
33
Product developers’ guide to getting started with AI — Part 1: Introduction to dataframes
When working with AI, it’s important to know how to import data sets, read through tables, and understand what the structure is.
Welcome to the “Product developers' guide to getting started with AI”. In this series, we’ll go over key concepts and run through examples using Pandas. First, we will cover setting up your development environment and learning how to inspect your data. Then, you’ll be ready to tackle the more exciting parts of AI throughout this series.
For the most part, Google Collab has everything already installed except the dataset, skip to My First Dataframe. However, if you want to run it locally then follow the next step. We’ll be using:
When getting started with AI, 2 important libraries you’ll be using every day are Pandas and Numpy. Follow the link here for instructions to install Python, Pandas, NumPy, and access to Google Collab.
First, we’ll begin by going through how to upload files and download our first data set, the Titanic, hosted by the Pandas community on Github.
Open up Google Collab and click on the new notebook button.
Open up Google Collab and click on the new notebook button.
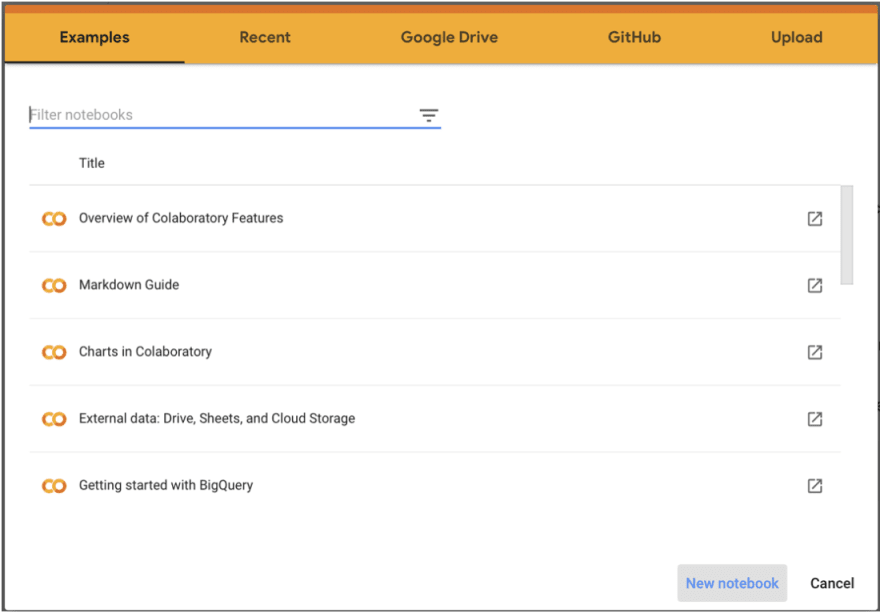
Next, we’ll begin by importing titanic.csv to create your first dataframe. Go to the file tab, and click on the file with the arrow to upload from your computer.
Then import Pandas, Numpy, and use read_csv to extract our CSV data into a dataframe.

Type the name of the dataframe to view it. Here we call it df, so in the next cell we type df. To run the cell use Shift+Enter or click the run icon at the left.

Unlike a table, a dataframe has some extra data behind the scenes, called metadata. Metadata is used to organize its structure and can be viewed in Pandas by using the describe, info, and columns method. Let’s say we wanted to know how many rows and columns contain non-empty values or how much storage the data takes up.

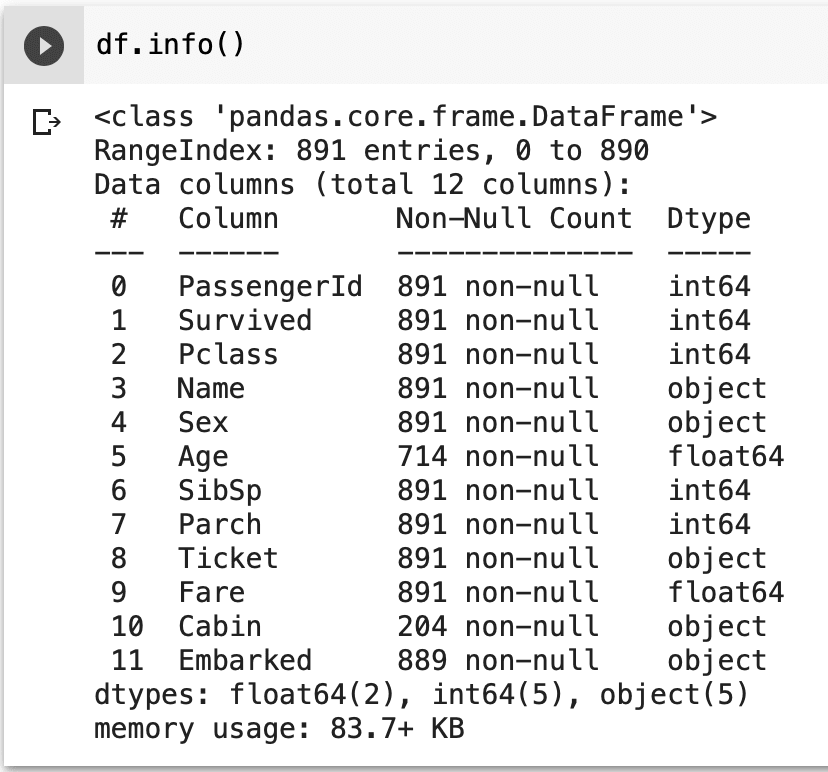
Info is a great method that product developers who have worked with SQL will find similar to the EXPLAIN command. It tells us valuable information about the storage space used, column information, number of rows, indices, and types. All while organizing it into an easy-to-read table.
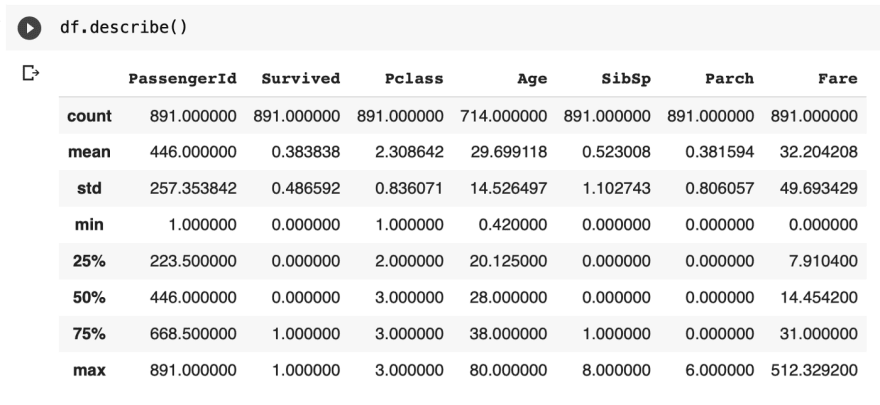
Describe is a method best used to summarize the numerical data by calculating a quick mathematical summary and displaying the count, mean, min, max, standard deviation, and percentiles.
This is by default equivalent to df.describe(include=[np.number])
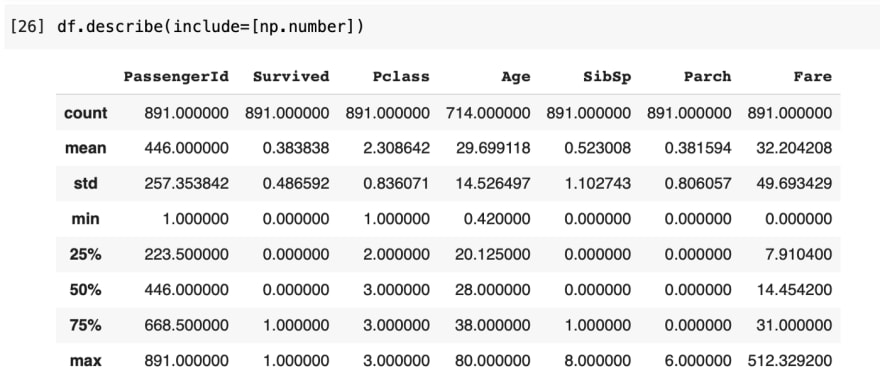
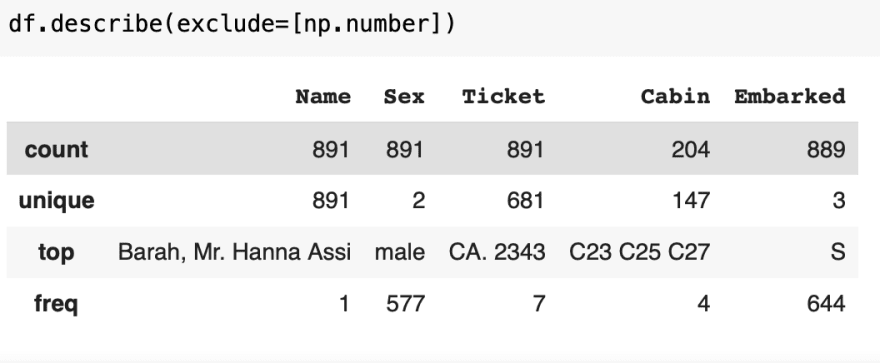
By adding the object keyword, describe looks for the unique, top, and frequency of the data for object data, such as strings and timestamps instead. Here, it selects the columns that have a data type of object from the output.

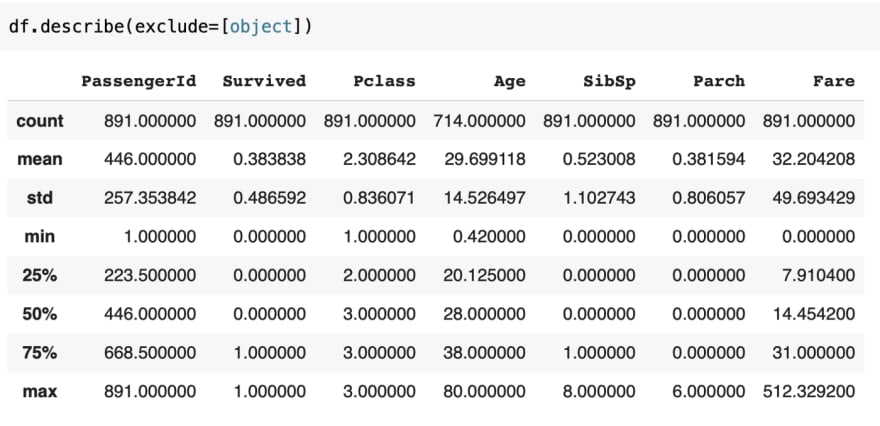
Conversely, you may also use exclude instead of include to get the reverse outputs.
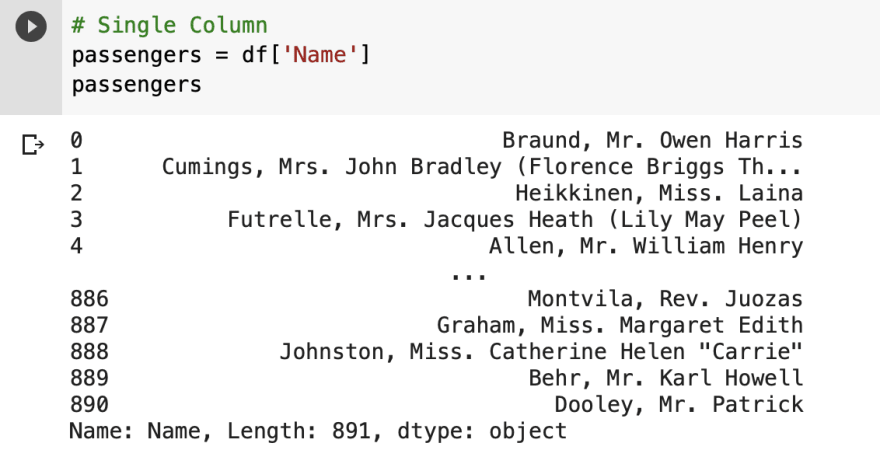
But, columns is an interesting method that is used to read metadata and select data. To get the metadata of a column, call it on a dataframe to get the index names.

There are two ways to select a column, using either the index position or index name. The index position can be found from the metadata of info on the left.

The index name can be found from the output of columns.
But most of the time, especially when working with AI, you’ll have very large datasets and it may not be feasible or necessary to display everything. Dataframes have other features to view parts of the data, by using the head, tail, loc, and iloc method.

Let’s take a look using indexing with the head or tail method.
To view the data on the first 5 rows, we use head(5)

Then, to view the data for the last 5 rows, we use tail(5)

We can view multiple columns using loc, specifying the row index found on the left of the dataframe, along with the names of the columns to view. Since our row index is unlabeled, we use integers to quickly access them. The ‘:’ command is to set a range of values, to include everything.

Similarly to loc, you can also use the index position with the iloc command instead.
Combining what we’ve learned, let’s answer common data analysis questions about the Titanic dataset that data scientists and marketing ask themselves every day.
How many people were aboard the Titanic when it sank?
That covers the info, describe, and columns functions for reading metadata and head, tail, loc, and iloc for viewing dataframes. Check back next week for our next guide, “Surfing through dataframes”, where we’ll be taking a look at how to search through our imported data by grouping, ordering, and rearranging the dataframe’s structure.
33