
24
Data-Oriented Programming is dope
Photo by Ravi Roshan on Unsplash.
This post was published first in https://techblog.deepki.com/data-oriented-programming/. This is an English translation by the same author.
Data-oriented programming (DOP) is not a new concept. It's a paradigm that can be used by developers in any programming language, it's purpose is to reduce complexity of information system that they are designing.
The narrator is a junior javascript developer, he develops a Library Management System of a client. Initial features are easy, the software is coded in object oriented. But when the client asks for some new features at the very last moment, everything becomes complicated. He seeks support from a veteran developper, Joe.
Throughout these pages Joe demonstrates difficulties he encounters, shows him how to confront them. In fine, he teaches him a new way to organize his source code that is more easy to decipher and to evolve.
Examples in the book are in Javascript, I wanted to introduce my interpretation in Python on a small part of these rules: code and data separation.
In the book, the heroes talk about user management. The narrator had to design two types of users, the librarian and the member:
Once this logic implemented, the client requested him to add super members, then VIP members.
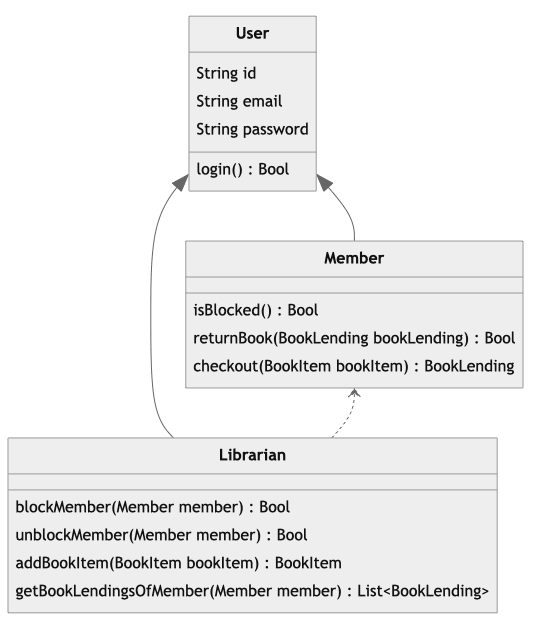
It achieves to be this UML class diagram:

It's really hard to manage for the young narrator. Although everything is perfectly logic, the classes hierarchy is hard to work with, mixing inheritance with dependencies.
Joe understands affirms that is "feelings" are due to « Data encapsulation has its merits and drawbacks: Think about the way you designed the Library Management System. According to DOP, the main cause of the complexity of systems and their lack of flexibility is because code and data are mixed together in objects »
That's what Yehonathan Sharvit fights all along the book: he depicts the difficulty to just understand something and be able to upgrade it without difficulties.
Complexity is a thing that have been accumulated insidiously. When it's not kept under control, implementing new features can take weeks instead of days. But DO comes with a radical approch to fight this complexity. To achieve this, data and code must be separated:

In order to explain this separation, here is my implementation in python.
I've followed technics that are described in the book. I started from the client specifications, I've made a list of names that seem to represent Entities of the system, and another list of everything that look like a feature. Then I've organized what I've found:
- Two kind of users: members and librarians
- Users log in to the system via email and password
- Members can borrow books
- Members and librarians can search books by title or by author
- Librarians can block and unblock members
- Librarians can list the books currently lent by a member
- There could be several copies of a book
Entities classified by groups:

Features put in several code modules:

On this basis, I will implement book lending.
The catalog's data part:
$schema: "https://json-schema.org/draft/2020-12/schema"
properties:
lendings:
additionalProperties:
type: object
properties:
id: { type: string }
user_id: { type: string, format: uuid }
book_item_id: { type: string }
required: [id, user_email, book_item_id]
propertyNames: { type: string, format: uuid }
required: [lendings]The user_management's data part:
$schema: "https://json-schema.org/draft/2020-12/schema"
properties:
members_by_id:
type: object
additionalProperties:
type: object
properties:
is_blocked: { type: boolean }
required: [is_blocked]
propertyNames: { type: string, format: uuid }
required: [members_by_id]Here I've used JSON Schema, because data does not have to be contained in rigid structures. Only the keys are relevant and need to be specified. In DO, data requires to obey three other rules:
- all types are generic
- all types are immutable
- shape of data and data schema are separated
Here is a mock that validates these two schemas:
library_data = {
"catalog": {
"books_by_isbn": {
"9781234567897": {
"title": "Data Oriented Programming",
"author": "Yehonathan Sharvit",
}
},
"book_items_by_id": {
"book-item-1": {
"isbn": "9781617298578",
},
"book-item-2": {
"isbn": "9781617298578",
}
},
"lendings": [
{
"id": "...",
"user_id": "member-1",
"book_item_id": "book-item-1",
}
],
},
"user_management": {
"members_by_id": {
"member-1": {
"id": "member-1",
"name": "Xavier B.",
"email": "[email protected]",
"password": "aG93IGRhcmUgeW91IQ==",
"is_blocked": False,
}
}
},
}By convention, dict are used like some Mapping, and I forbid myself to update them.
Please note that examples will use the classes+static method form in order to make this article readable. In a production code, the modules+functions form is the way to go.
And now the code part:
from __future__ import annotations
from typing import Tuple, TypeVar
from uuid import uuid4
T = TypeVar("T")
class Library:
@staticmethod
def checkout(library_data: T, user_id, book_item_id) -> tuple[T, dict]:
user_management_data = library_data["user_management"]
if not UserManagement.is_member(user_management_data, user_id):
raise Exception("Only members can borrow books")
if UserManagement.is_blocked(user_management_data, user_id):
raise Exception("Member cannot borrow book because he is bloqued")
catalog_data = library_data["catalog"]
if not Catalog.is_available(catalog_data, book_item_id):
raise Exception("Book is already borrowed")
catalog_data, lending = Catalog.checkout(catalog_data, book_item_id, user_id)
return (
library_data | {
"catalog": catalog_data,
},
lending,
)
class UserManagement:
@staticmethod
def is_member(user_management_data: T, user_id) -> bool:
return user_id in user_management_data["members_by_id"]
@staticmethod
def is_blocked(user_management_data: T, user_id) -> bool:
return user_management_data["members_by_id"][user_id]["is_blocked"] is True
class Catalog:
@staticmethod
def is_available(catalog_data: T, book_item_id) -> bool:
lendings = catalog_data["lendings"]
return all(lending["book_item_id"] != book_item_id for lending in lendings)
@staticmethod
def checkout(catalog_data: T, book_item_id, user_id) -> Tuple[T, dict]:
lending_id = uuid4().__str__()
lending = {"id": lending_id, "user_id": user_id, "book_item_id": book_item_id}
lendings = catalog_data["lendings"]
return (
catalog_data | {
"lendings": lendings + [lending]
},
lending
)As we can see, code is a series of pure functions.
Functions that modify a state return a new state object rather than upgrading the previous state.
In each module, functions are made simple and easy to test. They can be reused in any context, like the main module. Globally, they are composed with other existing function. It becomes very easy to adapt them for the client's needs.
And now, which path will data lead if my alter-ego borrows another copy of the book?
library_data, lending = Library.checkout(
library_data,
user_id="member-1",
book_item_id="book-item-2",
)Two things occur:
-
Data is systematically transmitted to every function calls. This object is quite opaque, each level use only a fragment that he knows without worrying about the remaining:
# 1. injects data into Library.checkout module library_data, lending = Library.checkout(library_data, ...) # 2. extracts data from user_management user_management_data = library_data["user_management"] # 3. uses this data fragment into UserManagement module if not UserManagement.is_member(user_management_data, ...): ... if UserManagement.is_blocked(user_management_data, ...): ... # 4. picks catalog data catalog_data = library_data["catalog"] # 5. uses this data fragment into Catalog module if not Catalog.is_available(catalog_data, ...): ... ... = Catalog.checkout(catalog_data, ...) -
When a function is about to change a state, it returns a new version of data. Every level of the call stack must returns a new version of data:
# 1. handles the request in Catalog.checkout lending = ... lendings = catalog_data["lendings"] # 2. creates a new version of catalog_data catalog_data = catalog_data | { "lendings": lendings + [lending] } # 3. interception of the new catalog_data by Library.checkout catalog_data, ... = Catalog.checkout(...) # 4. creation of a new version of library_data library_data = library_data | { "catalog": catalog_data, }Then, this new version of data can be exposed to whole system.
In my example, I don't talk about data consolidation. I suggest you to read the book which gives informations concerning this subject.
Broadly speaking, this paradigm fits well in Python if we shelve the object oriented capabilities of the language.
The notion of modules in data-oriented are naturally superimposed on modules in Python, which facilitates adherence.
Borrowings of functional languages such as map(), filter() as well as functions from standard operator module also contribute to make this paradigm quite natural in Python.
In our example, standard typing will not work. However, it is quite easy to do custom typing, such as:
from __future__ import annotations
from typing import Any, Mapping
class M(Mapping[str, Any]):
def __or__(self, other: dict) -> M:
return {**self, **other} # type: ignore
def __hash__(self) -> int:
...
# which can be used as well in the source code
def my_func(members_data: M[str, M], member_id: str):
member = members_data[member_id]In my implementation my functions are not really pure because I have used exceptions. However, this disgression is acceptable if it is applied under a certain condition. Indeed, exceptions are only used to express illegal operations, in a throw early, catch late way. Using them this way contributes to the readability of the code. The higher layers of the system will know how to deal with them.
For example in a Flask application:
@app.post("/checkout")
def checkout_view():
...
try:
..., lending = Library.checkout(library_data, user_id, book_item_id)
# la fonction 'checkout' peut lever des exceptions
...
return jsonify(lending), 201
except Exception as error:
result = {"error": str(error)}
return jsonify(result), 400The author is also clear that embracing DO comes at a cost. For example, the fact that DO is relatively agnostic of any programming language undermines the guarantees offered by object modeling (or other tools such as code analysis that some IDEs allow). However, he sometimes offers alternatives for this, such as JSON Schema used here.
What I presented to you was just a preview of DOP using pure Python. The author gives a lot of details about unit tests, data structures, state management, structural sharing, atomicity, transformation pipeline, etc.
I highly recommend you to read Data-oriented programming by Yehonathan Sharvit, and please follow his approach in his blog.
The author is a multilingual developer and without citing it, many concepts come from the Clojure language. According to its defenders, Clojure is the easiest programming language in the world because it has almost no syntax or grammar and it was designed by Rich Hickey in such a way as to facilitate code changes.
This language can be inspiring for other languages. To convince yourself, you can consult this other talk Design, Composition, and Performance Short by Rich Hickey.
It makes me happy to see some of these principles reused in other languages. Indeed, languages must nurture on each other.
Bref, making functional code in Python is dope.
24