
57
Apache Kafka: Apprentice Cookbook
Apache Kafka is a distributed event streaming platform built over strong concepts. Let’s dive into the possibilities it offers.
- Processing messages as an Enterprise Service Bus.
- Tracking Activity, metrics, and telemetries.
- Processing Streams.
- Supporting Event sourcing.
- Storing logs.
This article will see the concepts backing up Kafka and the different tools available to handle data streams.
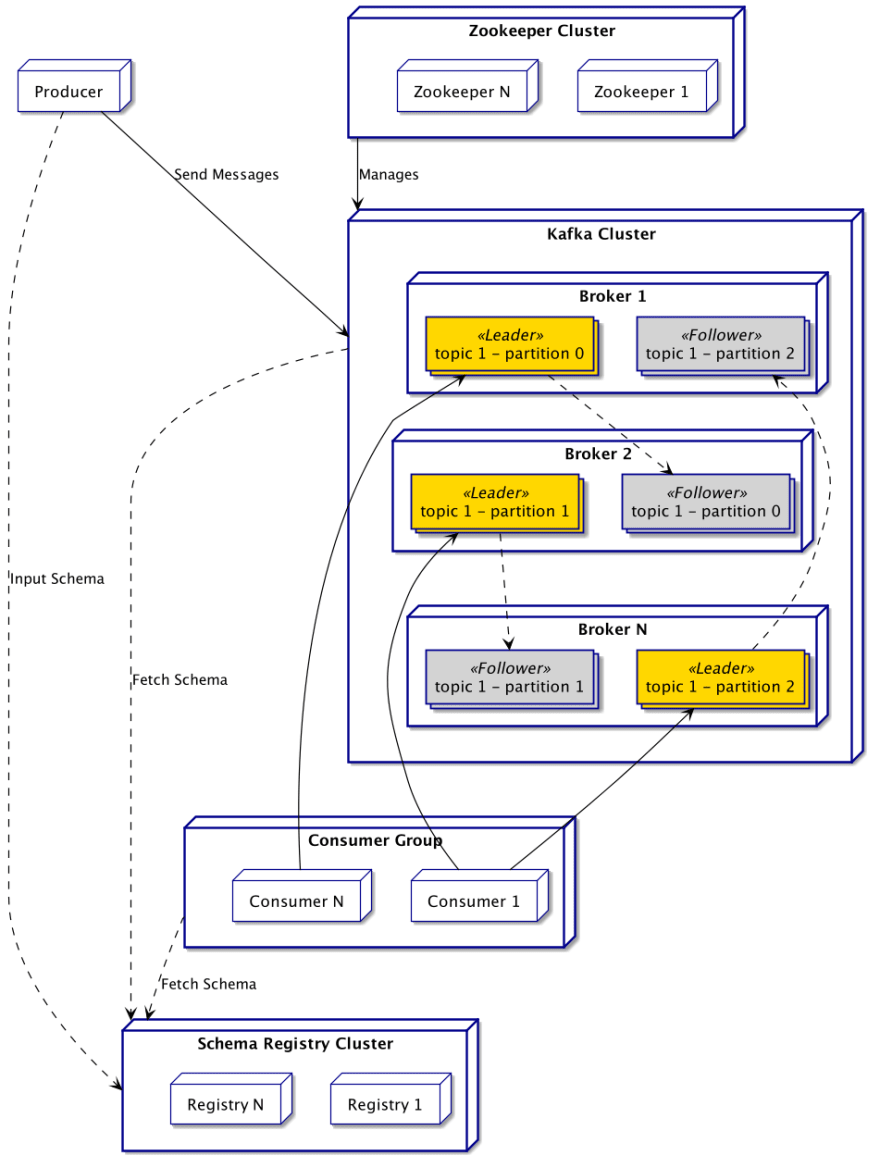
The behaviour of Kafka is pretty simple: Producers push Messages into a particular Topic, and Consumers subscribe to this Topic to fetch and process the Messages. Let’s see how it is achieved by this technology.
Independently of the use, the following components will be deployed:
- One or more Producers sending messages to the brokers.
- One or more Kafka Brokers, the actual messaging server handling communication between producers and consumers.
- One or more Consumers fetching and processing messages, in clusters named Consumer Groups.
- One or more Zookeeper instances managing the brokers.
- (Optionally) One or more Registry instances uniformizing message schema.
As a scalable distributed system, Kafka is heavily relying on the concept of clusters. As a result, on typical production deployment, there will likely be multiple instances of each component.
A Consumer Group is a cluster of the same consumer application. This concept is heavily used by Kafka to balance the load on the applicative side of things.
Note: The dependency on Zookeeper will be removed soon, Cf. KIP-500
Further Reading:
Design & Implementation Documentation
Kafka Basics and Core Concepts: Explained — Aritra Das
A Message in Kafka is a key-value pair. Those elements can be anything from an integer to a Protobuf message, provided the right serializer and deserializer.
The message is sent to a Topic, which will store it as a Log. The topic should be a collection of logs semantically related, but without a particular structure imposed. A topic can either keep every message as a new log entry or only keep the last value for each key (a.k.a. Compacted log).
To take advantage of the multiple brokers, topics are sharded into Partitions by default. Kafka will assign any received message to one partition depending on its key,
or using a partitioner algorithm otherwise, which results in a random assignment from the developer's point of view. Each partition has a Leader responsible for all I/O operations, and Followers replicating the data. A follower will take over the leader role in case of an issue with the current one.
The partition holds the received data in order, increasing an offset integer for each message. However, there is no order guarantee between two partitions. So for order-dependent data, one must ensure that they end up in the same partition by using the same key.
Each partition is assigned to a specific consumer from the consumer group. This consumer is the only one fetching messages from this partition. In case of shutdown of one customer, the brokers will reassign partitions among the customers.
Being an asynchronous system, it can be hard and impactful on the performances to have every message delivered exactly one time to the consumer. To mitigate this, Kafka provides different levels of guarantee on the number of times a message will be processed (i.e. at most once, at least once, exactly once).
Further Reading:
Log Compacted Topics in Apache Kafka — Seyed Morteza Mousavi
(Youtube) Apache Kafka 101: Replication — Confluent
Replication Design Doc
Processing Guarantees in Details — Andy Briant
Messages are serialized when quitting a producer and deserialized when handled by the consumer. To ensure compatibility, both must be using the same data definition. Ensuring this can be hard considering the application evolution. As a result, when dealing with a production system, it is recommended to use a schema to explicit a contract on the data structure.
To do this, Kafka provides a Registry server, storing and binding schema to topics. Historically only Avro was available, but the registry is now modular and can also handle JSON and Protobuf out of the box.
Once a producer sent a schema describing the data handled by its topic to the registry, other parties (i.e. brokers and consumers) will fetch this schema on the registry to validate and deserialize the data.
Further Reading:
Schema Registry Documentation
Kafka tutorial #4-Avro and the Schema Registry— Alexis Seigneurin
Serializer-Deserializer for Schema
Kafka provides multiple ways of connecting to the brokers,
and each can be more useful than the others depending on the needs. As a result, even if a library is an abstraction layer above another, it is not necessarily better for every use case.
There are client libraries available in numerous languages which help develop a producer and consumer easily. We will use Java for the example below, but the concept remains identical for other languages.
The producer concept is to publish messages at any moment, so the code is pretty simple.
public class Main {
public static void main(String[] args) throws Exception {
// Configure your producer
Properties producerProperties = new Properties();
producerProperties.put("bootstrap.servers", "localhost:29092");
producerProperties.put("acks", "all");
producerProperties.put("retries", 0);
producerProperties.put("linger.ms", 1);
producerProperties.put("key.serializer", "org.apache.kafka.common.serialization.LongSerializer");
producerProperties.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
producerProperties.put("schema.registry.url", "http://localhost:8081");
// Initialize a producer
Producer<Long, AvroHelloMessage> producer = new KafkaProducer<>(producerProperties);
// Use it whenever you need
producer.send(new AvroHelloMessage(1L, "this is a message", 2.4f, 1));
}
}The code is a bit more complex on the consumer part since the consumption loop needs to be created manually. On the other hand, this gives more control over its behaviour. The consumer state is automatically handled by the Kafka library. As a result, restarting the worker will start at the most recent offset he encountered.
public class Main {
public static Properties configureConsumer() {
Properties consumerProperties = new Properties();
consumerProperties.put("bootstrap.servers", "localhost:29092");
consumerProperties.put("group.id", "HelloConsumer");
consumerProperties.put("key.deserializer", "org.apache.kafka.common.serialization.LongDeserializer");
consumerProperties.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer");
consumerProperties.put("schema.registry.url", "http://localhost:8081");
// Configure Avro deserializer to convert the received data to a SpecificRecord (i.e. AvroHelloMessage)
// instead of a GenericRecord (i.e. schema + array of deserialized data).
consumerProperties.put(KafkaAvroDeserializerConfig.SPECIFIC_AVRO_READER_CONFIG, true);
return consumerProperties;
}
public static void main(String[] args) throws Exception {
// Initialize a consumer
final Consumer<Long, AvroHelloMessage> consumer = new KafkaConsumer<>(configureConsumer());
// Chose the topics you will be polling from.
// You can subscribe to all topics matching a Regex.
consumer.subscribe(Pattern.compile("hello_topic_avro"));
// Poll will return all messages from the current consumer offset
final AtomicBoolean shouldStop = new AtomicBoolean(false);
Thread consumerThread = new Thread(() -> {
final Duration timeout = Duration.ofSeconds(5);
while (!shouldStop) {
for (ConsumerRecord<Long, AvroHelloMessage> record : consumer.poll(timeout)) {
// Use your record
AvroHelloMessage value = record.value();
}
// Be kind to the broker while polling
Thread.sleep(5);
}
consumer.close(timeout);
});
// Start consuming && do other things
consumerThread.start();
// [...]
// End consumption from customer
shouldStop.set(true);
consumerThread.join();
}
}Further Reading:
Available Libraries
Producer Configuration
Consumer Configuration
Kafka Streams is built on top of the consumer library. It continuously reads from a topic and processes the messages with code declared with a functional DSL.
During the processing, transitional data can be kept in structures called KStream and KTable, which are stored into topics. The former is equivalent to a standard topic, and the latter to a compacted topic. Using these data stores will enable automatic tracking of the worker state by Kafka, helping to get back on track in case of restart.
The following code sample is extracted from the tutorial provided by Apache. The code connects to a topic named streams-plaintext-input containing strings values, without necessarily providing keys. The few lines configuring the StreamsBuilder will:
- Transform each message to lowercase.
- Split the result using whitespaces as a delimiter.
- Group previous tokens by value.
- Count the number of tokens for each group and save the changes to a KTable named
counts-store. - Stream the changes in this Ktable to send the values in a KStream named
streams-wordcount-output.
public class Main {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
final StreamsBuilder builder = new StreamsBuilder();
builder.<String, String>stream("streams-plaintext-input")
.flatMapValues(value -> Arrays.asList(value.toLowerCase(Locale.getDefault()).split("\\W+")))
.groupBy((key, value) -> value)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"))
.toStream()
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
final CountDownLatch latch = new CountDownLatch(1);
// attach shutdown handler to catch control-c
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
// The consumer loop is handled by the library
streams.start();
latch.await();
}
}Kafka Connect provides a way of transforming and synchronizing data between almost any technology with the use of Connectors. Confluent is hosting a Hub, on which users can share connectors for various technologies. This means that integrating a Kafka Connect pipeline is most of the time only a matter of configuration, without code required. A single connector can even handle both connection sides:
- Populate a topic with data from any system: i.e. a Source.
- Send data from a topic to any system: i.e. a Sink.
The source will read data from CSV files in the following schema then publish them into a topic. Concurrently, the sink will poll from the topic and insert the messages into a MongoDB database. Each connector can run in the same or a distinct worker, and workers can be grouped into a cluster for scalability.

The connector instance is created through a configuration specific to the library. The file below is a configuration of the MongoDB connector. It asks to fetch all messages from the topic mongo-source to insert them into the collection sink of the database named kafka-connect. The credentials are provided from an external file, which is a feature of Kafka Connect to protect secrets.
{
"name": "mongo-sink",
"config": {
"topics": "mongo-source",
"tasks.max": "1",
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"connection.uri": "mongodb://${file:/auth.properties:username}:${file:/auth.properties:password}@mongo:27017",
"database": "kafka_connect",
"collection": "sink",
"max.num.retries": "1",
"retries.defer.timeout": "5000",
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.BsonOidStrategy",
"post.processor.chain": "com.mongodb.kafka.connect.sink.processor.DocumentIdAdder",
"delete.on.null.values": "false",
"writemodel.strategy": "com.mongodb.kafka.connect.sink.writemodel.strategy.ReplaceOneDefaultStrategy"
}
}Once the configuration complete, registering the connector is as easy as an HTTP call on the running Kafka Connect instance. Afterwards, the service will automatically watch the data without further work required.
$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
http://localhost:8083/connectors -d @sink-conf.jsonFurther Reading:
Getting Started Documentation
Connector Instance API Reference
(Youtube) Tutorials Playlist — Confluent
Ksql is somehow equivalent to Kafka Streams, except that every transformation is declared in an SQL-like language. The server is connected to the brokers and can create Streams or Tables from topics. Those two concepts behave in the same way as a KStream or KTable from Kafka Streams (i.e. respectively a topic and a compacted topic).
There are three types of query in the language definition:
- Persistent Query (e.g.
CREATE TABLE <name> WITH (...)): Creates a new stream or table that will be automatically updated. - Pull Query (e.g.
SELECT * FROM <table|stream> WHERE ID = 1): Behaves similarly to a standard DBMS. Fetches data as an instant snapshot and closes the connection. - Push Query (e.g.
_SELECT * FROM <table|stream> EMIT CHANGES_): Requests a persistent connection to the server, asynchronously pushing updated values.
The database can be used to browse the brokers' content. Topics can be discovered through the command list topics, and their content displayed using print <name>.
ksql> list topics;
Kafka Topic | Partitions | Partition Replicas
----------------------------------------------------
hello_topic_json | 1 | 1
----------------------------------------------------
ksql> print 'hello_topic_json' from beginning;
Key format: KAFKA_BIGINT or KAFKA_DOUBLE or KAFKA_STRING
Value format: JSON or KAFKA_STRING
rowtime: 2021/05/25 08:44:20.922 Z, key: 1, value: {"user_id":1,"message":"this is a message","value":2.4,"version":1}
rowtime: 2021/05/25 08:44:20.967 Z, key: 1, value: {"user_id":1,"message":"this is another message","value":2.4,"version":2}
rowtime: 2021/05/25 08:44:20.970 Z, key: 2, value: {"user_id":2,"message":"this is another message","value":2.6,"version":1}The syntax to create and query a stream, or a table is very close to SQL.
-- Let's create a table from the previous topic
ksql> CREATE TABLE messages (user_id BIGINT PRIMARY KEY, message VARCHAR)
> WITH (KAFKA_TOPIC = 'hello_topic_json', VALUE_FORMAT='JSON');
-- We can see the list and details of each table
ksql> list tables;
Table Name | Kafka Topic | Key Format | Value Format | Windowed
---------------------------------------------------------------------------
MESSAGES | hello_topic_json | KAFKA | JSON | false
---------------------------------------------------------------------------
ksql> describe messages;
Name : MESSAGES
Field | Type
-----------------------------------------------
USER_ID | BIGINT (primary key)
MESSAGE | VARCHAR(STRING)
-----------------------------------------------
For runtime statistics and query details run: DESCRIBE EXTENDED <Stream,Table>;
-- Appart from some additions to the language, the queries are almost declared in standard SQL.
ksql> select * from messages EMIT CHANGES;
+--------+------------------------+
|USER_ID |MESSAGE |
+--------+------------------------+
|1 |this is another message |
|2 |this is another message |Kafka recommends using a headless ksqlDB server for production, with a file declaring all streams and tables to create. This avoids any modification to the definitions.
Note: ksqlDB servers can be grouped in a cluster like any other consumer.
Further Reading:
This article gives a broad view of the Kafka ecosystem and possibilities, which are numerous. This article only scratches the surface of each subject. But worry not, as they are all well documented by Apache, Confluent, and fellow developers.
Here are a few supplementary resources to dig further into Kafka:
The complete experimental code is available on my GitHub repository.
Thanks to Sarra Habchi, and Dimitri Delabroye for the reviews
57