
23
Database Replication using CDC
Database Replication is the process of taking data from a source database (MySQL, Mongo, PostgreSQL, etc), and copies it into a destination database. This can be a one-time operation or a real-time sync process.
At Powerplay, our Product team constantly runs various data queries to derive user insight. Running complex queries to build user dashboards created a huge overhead on our production database. Therefore production APIs started taking more time to execute. It also caused our production DB to crash a few times. That's when we decide to create a replica of our main production DB and shift all analytics to analytics DB.
There are mainly 3 data replication methods. Selecting the right method depends upon your particular use-case and what type of database you are using.
- Full Load and Dump - In this method, at regular intervals, all the data inside the DB is first queried, then a snapshot is taken. Then this snapshot replaces the previous snapshot in our data warehouse. This method is suited for small tables or for one-time exports.
- Incremental - In this method, we define an event for each table/collection. Every time a row/document is updated or inserted, the event is triggered. The database is queried regularly to look for changes. Despite the initial effort for setting up the trigger system, this method has less load on DB.
- Change Data Capture(CDC) - It involves querying DB's internal operation log every few seconds and copying the changes inside the data warehouse. This is a more reliable method and has a much lower impact on DB performance. It also helps you avoid loading duplicate events. CDC is the best method for databases that are being updated continually.
Why we picked CDC because we want to sync analytics DB with production DB in realtime which can be achieved by incremental and CDC methods. But Incremental method has high initial efforts and requires regular monitoring. On other hand, it is seamless with CDC.
Before knowing how to implement CDC with MongoDB, we will need to know some topics beforehand:
Change Streams are only available for replica sets. This limitation is because the implementation of change streams is based on the oplog, which is only available on replica sets.
NOTE: Change Streams is also available for sharded clusters, but it is not recommended as you would have to tail each oplog on each shard separately, which ultimately defeats the purpose of change streams.
To pass change stream data from source DB to sink DB, we need an event streaming platform. That's where Apache Kafka fits the role.
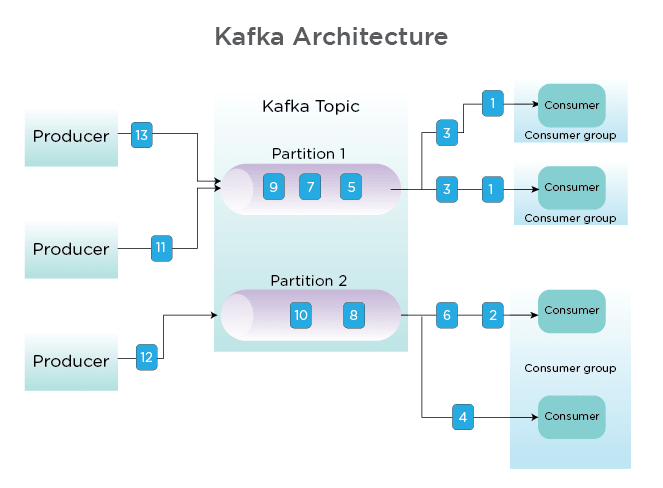
Kafka Key Concepts:
- Cluster: It is a collection of servers, that work together to handle the management of messages/data.
- Messages: byte arrays that store data in any format.
- Topics: Topics are the categories in Kafka to which the messages are stored and published.
- Producers: writes messages to Kafka topics.
- Consumers: read messages from Kafka topics.
To create a connection between MongoDB and Apache Kafka, MongoDB has build official framework MongoDB Kafka Connector.
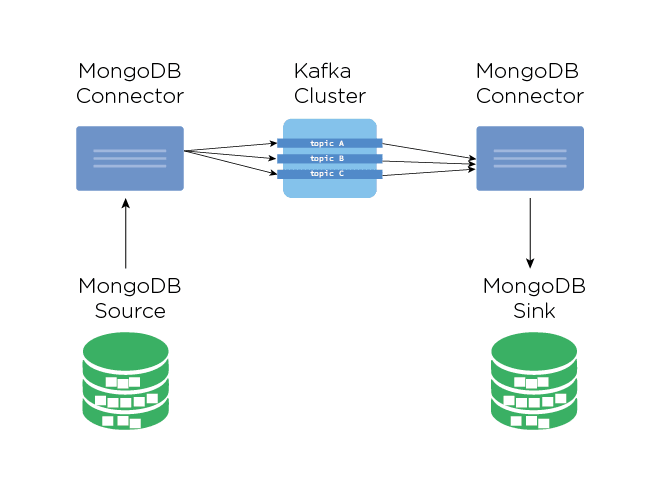
Using this framework, Producers and consumers can write and read changes for each database or collection in MongoDB using the Kafka Connect APIs.
A connector can be configured as a source or a sink:
- Source Connector - This acts as a source. It's configured to subscribe to the changes on our MongoDB deployment and as changes are made in that deployment, events are published to Kafka topics.
- Sink Connector - It reads messages from the topic, and writes documents to sink MongoDB deployment.
MongoDB Kafka Connector makes it seamless to replicate MongoDB using CDC and Kafka. You can find the instructions here on how to setup and use it.
23