
24
Build a customer service chatbot using Python, Flask, and Pinecone
Similarity search is a subset of the machine learning field that deals with finding items that are closely related to the original input. It’s incredibly useful for things like product, music, or movie recommendations. You watched The Office on Netflix, so here are some other shows you may like. You frequently listen to Bayside on Spotify, so go check out these other pop-punk bands.
Similarity search can also be used to automate customer support. What if when a customer asks a question, you could easily find previously asked similar questions and answers that could help them?
In this article, we’ll build a Python Flask app that uses Pinecone — a managed similarity search service — to do just that.
Before we jump into the demo app, let’s take a minute to examine the problem we’re trying to solve. Imagine you’re an executive at a large company with thousands or even millions of customers. Your customer support team is repeatedly asked the same questions day after day. To save time and money, you could streamline your support process by having good public-facing documentation and FAQ pages. But how can you ensure that customers find the information they need? After all, creating the documentation is only half the battle.
One approach that many companies take is to use a customer service chatbot. When a customer first initiates a conversation, they’re chatting with a robot. The customer enters their question and the bot tries to help solve their problem. If the bot can respond with accurate, related questions and answers, then the customer may be able to solve their problem on their own. And if that doesn’t work, then the customer can request to speak with an actual human being who can help. Artificial intelligence and machine learning can’t solve all of our problems — at least not yet.
Let’s now take a look at our demo app. Below you can see a brief animation of how the app works. The user enters a question and submits the form, and then related questions appear in hopes of answering the user’s original question.
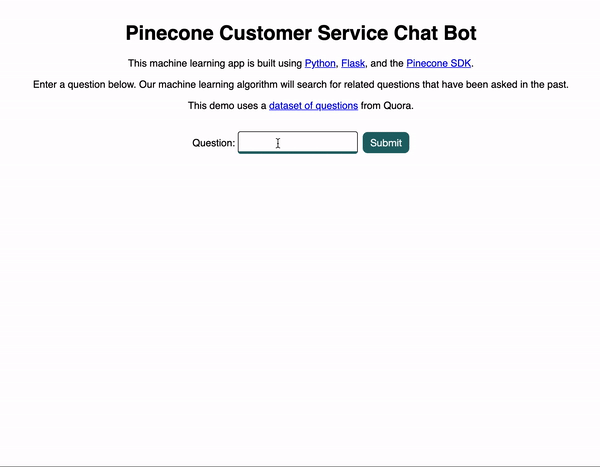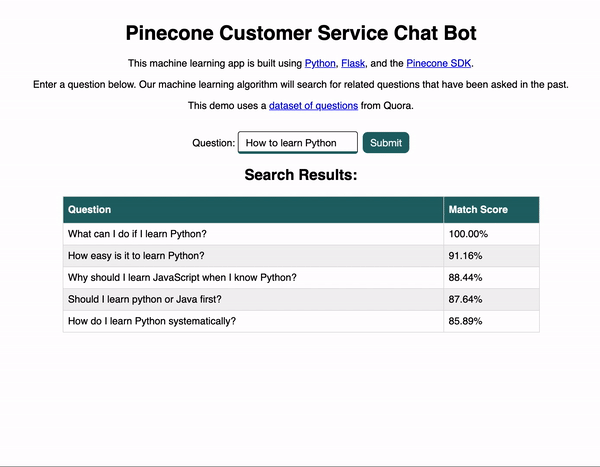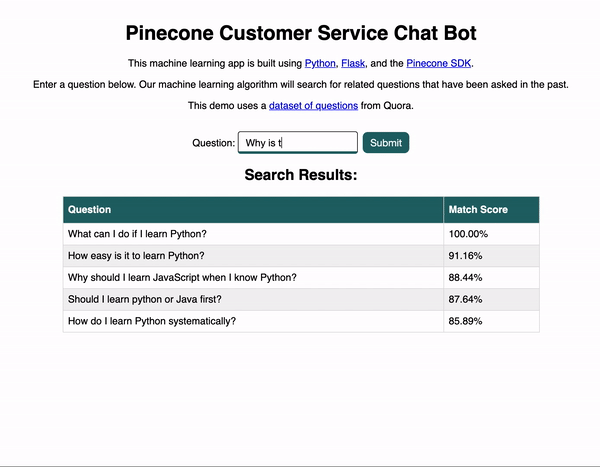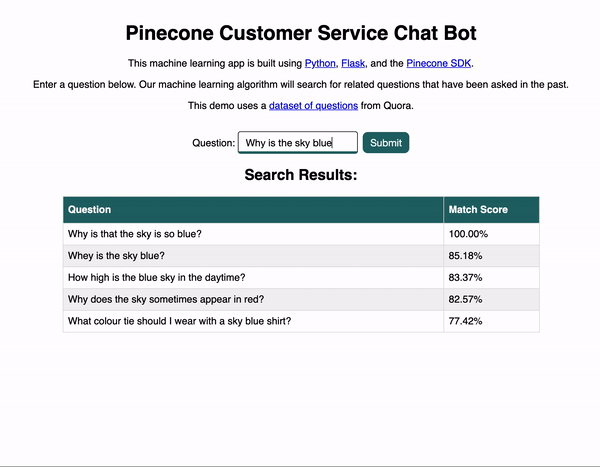
Pretty neat, right? So how does this all work?
In building the app, we first found a dataset of questions and answers from Quora. This dataset contains hundreds of thousands of questions, but we’re just using the first 50,000. We then took those questions and ran them through an embedding model to create what are called vector embeddings. A vector embedding is essentially a list of numbers that provides metadata for machine learning algorithms to determine similarities between various inputs. We used the Average Word Embeddings Model. We then inserted these vector embeddings into an index managed by Pinecone.
Now, when the user submits their question, a request is made to an API endpoint that uses Pinecone’s SDK to query the index of vector embeddings. The endpoint returns five similar questions, and those results are displayed to the user in the app’s UI.
In other words, Pinecone — as a managed similarity search solution — provides the engine for returning recommendations. You just bring your vector embeddings, which are generated by running data through an embedding model.
If you’d like to try it out for yourself, you can find the code for this app on GitHub. The
README contains instructions for how to run the app locally on your own machine.Now that we understand the motivation behind the project and have a high-level overview of how the app works, let’s dig into the actual code to see what’s going on under the hood. To keep things simple, all of the backend code is found in the
app.py file, which we’ve reproduced in full below:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| from dotenv import load_dotenv | |
| from flask import Flask | |
| from flask import render_template | |
| from flask import request | |
| from flask import url_for | |
| import json | |
| import os | |
| import pandas as pd | |
| import pinecone | |
| import requests | |
| from sentence_transformers import SentenceTransformer | |
| app = Flask(__name__) | |
| pinecone_index_name = "question-answering-chatbot" | |
| DATA_DIR = "tmp" | |
| DATA_FILE = f"{DATA_DIR}/quora_duplicate_questions.tsv" | |
| DATA_URL = "https://qim.fs.quoracdn.net/quora_duplicate_questions.tsv" | |
| def initialize_pinecone(): | |
| load_dotenv() | |
| PINECONE_API_KEY = os.environ["PINECONE_API_KEY"] | |
| pinecone.init(api_key=PINECONE_API_KEY) | |
| def delete_existing_pinecone_index(): | |
| if pinecone_index_name in pinecone.list_indexes(): | |
| pinecone.delete_index(pinecone_index_name) | |
| def create_pinecone_index(): | |
| pinecone.create_index(name=pinecone_index_name, metric="cosine", shards=1) | |
| pinecone_index = pinecone.Index(name=pinecone_index_name) | |
| return pinecone_index | |
| def download_data(): | |
| os.makedirs(DATA_DIR, exist_ok=True) | |
| if not os.path.exists(DATA_FILE): | |
| r = requests.get(DATA_URL) | |
| with open(DATA_FILE, "wb") as f: | |
| f.write(r.content) | |
| def read_tsv_file(): | |
| df = pd.read_csv( | |
| f"{DATA_FILE}", sep="\t", usecols=["qid1", "question1"], index_col=False | |
| ) | |
| df = df.sample(frac=1).reset_index(drop=True) | |
| df.drop_duplicates(inplace=True) | |
| return df | |
| def create_and_apply_model(): | |
| model = SentenceTransformer("average_word_embeddings_glove.6B.300d") | |
| df["question_vector"] = df.question1.apply(lambda x: model.encode(str(x))) | |
| pinecone_index.upsert(items=zip(df.qid1, df.question_vector)) | |
| return model | |
| def query_pinecone(search_term): | |
| query_question = str(search_term) | |
| query_vectors = [model.encode(query_question)] | |
| query_results = pinecone_index.query(queries=query_vectors, top_k=5) | |
| res = query_results[0] | |
| results_list = [] | |
| for idx, _id in enumerate(res.ids): | |
| results_list.append({ | |
| "id": _id, | |
| "question": df[df.qid1 == int(_id)].question1.values[0], | |
| "score": res.scores[idx], | |
| }) | |
| return json.dumps(results_list) | |
| initialize_pinecone() | |
| delete_existing_pinecone_index() | |
| pinecone_index = create_pinecone_index() | |
| download_data() | |
| df = read_tsv_file() | |
| model = create_and_apply_model() | |
| @app.route("/") | |
| def index(): | |
| return render_template("index.html") | |
| @app.route("/api/search", methods=["POST", "GET"]) | |
| def search(): | |
| if request.method == "POST": | |
| return query_pinecone(request.form.question) | |
| if request.method == "GET": | |
| return query_pinecone(request.args.get("question", "")) | |
| return "Only GET and POST methods are allowed for this endpoint" |
Let’s break down what’s happening here, method by method, line by line.
On lines 1–11, we import our app’s dependencies. Our app relies on the following:
dotenv for reading environment variables from the .env fileflask for the web application setupjson for working with JSONos also for getting environment variablespandas for working with the datasetpinecone for working with the Pinecone SDKrequests for making API requests to download our datasetsentence_transformers for our embedding modelOn line 13, we provide some boilerplate code to tell Flask the name of our app.
On lines 15–18, we define some constants that will be used in the app. These include the name of our Pinecone index, the directory in which we’ll store our question data, the file name of the dataset, and the URL from which we’ll download the dataset.
On lines 20–23, our
initialize_pinecone method gets our API key from the .env file and uses it to initialize Pinecone.On lines 25–27, our
delete_existing_pinecone_index method searches our Pinecone instance for indexes with the same name as the one we’re using (“question-answering-chatbot”). If an existing index is found, we delete it.On lines 29–33, our
create_pinecone_index method creates a new index using the name we chose (“question-answering-chatbot”), the “cosine” proximity metric, and only one shard.On lines 35–41, our
download_data method downloads the dataset of Quora question-answers pairs if needed. If the file already exists in the tmp directory, then we just use that file.On lines 43–50, our
read_tsv_file method reads the TSV file using the pandas library and inserts each row into a data frame. We also remove any duplicate questions found in the dataset.On lines 52–57, our
create_and_apply_model method uses the sentence_transformers library to work with the Average Word Embeddings Model. We then create a vector embedding for each question by encoding it using our model. The vector embeddings are then inserted into the Pinecone index.Each of the methods we’ve described so far is called on lines 77–82 when the backend app is started. This work prepares us for the final step of actually querying the Pinecone index based on user input.
On lines 84–94, we define two routes for our app: one for the home page and one for the API endpoint. The home page serves up the
index.html template file along with the JS and CSS assets, and the API endpoint provides the search functionality for querying the Pinecone index.Finally, on lines 59–75, our
query_pinecone method takes the user’s input, converts it into a vector embedding, and then queries the Pinecone index to find similar questions. This method is called when the /api/search endpoint is hit, which occurs any time the user submits a new search query.For the visual learners out there, here’s a diagram outlining how the app works:
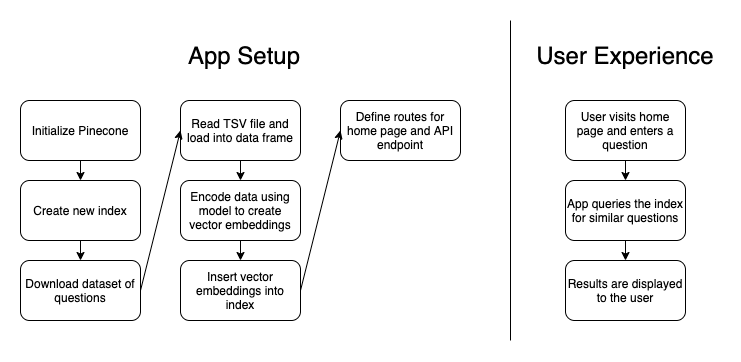
So, putting this all together, what does the user experience look like?
A user could visit our site, enter the question “How to learn Python”, find similar questions that have been asked in the past, and then click on the links to see the questions and answers on Quora.
Following along with our customer service scenario, a user might ask a question about how to use our company’s product, find similar questions, click on a link, and be directed to a helpful support page that answers their question, all without interacting with a support representative.
We’ve now created a simple Python app to solve a real-world problem. To make this app even better, we could include new questions and answers to our index every time a question is asked. We could also use customer feedback to fine-tune the model to learn whether the returned results are relevant or not. After all, feedback is what helps the model get better at providing useful results.
The moral of the story should be clear: Similarity search helps provide better results to your customers. And as a managed service, Pinecone makes it easy to take vector-based recommendation systems to production.
24