
23
Query Logs the AWS WAF using Amazon Athena.
When we require to view the logs coming from the AWS WAF – Web Application Firewall, we count with an option to export the logs to Amazon S3. However, if we try to see them and would like the option to execute queries, there is Amazon Athena.
Amazon Athena
“Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.”1
Amazon S3
“Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance.”2
AWS WAF - Web Application Firewall
“AWS WAF is a web application firewall that helps protect your web applications or APIs against common web exploits and bots that may affect availability, compromise security, or consume excessive resources.”3
Amazon Kinesis Data Firehose
“Amazon Kinesis Data Firehose is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services.”4
Before we begin, first we must configure WAF on AWS, section Logging and metrics -> Logging, the idea is to obtain the logs using Kinesis Data Firehose, while they are saved on Amazon S3 bucket.
With this link I share, you can see a simple guide available at AWS
Then the next step, we should have activated the Logging with the option “Enabled” pointing to Amazon Kinesis Data Firehose delivery stream.

Now, go to the Amazon Athena section in AWS Console and create:
- A Database.
- A table where the data and structure the logs from AWS WAF will be.
Database creation name: demo_waf_logs

Table creation name: waf_logs

Query the creation waf_logs table.
CREATE EXTERNAL TABLE waf_logs(
timestamp bigint,
formatversion int,
webaclid string,
terminatingruleid string,
terminatingruletype string,
action string,
terminatingrulematchdetails array<
struct<
conditiontype:string,
location:string,
matcheddata:array
>
>,
httpsourcename string,
httpsourceid string,
rulegrouplist array<
struct<
rulegroupid:string,
terminatingrule:struct<
ruleid:string,
action:string,
rulematchdetails:string
>,
nonterminatingmatchingrules:array<
struct<
ruleid:string,
action:string,
rulematchdetails:array<
struct<
conditiontype:string,
location:string,
matcheddata:array
>
>
>
>,
excludedrules:array<
struct<
ruleid:string,
exclusiontype:string
>
>
>
>,
ratebasedrulelist array<
struct<
ratebasedruleid:string,
limitkey:string,
maxrateallowed:int
>
>,
nonterminatingmatchingrules array<
struct<
ruleid:string,
action:string
>
>,
requestheadersinserted string,
responsecodesent string,
httprequest struct<
clientip:string,
country:string,
headers:array<
struct<
name:string,
value:string
>
>,
uri:string,
args:string,
httpversion:string,
httpmethod:string,
requestid:string
>,
labels array<
struct<
name:string
>
>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'paths'='action,formatVersion,httpRequest,httpSourceId,httpSourceName,labels,nonTerminatingMatchingRules,rateBasedRuleList,requestHeadersInserted,responseCodeSent,ruleGroupList,terminatingRuleId,terminatingRuleMatchDetails,terminatingRuleType,timestamp,webaclId')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://waf-sandbox/2021/05/'
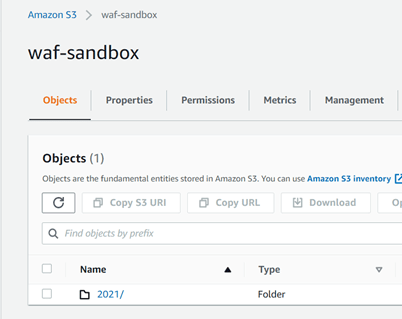
Important: the option LOCATION is the place where the logs AWS WAF are, we can obtain the information searching on Amazon S3 Bucket that we are using to store the logs as it is presented on the picture.
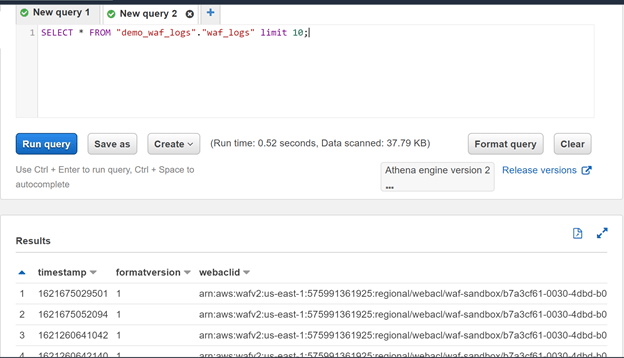
We proceed to view the result before executing the query
SELECT * FROM "demo_waf_logs"."waf_logs" limit 10;
If we execute a query with a filter
SELECT * FROM "demo_waf_logs"."waf_logs" where action='BLOCK' limit 10;

If we execute a query with a filter IP address
SELECT * FROM "demo_waf_logs"."waf_logs" where httprequest.clientip='45.146.164.125' limit 10;

Reference
23