
35
Explaining boto3: How to use any AWS service with Python
A deep dive into boto3 and how AWS built it.
AWS defines boto3 as a Python Software Development Kit to create, configure, and manage AWS services. In this article, we'll look at how boto3 works and how it can help us interact with various AWS services.

Photo by Kindel Media from Pexels
Both, AWS CLI and boto3 are built on top of botocore --- a low-level Python library that takes care of everything needed to send an API request to AWS and receive a response back.
Botocore:
- handles session, credentials, and configuration,
- gives fine-granular access to all operations (ex. ListObjects, DeleteObject) within a specific service (ex. S3),
- takes care of serializing input parameters, signing requests, and deserializing response data into Python dictionaries,
- provides low-level* clients and high-level resource* abstractions to interact with AWS services from Python.
You can think of botocore as a package that allows us to forget about underlying JSON specifications and use Python (boto3) when interacting with AWS APIs.
In most cases, we should use boto3 rather than botocore. Using boto3, we can choose to either interact with lower-level clients or higher-level object-oriented resource abstractions. The image below shows the relationship between those abstractions.

Level of abstraction in boto3, aws-cli, and botocore based on S3 as an example --- image by author
To understand the difference between those components, let's look at a simple example that will demonstrate the difference between an S3 client and an S3 resource. We want to list all objects from the images directory, i.e., all objects with the prefix images/.
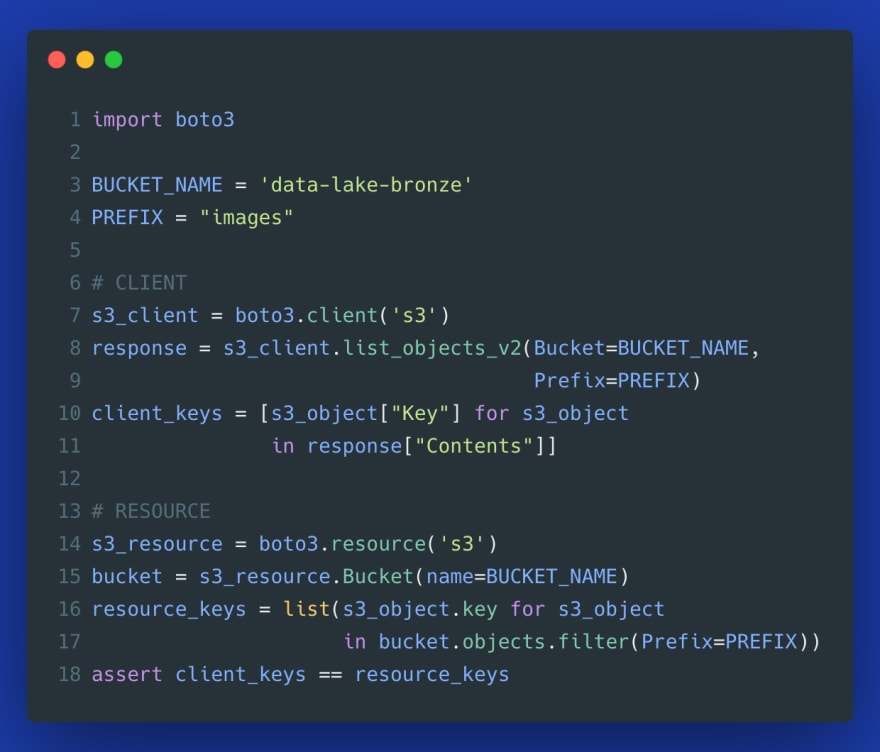
Already by looking at this simple example, you can probably spot the difference:
- with a client, you directly interact with response dictionary from a deserialized API response,
- in contrast, with the resource, you interact with standard Python classes and objects rather than raw response dictionaries.
You can investigate the functionality of resource objects using help() and dir():
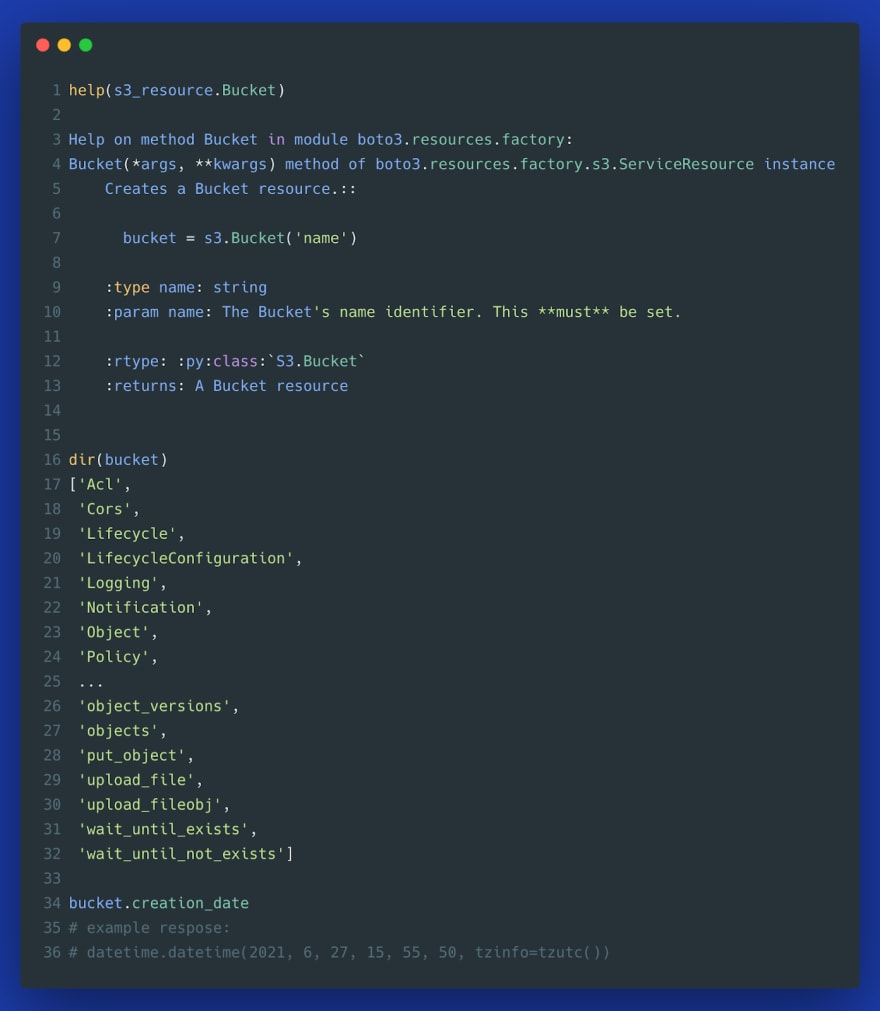
Overall, the resource abstraction results in a more readable code (interacting with Python objects rather than parsing response dictionaries). It also handles many low-level details such as pagination. Resource methods usually return a generator so that you can lazily iterate over a large number of returned objects without having to worry about pagination or running out of memory.
Fun fact: Both, client and resource code, are dynamically generated based on JSON models describing various AWS APIs. For clients, AWS uses JSON service description, and for resource a resource description as a basis for auto-generated code. This facilitates quicker updates and provides a consistent interface across all ways you can interact with AWS (*CLI, boto3, management console). The only real difference between the JSON service description and the final boto3 code is that PascalCase operations are converted to a more Pythonic snake_case notation.*
Imagine that you need to list thousands of objects from an S3 bucket. We could try the same approach we used in the initial code example. The only problem is that s3_client.list_objects_v2() method will allow us to only list a maximum of one thousand objects. To solve this problem, we could leverage pagination:

While the paginator code is easy enough, resource abstraction gets the job done in just two lines of code:

Despite the benefits of resource abstractions, clients provide more functionality, as they map almost 1:1 with the AWS service APIs. Thus, you will most likely end up using both, client and resource, depending on a specific use case.
Apart from a difference in functionality, resources are not thread-safe, so if you plan to use multithreading or multiprocessing to speed up AWS operations such as file uploads, you should use clients rather than resources. More on that here.
Note: There is a way to access client methods directly from a resource object: s3_resource.meta.client.some_client_method().
Waiters are polling the status of a specific resource until it reaches a state that you are interested in. For instance, when you create an EC2 instance using boto3, you may want to wait till it reaches a "Running" state until you can do something with this EC2 instance. Here is a sample code that shows this specific example:

Boto3: using waiter to poll a new EC2 instance for a running state--- image by the author
Note that ImageId from the above example is different for each AWS region. You can find the ID of the AMI by following the "Launch instances" wizard in the AWS console:

Finding the AMI ID --- image by the author
Let's be honest. How often are you launching new instances? Probably not that often. So let's build a more realistic waiter example. Imagine that your ETL process is waiting until a specific file arrives in an S3 bucket. In the example below, we wait until somebody from the marketing department will upload a file with current campaign costs. While you could implement the same with AWS Lambda using an S3 event trigger, the logic below is not tied to Lambda and can run anywhere.

Using waiter in S3 resource --- image by author
Or the same using a more configurable client method:
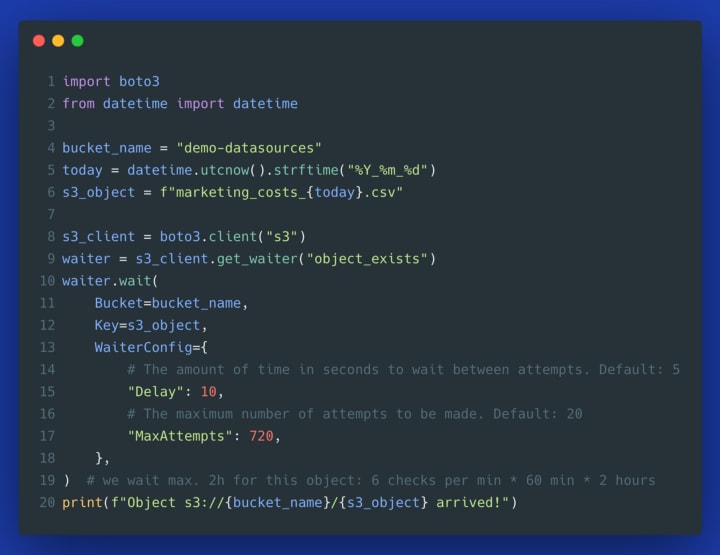
Using waiter in S3 client --- image by author
As you can see from the code snippet above, using the client's waiter abstraction, we can specify:
- MaxAttempts: how many times should we check whether a specific object arrived --- this will prevent zombie processes and will fail if the object hasn't arrived during the time we would expect it to arrive,
- Delay: the number of seconds to wait between each attempt.
As soon as the file arrives in S3, the script stops waiting, which allows you to do something with this newly arrived data.
Collections indicate a group of resources such as a group of S3 objects in a bucket or a group of SQS queues. They allow us to perform various actions on a group of AWS resources in a single API call. Collections can be used to:
- get all S3 objects with a specific object prefix:

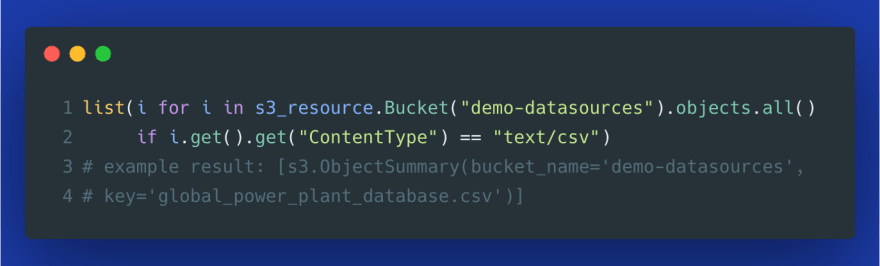
- get all S3 objects with a specific content type, for example, to find all CSV files:
- get all S3 object versions:

- specify a chunk-size of objects to iterate over, for instance when the default page size of 1000 objects is too large for your application:

- delete all objects in a single API call (be careful about that!):

A more common operation is to delete all objects with a specific prefix:

There are many ways you can pass access keys when interacting with boto3. Here is the order of places where boto3 tries to find credentials:
1 - Explicitly passed to boto3.client(), boto3.resource() or boto3.Session():


2 - Set as environment variables:

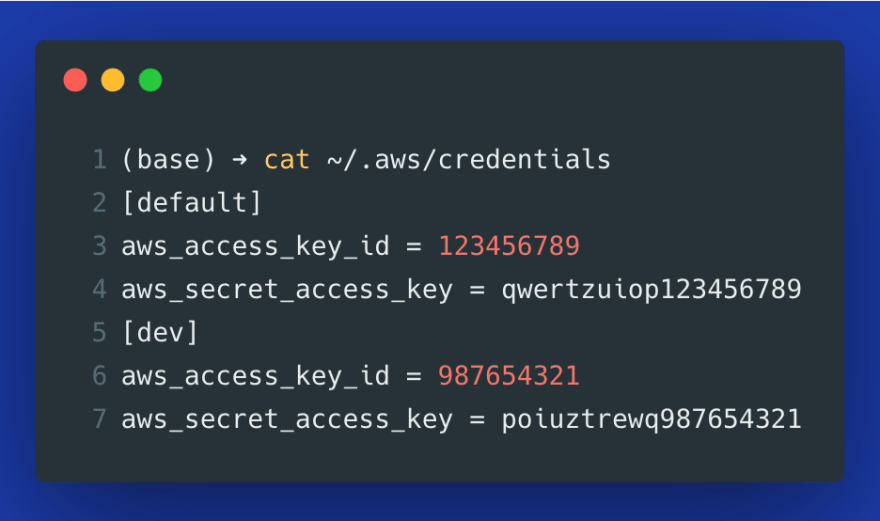
3 - Set as credentials in the ~/.aws/credentials file (this file is generated automatically using aws configure in the AWS CLI):
4 - If you attach* IAM roles* with proper permissions to your AWS resources, you don't have to pass credentials at all but rather assign a policy with required permission scopes. Here is how it looks like in AWS Lambda:

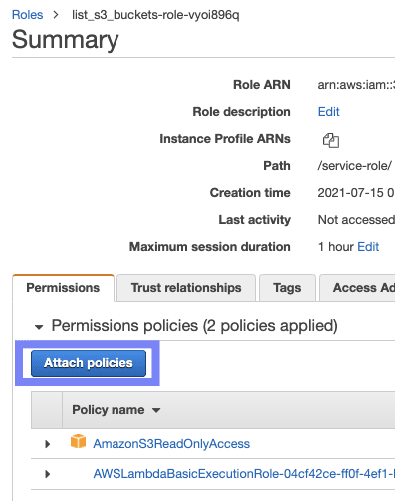
This means that with IAM roles attached to resources such as Lambda functions, you don't need to manually pass or configure any long-term access keys. Instead, IAM roles are dynamically generating temporary access keys, making the process more secure.
If you want to leverage AWS Lambda with Python and boto3 for a specific use case, have a look at the links below:
A useful feature of AWS Lambda is that boto3 is already preinstalled in all Python runtime environments. This way, you can run any of the examples from this article directly in your Lambda function. Just make sure to add proper policy corresponding to the service you want to use in your Lambda's IAM role:

Creating a function in AWS Lambda--- image by author
Testing boto3 from AWS Lambda --- image by author
If you plan to run a number of Lambda functions in production, you may explore Dashbird --- an observability platform that will help you monitor and debug your serverless workloads. It's particularly valuable for building automated alerts on failure, grouping related resources based on a project or domain, providing an overview of all serverless resources, interactively browsing through the logs, and visualizing operational bottlenecks.
The tool is completely free to use and only takes 2 minutes to set up -- and you can start exploring your data immediately.
Overview of all serverless resources provided by Dashbird --- image courtesy by Dashbird.io
Boto3 makes it easy to change the default session. For instance, if you have several profiles (such as one for dev and one for prod AWS environment), you can switch between those using a single line of code:

Alternatively, you can attach credentials directly to the default session, so that you don't have to define them separately for every new client or resource.

In this article, we looked at how to use boto3 and how it is built internally. We examined the differences between clients and resources and investigated how each of them handles pagination. We explored how waiters can help us poll for specific status of AWS resources before proceeding with other parts of our code. We also looked at how collections allow us to perform actions on multiple AWS objects. Finally, we explored different ways of providing credentials to boto3 and how those are handled using IAM roles and user-specific access keys.
Thank you for reading!
References and further reading:
35