import load_workbook
# NOTE: loading the excel we need
wb = load_workbook(filename='sampleData.xlsx')
sheet = wb['Sheet2']
# empty dictionary to keep values from excel
books = {}
for row in sheet.iter_rows(min_row=2, min_col=1, values_only=True):
book_id = row[0]
book = {
'Fruit': row[1],
'Qty': row[2]
}
books[book_id] = book
print(json.dumps(books, indent=3))
'''
OUTPUT:
{
"1": {
"Fruit": "Apple",
"Qty": 2
},
"2": {
"Fruit": "Orange",
"Qty": 5
},
"3": {
"Fruit": "Pineapple",
"Qty": 3
},
"4": {
"Fruit": "Banana",
"Qty": 6
},
"5": {
"Fruit": "Mango",
"Qty": 1
}
}
'''If you like to explore more use this Openpyxl documentation
Check my Github source code
36