
24
Migrating to Redshift RA3 nodes
RA3 is the latest family of Redshift node types launched at re:Invent 2019. The other node types are Dense Storage (DS2) and Dense Compute (DC2). The primary difference with RA3 is that it has a completely separate storage layer called Redshift Managed Storage (RMS). RMS uses high performance SSDs for your hot data and Amazon S3 for cold data. In addition, it uses high bandwidth networking built on the AWS Nitro System to reduce the time taken for data to be offloaded to and retrieved from Amazon S3.
With the DC2 and DS2 node types, storage is tightly coupled to the compute nodes using EBS volumes attached to each individual node.
There are a number of reasons to consider migrating your existing cluster to the RA3 node types and I have listed what I believe are the main ones.
Every organization is different but the main reason for ours to migrate to RA3 was to take advantage of the increased storage to compute ratio. For every ra3.4xl or ra3.16xl node you add to the your cluster, you get access to 128TB storage capacity. Plus you only pay for what you consume. You are not paying for the full 128TB every month.
By migrating one ds2.8xl node to 2 ra3.4xl nodes, we have increased our storage capacity by 1600% from 16TB to 256TB. While storage is still actually coupled to a compute node, there is so much of it that it has effectively become decoupled.
This table lists the difference in technical specifications between 1 ds2.8xl node and 2 ra3.4xl nodes.
| Node Type | # | vCPU | Memory | Storage | I/O | Slices |
|---|---|---|---|---|---|---|
| ds2.8xl | 1 | 36 | 244 GiB | 16TB HDD | 3.30 GB/s | 160 |
| ra3.4xl | 2 | 24 | 192 GiB | 256TB RMS | 4.00 GB/s | 80 |
It may look like you are taking a reduction in vCPU and Memory but that hasn't had any noticeable impact on the performance of our clusters. Our typical queries are running in the same time or slightly faster. The combination of newer hardware and SSDs makes up for this apparent reduction.
With the DS2 and DC2 node types storage is tightly coupled to vCPU and memory. To purchase more storage, you also have to purchase the attached vCPU and memory. The pushes up the cost of purchasing 1TB storage for these node types to between $77 and $306 per month, depending on purchase plan. With RA3, storage is priced separately to vCPU and memory and 1TB of RMS costs $24 per month, regardless of purchase plan. In our case, we had previously expanded a cluster from 5 to 7 ds2.8xl nodes purely for storage requirements. When we migrated to ra3.4xl, we were able to reduce what should have been 14 nodes (using a 1:2 ratio) to 10 nodes.
The increased storage to compute ratio means that you can now scale storage and compute separately. With our previous 10 node ds2.8xl cluster, we were bound to 160TB. Storage capacity on the cluster bounced between 60% and 80% used depending on the time of year. Working with our business customers to keep used storage capacity below 80% at peak times of activity was a fulltime job. This added more overhead to IT and the business teams taking time away from value creation. Not having to chase business users to delete data from the cluster has been a relief for both the technical and business teams.
If you are purchasing RIs on a 3 or even 1 year term, having different renewal dates on different nodes within the same cluster complicates your cost management. Nodes will come up for renewal at different times of the year and it also makes any future plans you may have for your cluster size have more complicated. Imagine you started with a 5 node cluster purchased on a 3 year term. 1.5 years in, you realize that you need to increase your cluster size to 7 nodes so you purchase 2 more nodes on a 3 year term. Effectively, you have now extended the lifetime of your cluster to 4.5 years. And when the original 5 nodes come up for renewal, what do you do? Extend for another 1 or 3 years?
There is no RI plan for RMS so this reduces complexity here.
If you are running a two node cluster for availability purposes, you may be able to scale down to a smaller RA3 cluster. In our case, we were able to resize a 2 node ds2.8xl cluster to 2 node ra3.4xl cluster. It gives us the same availability profile with 256TB storage.
Other reasons to upgrade to RA3 nodes are that a number of features are only and will only be available on this node type. The new storage model is making possible a number of new features that couldn't be supported on the DC2 and DS2 node types.
1) AQUA: As outlined, RMS stores all data on S3 and then moves data to an SSD layer when requested by compute layer. AQUA pushes more predicates down to RMS and reduces data movement between storage and compute layers. The first iteration of AQUA supports scan and aggregation operations when they contain at least one predicate that contains a LIKE or SIMILAR TO expression. This should greatly enhance query performance where you have these types of queries. We recently turned it on but most of our queries do not match this profile and we have seen very little benefit. However, we hope that AWS will add more support for other expressions in the future and we are now best place to take advantage of any future optimizations.
2) Data sharing: This feature allows you to share live data stored on RMS between different Redshift clusters. For example, you can have one cluster that writes your data to RMS and separate clusters for consuming that data.
3) Cross-AZ Cluster Relocation. Up to now, Redshift was hosted entirely in a single AZ. A failure in the host AZ would mean you would have to restore a snapshot to a new cluster in a separate AZ, generally via a bespoke process. However, RMS is not bound to a single AZ. Therefore, in case of a failure, you will only need to restore your compute nodes in a separate AZ. AWS is making this a setting in the backup details called Cluster relocation. Enabling this feature allows Redshift to relocate your cluster when certain AZ level issues arise.
4) Some existing features may work more effectively with RA3 and RMS specifically. We are currently re-testing concurrency scaling with RA3 as we expect this should work differently with RA3.
With the restricted storage capacity of the DS2 and DC2 nodes, one storage saving pattern that could be applied is to offload the older data on the cluster to S3 and expose them in Redshift using the Spectrum service. Storing 1TB of data in S3 Standard class would cost $23.55 per month. Storing this data in RMS would only cost slightly more at $24.58 per month. However this ignores the operational cost of supporting a bespoke solution using Spectrum.
If you choose a different S3 storage class, the Spectrum pattern may be more cost-effective. For example, if you went for Standard-Infrequent Access, the price would be almost halved to $12.8. However be careful with Standard-IA storage class. Data stored in Standard-IA costs more to access and your costs could quickly exceed Standard if you access it too frequently. A GET request against Standard-IA costs 2.5 times more than against Standard. This can add up quickly.
I would say that RMS offers an easy way to take advantage of S3 storage pricing without any of the operational overhead of explicitly archiving data to S3.
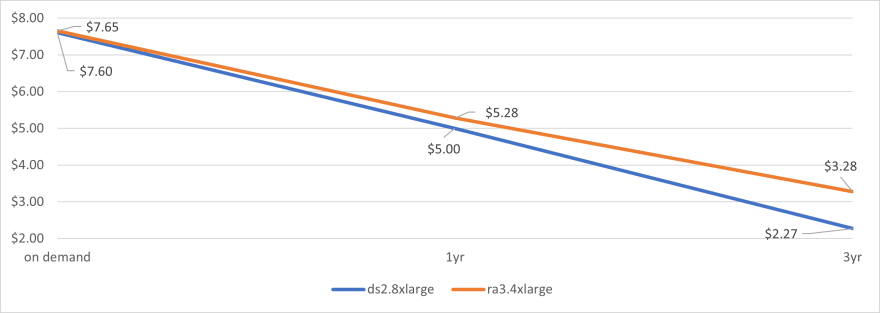
Pricing is a tricky beast here. On-demand and 1yr terms are almost the same even when you include storage cost. However, if you compare 3 year terms for ds2.8xl nodes versus ra3.4xl, prices are 44% more expensive for the newer hardware.
| Node Type | # | On Demand | 1yr | 3yr | Storage (16TB * 0.8) |
|---|---|---|---|---|---|
| ds2.8xl | 1 | $7.60 per Hour | $5.00 | $2.27 | $0.00 |
| ra3.4xl | 2 | $7.212 per Hour | $4.84 | $2.84 | $0.44 |
| Cost Difference | 0.65% | 5.6% | 44% |
Pricing for backup storage is also different. For DS2 and DC2 clusters the charge is only applied to the amount of manual snapshot storage above the amount of provisioned storage on the cluster. All manual snapshots taken for RA3 clusters are billed as backup storage at standard Amazon S3 rates. However, automated snapshots are priced the same.
All of these pricing scenarios are based on the theory that you upgrade on 1:2 ratio. In theory, if you replace 1 ds2.8xl with 2 ra3.4xl nodes, it will cost you more over a 3 year term. This ignores the main benefit of the decoupled compute and storage that upgrading to RA3 provides. In practice, we were able to reduce the number of nodes we were using and our monthly Redshift costs dropped by 12%.
Other cost savings with reduced operational overhead are harder to quantify but worth taking into account if assessing a move to RA3.
The migration process is straightforward. The only technical decision you need to make is whether you wish to use elastic or classic resize. Classic resize provisions a new cluster and copies the data from the original cluster to the new cluster. Elastic resize works by changing or adding nodes to your existing cluster. Elastic resize is the AWS recommended approach and they have improved it a lot recently especially with the ability to change node types. It is also the fastest way to add and remove nodes. Classic resize can take several hours or days depending on the size and configuration of your cluster.
The main reason to use classic over elastic resize is if the new cluster configuration isn't possible with an elastic resize. Elastic resize is an opinionated option and only allows you to add or remove nodes within certain parameters. For example,
For dc2.8xlarge, ds2.8xlarge, ra3.4xlarge, or ra3.16xlarge node types, you can change the number of nodes to half the current number or double the current number of nodes. A 4-node cluster can be resized to 2, 3, 5, 6, 7, or 8 nodes.
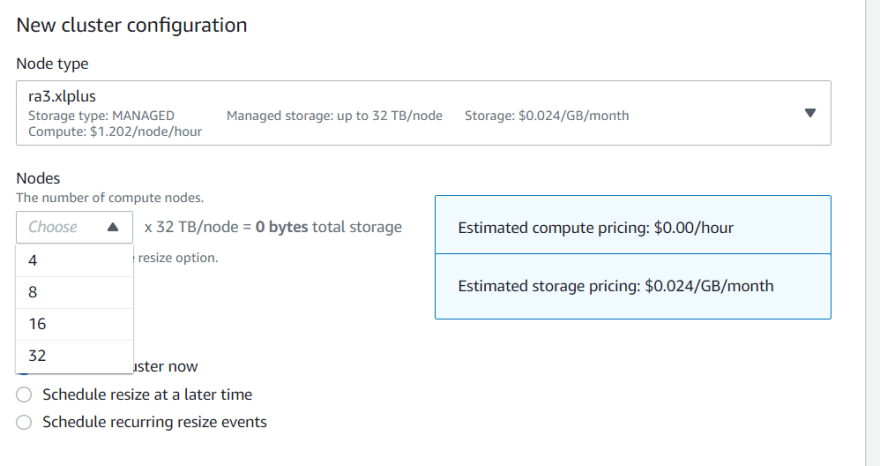
The easiest way to check what cluster size is available via elastic resize is to check within the console.
Go to Actions --> Resize. Elastic resize (recommended) is chosen by default. Scroll down to the Nodes dropdown and you can see the number of nodes you can upgrade to.
For more information, AWS have a good page with the details you'll need on resizing your cluster.
At the time of our upgrade, we were able to choose elastic resize for 2 of our larger clusters. Elastic resize was not available as an option for moving from a 2 node ds2.8xl cluster to 2 node ra3.4xl cluster so we went with classic resize for those. However, that option is now available via the console.
| Original Node Type | New Node Type | Elastic vs Classic | Data Size | Time |
|---|---|---|---|---|
| 10 ds2.8xl | 20 ra3.4xl | Elastic | 120tb | 30 minutes |
| 7 ds2.8xl | 10 ra3.4xl | Elastic | 70tb | 32 minutes |
| 2 ds2.8xl | 2 ra3.4xl | Classic | 2.66tb | 8 hours |
| 2 ds2.8xl | 2 ra3.4xl | Classic | 9.86tb | 35 hours |
As you can see from the table above, there is a huge difference in execution times of elastic versus classic resize. While there may be reasons to use classic, an elastic resize makes the entire upgrade simple and quick.
One thing to note is that while we were able to run both elastic resizes in parallel, the classic resizes cannot run in parallel. If you kick off a second classic resize, it will wait until the first completes before executing. It will be in read-only mode while waiting so you may want to only kick off 2nd resize after the 1st resize completes.
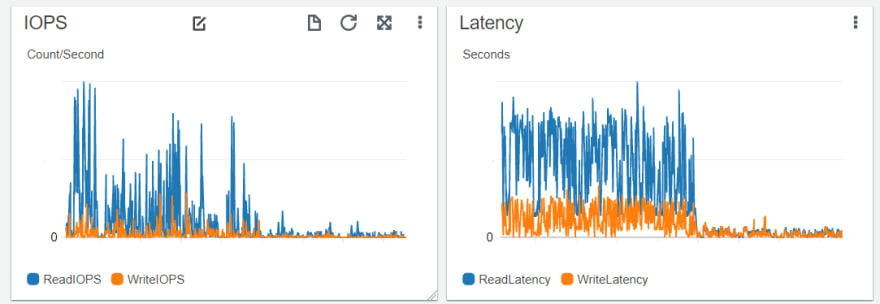
As stated previously, the migration to RA3 did not bring a massive lift in performance. It is a very stable and easy migration that brings a lot of benefits to reduce your operational and management load in relation to Redshift. That stability was apparent in the Redshift CloudWatch Dashboard where we saw large drops in our Read and WriteIOPS combined with a drop in Read and WriteLatency but no major changes overall. This was expected with the move to RMS plus a slight increase in CPU Utilisation.
Upgrading your Redshift cluster to RA3 node types simplifies the management of your cluster. This is primarily enabled through the massive increase in storage available per node. This increase in storage comes without any trade-off in performance. We are 4 months after the upgrade and the best word I can use to describe our experience is stability. The upgrades on our largest clusters took 30 minutes using an elastic resize. The upgrade required no code changes and had no impact on our customers.
From AWS, we see all the new features being enabled on RA3 first. The new storage architecture enables new features that would not be possible in the older node types and such features will never be available on the DC2 or DS2 node types.
24