
24
Scrape and download Google Images with Python
Intro
This blog post is a continuation of Google's web scraping series. Here you'll see how to scrape Google Images using Python with beautifulsoup, requests, lxml libraries. An alternative API solution will be shown.
Prerequisites: basic knowledge of beautifulsoup, requests, lxml and regular expressions.
Imports
import requests, lxml, re, json, urllib.request
from bs4 import BeautifulSoupWhat will be scraped
Suggested search results

Image results

Process
Firstly, selecting container with needed data, name, link, chips for suggested search results. CSS selector reference.
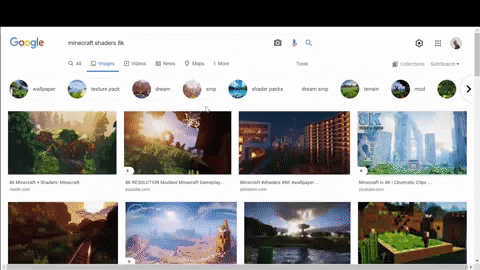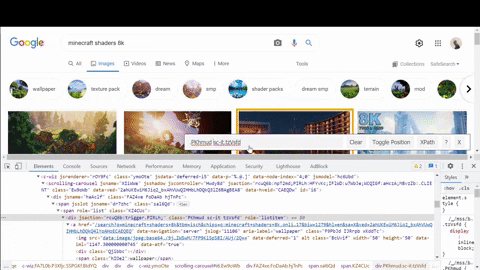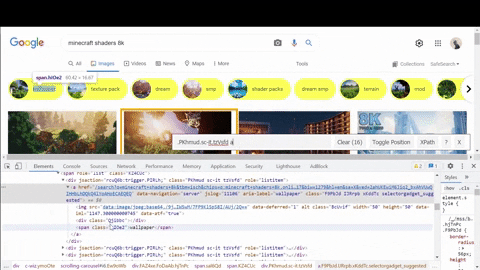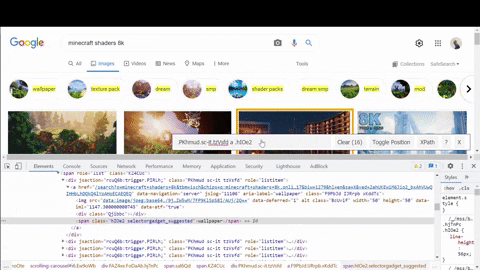
Secondly, looking where decoded thumbnail URLs are located for suggested search results.
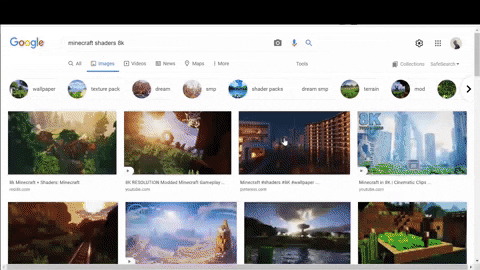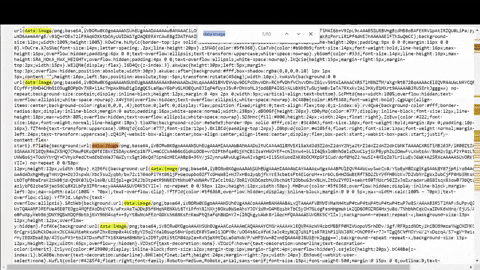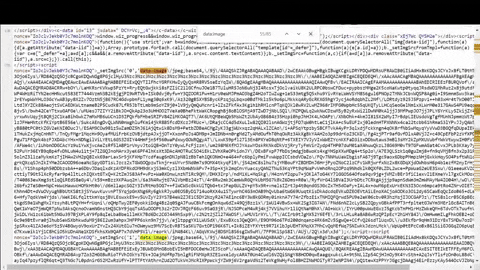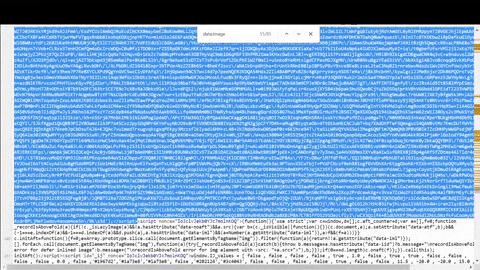
On the GIF above I copied data:image part from src attribute to check with Chrome find bar (Ctrl+F) if something I was looking for is located in the <script> tags.
Why can't I just parse src attribute from img element?
If you parse
<img>withsrcattribute, you'll get an 1x1 placeholder instead of actual thumbnail.
The logic was:
-
find where in the
<script>tags decoded thumbnail URLs were located. -
split certain chuck of the text from the big blob of text to a smaller one for easier
regexextraction. -
create a
regexpattern that will match all URLs. The same process was applied to extract original resolution images with their thumbnails.
To test your regular expression you can use regex101.
Save images
To save images you can use urllib.request.urlretrieve(url, filename) (more in-depth)
# often times it will throw 404 error, so to avoid it we need to pass user-agent
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(original_size_img, f'LOCAL_FOLDER_NAME/YOUR_IMAGE_NAME.jpg')Code
Start of the code for both functions
import requests, lxml, re, datetime
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
"q": "minecraft shaders 8k photo",
"tbm": "isch",
"ijn": "0",
}
html = requests.get("https://www.google.com/search", params=params, headers=headers)
soup = BeautifulSoup(html.text, 'lxml')Scrape Suggested search results: name, link, chips, thumbnail.
def get_suggested_search_data():
for suggested_search in soup.select('.PKhmud.sc-it.tzVsfd'):
suggested_search_name = suggested_search.select_one('.hIOe2').text
suggested_search_link = f"https://www.google.com{suggested_search.a['href']}"
# https://regex101.com/r/y51ZoC/1
suggested_search_chips = ''.join(re.findall(r'=isch&chips=(.*?)&hl=en-US', suggested_search_link))
print(f"{suggested_search_name}\n{suggested_search_link}\n{suggested_search_chips}\n")
# this steps could be refactored to a more compact
all_script_tags = soup.select('script')
# https://regex101.com/r/48UZhY/6
matched_images_data = ''.join(re.findall(r"AF_initDataCallback\(({key: 'ds:1'.*?)\);</script>", str(all_script_tags)))
# https://kodlogs.com/34776/json-decoder-jsondecodeerror-expecting-property-name-enclosed-in-double-quotes
# if you try to json.loads() without json.dumps() it will throw an error:
# "Expecting property name enclosed in double quotes"
matched_images_data_fix = json.dumps(matched_images_data)
matched_images_data_json = json.loads(matched_images_data_fix)
# search for only suggested search thumbnails related
# https://regex101.com/r/ITluak/2
suggested_search_thumbnails_data = ','.join(re.findall(r'{key(.*?)\[null,\"Size\"', matched_images_data_json))
# https://regex101.com/r/MyNLUk/1
suggested_search_thumbnail_links_not_fixed = re.findall(r'\"(https:\/\/encrypted.*?)\"', suggested_search_thumbnails_data)
print('Suggested Search Thumbnails:') # in order
for suggested_search_fixed_thumbnail in suggested_search_thumbnail_links_not_fixed:
# https://stackoverflow.com/a/4004439/15164646 comment by Frédéric Hamidi
suggested_search_thumbnail = bytes(suggested_search_fixed_thumbnail, 'ascii').decode('unicode-escape')
print(suggested_search_thumbnail)
get_suggested_search_data()Scrape Google images: title, link, source, thumbnail, original resolution image (and download them):
def get_images_data():
print('\nGoogle Images Metadata:')
for google_image in soup.select('.isv-r.PNCib.MSM1fd.BUooTd'):
title = google_image.select_one('.VFACy.kGQAp.sMi44c.lNHeqe.WGvvNb')['title']
source = google_image.select_one('.fxgdke').text
link = google_image.select_one('.VFACy.kGQAp.sMi44c.lNHeqe.WGvvNb')['href']
print(f'{title}\n{source}\n{link}\n')
# this steps could be refactored to a more compact
all_script_tags = soup.select('script')
# # https://regex101.com/r/48UZhY/4
matched_images_data = ''.join(re.findall(r"AF_initDataCallback\(([^<]+)\);", str(all_script_tags)))
# https://kodlogs.com/34776/json-decoder-jsondecodeerror-expecting-property-name-enclosed-in-double-quotes
# if you try to json.loads() without json.dumps it will throw an error:
# "Expecting property name enclosed in double quotes"
matched_images_data_fix = json.dumps(matched_images_data)
matched_images_data_json = json.loads(matched_images_data_fix)
# https://regex101.com/r/pdZOnW/3
matched_google_image_data = re.findall(r'\[\"GRID_STATE0\",null,\[\[1,\[0,\".*?\",(.*),\"All\",', matched_images_data_json)
# https://regex101.com/r/NnRg27/1
matched_google_images_thumbnails = ', '.join(
re.findall(r'\[\"(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]',
str(matched_google_image_data))).split(', ')
print('Google Image Thumbnails:') # in order
for fixed_google_image_thumbnail in matched_google_images_thumbnails:
# https://stackoverflow.com/a/4004439/15164646 comment by Frédéric Hamidi
google_image_thumbnail_not_fixed = bytes(fixed_google_image_thumbnail, 'ascii').decode('unicode-escape')
# after first decoding, Unicode characters are still present. After the second iteration, they were decoded.
google_image_thumbnail = bytes(google_image_thumbnail_not_fixed, 'ascii').decode('unicode-escape')
print(google_image_thumbnail)
# removing previously matched thumbnails for easier full resolution image matches.
removed_matched_google_images_thumbnails = re.sub(
r'\[\"(https\:\/\/encrypted-tbn0\.gstatic\.com\/images\?.*?)\",\d+,\d+\]', '', str(matched_google_image_data))
# https://regex101.com/r/fXjfb1/4
# https://stackoverflow.com/a/19821774/15164646
matched_google_full_resolution_images = re.findall(r"(?:'|,),\[\"(https:|http.*?)\",\d+,\d+\]",
removed_matched_google_images_thumbnails)
print('\nFull Resolution Images:') # in order
for index, fixed_full_res_image in enumerate(matched_google_full_resolution_images):
# https://stackoverflow.com/a/4004439/15164646 comment by Frédéric Hamidi
original_size_img_not_fixed = bytes(fixed_full_res_image, 'ascii').decode('unicode-escape')
original_size_img = bytes(original_size_img_not_fixed, 'ascii').decode('unicode-escape')
print(original_size_img)
# ------------------------------------------------
# Download original images
# print(f'Downloading {index} image...')
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(original_size_img, f'YOUR_LOCALFOLDER/YOUR_FILE_NAME.jpg')
get_google_images_data()If you wonder, here's a few attempts for creating regex pattern to extract original resolution images:
1. \[\d+,\[\d+,\"\w+\",,\[\"(https:|http.*?)\",\d+,\d+\]
2. \[\"(https:|http.*?)\",\d+,\d+\]
3. ['|,,]\[\"(https:|http.*?)\",\d+,\d+\]
4. (?:'|,),\[\"(https|http.*?)\",\d+,\d+\] # finalOutput from two functions:
-------------------------------------------------
Google Suggested Search Results
-------------------------------------------------
texture pack
https://www.google.com/search?q=minecraft+shaders+8k+photo&tbm=isch&chips=q:minecraft+shaders+8k+photo,online_chips:texture+pack:5UdWXA5mkNo%3D&hl=en-US&sa=X&ved=2ahUKEwiRy8vcgPnxAhUpu6QKHV9FCLsQ4lYoAHoECAEQEA
q:minecraft+shaders+8k+photo,online_chips:texture+pack:5UdWXA5mkNo%3D
...
Suggested Search Thumbnails:
https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQPsrr--O2yuSyFg-Al3DN0MyhhuO2RcktFCEFiuzs1RoK4oZvS&usqp=CAU
...
-------------------------------------------------
Google Images Results
-------------------------------------------------
8K RESOLUTION Modded Minecraft Gameplay With Ultra Shaders (Yes Really) - YouTube
youtube.com
https://www.youtube.com/watch?v=_mR0JBLXRLY
...
Google Image Thumbnails:
https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcR6RRuk2k_wMIMt4hhNAatPgmfrDWvAsXrKC90LeBn4GDoySeBQPruapu7ADCSVyORtU48&usqp=CAU
...
Google Full Resolution Images:
https://i.ytimg.com/vi/_mR0JBLXRLY/maxresdefault.jpgGIF was sped up by 520%

Note: I was going for a process that felt intuitive at the moment of coding. It could be better regex pattern and fewer lines of code where I divide code into parts with regex, but in terms of speed, the GIF above demonstrates that everything happens pretty quickly in 0:00:00:975229 microseconds.

Using Google Images API
SerpApi is a paid API with a free plan.
The difference is that iterating over the structured JSON VS figuring out where the decoded thumbnails and their original resolution is pretty awesome.

import os, urllib.request, json # json for pretty output
from serpapi import GoogleSearch
def get_google_images():
params = {
"api_key": os.getenv("API_KEY"),
"engine": "google",
"q": "pexels cat",
"tbm": "isch"
}
search = GoogleSearch(params)
results = search.get_dict()
# print(json.dumps(results['suggested_searches'], indent=2, ensure_ascii=False))
print(json.dumps(results['images_results'], indent=2, ensure_ascii=False))
# -----------------------
# Downloading images
for index, image in enumerate(results['images_results']):
print(f'Downloading {index} image...')
opener=urllib.request.build_opener()
opener.addheaders=[('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582')]
urllib.request.install_opener(opener)
urllib.request.urlretrieve(image['original'], f'SerpApi_Images/original_size_img_{index}.jpg')
get_google_images()
---------------------
'''
Suggested search results:
[
{
"name": "wallpaper",
"link": "https://www.google.com/search?q=minecraft+shaders+8k+photo&tbm=isch&chips=q:minecraft+shaders+8k+photo,online_chips:wallpaper:M78_F4UxoJw%3D&hl=en-US&sa=X&ved=2ahUKEwibusKPuvjxAhWFEt8KHbN0CBUQ4lYoAHoECAEQEQ",
"chips": "q:minecraft+shaders+8k+photo,online_chips:wallpaper:M78_F4UxoJw%3D",
"serpapi_link": "https://serpapi.com/search.json?chips=q%3Aminecraft%2Bshaders%2B8k%2Bphoto%2Conline_chips%3Awallpaper%3AM78_F4UxoJw%253D&device=desktop&engine=google&google_domain=google.com&q=minecraft+shaders+8k+photo&tbm=isch",
"thumbnail": "https://serpapi.com/searches/60fa52ca477c0ec3f75f0d3b/images/3868309500692ce40237282387fb16587c67c8a9bb635eefe35216c182003a4d.jpeg"
}
...
]
---------------------
Image results:
[
{
"position": 1,
"thumbnail": "https://serpapi.com/searches/60fa52ca477c0ec3f75f0d3b/images/07dc65d29a3e1094e9c1551efe12324ee8387d268cf2eec92bf0eaed1550eecb.jpeg",
"source": "reddit.com",
"title": "8k Minecraft + Shaders: Minecraft",
"link": "https://www.reddit.com/r/Minecraft/comments/6iamxa/8k_minecraft_shaders/",
"original": "https://external-preview.redd.it/mAQWN2kUYgFS3fgm6LfYo37AY7i2e_YY8d83_1jTeys.jpg?auto=webp&s=b2bad0e23cbd83426b06e6a547ef32ebbc08e2d2"
}
...
]
'''Links
Outro
If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.
24