
35
Don't let dicts spoil your code

How often do your simple prototypes or ad-hoc scripts turn into fully-fledged applications?
The simplicity of organic code growth has a flip side: it becomes too hard to maintain. The proliferation of dicts as primary data structures is a clear signal of tech debt in your code. Fortunately, modern Python provides many viable alternatives to plain dicts.
Functions that accept dicts are a nightmare to extend and modify. Usually, to change the function that takes a dictionary, you must manually trace the calls back to the roots, where this dict was created. There is often more than one call path, and if a program grows without a plan, you'll likely have discrepancies in the dict structures.
Changing dict values to fit a specific workflow is tempting, and programmers often abuse this functionality. In-place mutations may have different names: pre-processing, populating, enriching, data massage, etc. The result is the same. This manipulation hinders the structure of your data and makes it dependent on the workflow of your application.
Not only do dicts allow you to change their data, but they also allow you to change the very structure of objects. You can add or delete fields or change their types at will. Resorting to this is the worst felony you can commit to your data.
A common source of dicts in the code is deserializing from JSON. For example, from a third-party API response.
>>> requests.get("https://api.github.com/repos/imankulov/empty").json()
{'id': 297081773,
'node_id': 'MDEwOlJlcG9zaXRvcnkyOTcwODE3NzM=',
'name': 'empty',
'full_name': 'imankulov/empty',
'private': False,
...
}A dict, returned from the API.
Make a habit of treating dicts as a "wire format" and convert them immediately to data structures providing semantics.
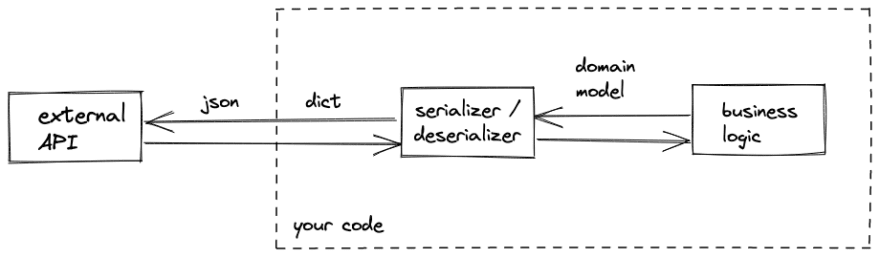
The implementation is straightforward.
- Define your domain models. A domain model is simply a class in your application.
- Fetch and deserialize in the same step.
In Domain-Driven Design (DDD), this pattern is known as the anti-corruption layer. On top of semantic clarity, domain models provide a natural layer that decouples the exterior architecture from your application's business logic.
Two implementations of a function retrieving repository info from GitHub:
❌ Returning a dict
import requests
def get_repo(repo_name: str):
"""Return repository info by its name."""
return requests.get(f"https://api.github.com/repos/{repo_name}").json()The output of the function is opaque and needlessly verbose. The format is defined outside of your code.
>>> get_repo("imankulov/empty")
{'id': 297081773,
'node_id': 'MDEwOlJlcG9zaXRvcnkyOTcwODE3NzM=',
'name': 'empty',
'full_name': 'imankulov/empty',
'private': False,
# Dozens of lines with unnecessary attributes, URLs, etc.
# ...
}✅ Returning a domain model
class GitHubRepo:
"""GitHub repository."""
def __init__(self, owner: str, name: str, description: str):
self.owner = owner
self.name = name
self.description = description
def full_name(self) -> str:
"""Get the repository full name."""
return f"{self.owner}/{self.name}"
def get_repo(repo_name: str) -> GitHubRepo:
"""Return repository info by its name."""
data = requests.get(f"https://api.github.com/repos/{repo_name}").json()
return GitHubRepo(data["owner"]["login"], data["name"], data["description"])>>> get_repo("imankulov/empty")
<GitHubRepo at 0x103023520>While the example below has more code, this solution is better than the previous one if we maintain and extend the codebase.
Let's see what the differences are.
- The data structure is clearly defined, and we can document it with as many details as necessary.
- The class also has a method
full_name()implementing some class-specific business logic. Unlike dicts, data models allow you to co-locate the code and data. - GitHub API's dependency is isolated in the function
get_repo(). The GitHubRepo object doesn't need to know anything about the external API and how objects are created. This way, you can modify the deserializer independently from the model or add new ways of creating objects: from pytest fixtures, the GraphQL API, the local cache, etc.
☝️ Ignore fields coming from the API if you don't need them. Keep only those that you use.
In many cases, you can and should ignore most of the fields coming from the API, adding only the fields that the application uses. Not only duplicating the fields is a waste of time, but it also makes the class structure rigid, making it hard to adopt changes in the business logic or add support to the new version of the API. From the point of view of testing, fewer fields mean fewer headaches in instantiating the objects.
Wrapping dicts require creating a lot of classes. You can simplify your work by employing a library that makes "better classes" for you.
Starting from version 3.7, Python provides Data Classes. The dataclasses module of the standard library provides a decorator and functions for automatically adding generated special methods such as __init__() and __repr__() to your classes. Therefore, you write less boilerplate code.
I use dataclasses for small projects or scripts where I don't want to introduce extra dependencies. That's how the GitHubRepo model looks like with dataclasses.
from dataclasses import dataclass
@dataclass(frozen=True)
class GitHubRepo:
"""GitHub repository."""
owner: str
name: str
description: str
def full_name(self) -> str:
"""Get the repository full name."""
return f"{self.owner}/{self.name}"When I create Data Classes, my Data Classes are almost always defined as frozen. Instead of modifying an object, I create a new instance with dataclasses.replace(). Read-only attributes bring peace of mind to a developer, reading and maintaining your code.
Recently Pydantic, a third-party data-validation library became my go-to choice for model definition. Compared with dataclasses, they are much more powerful. I especially like their serializers and deserializers, automatic type conversions, and custom validators.
Serializers simplify storing records to external storage, for example, for caching. Type conversions are especially helpful when converting a complex hierarchical JSON to a hierarchy of objects. And validators are helpful for everything else.
With Pydantic, the same model can look like this.
from pydantic import BaseModel
class GitHubRepo(BaseModel):
"""GitHub repository."""
owner: str
name: str
description: str
class Config:
frozen = True
def full_name(self) -> str:
"""Get the repository full name."""
return f"{self.owner}/{self.name}"You can find some examples of me using Pydantic, in my post Time Series Caching with Python and Redis.
Python 3.8 introduced so-called TypedDicts. In runtime, they behave like regular dicts but provide extra information about their structure for developers, type validators, and IDEs.
If you come across the dict-heavy legacy code and can't refactor everything yet, at least you can annotate your dicts as typed ones.
from typing import TypedDict
class GitHubRepo(TypedDict):
"""GitHub repository."""
owner: str
name: str
description: str
repo: GitHubRepo = {
"owner": "imankulov",
"name": "empty",
"description": "An empty repository",
}Below, I provide two screenshots from PyCharm to show how adding typing information can streamline your development experience with the IDE and protect you against errors.


A legitimate use-case of dict is a key-value store where all the values have the same type, and keys are used to look up the value by key.
colors = {
"red": "#FF0000",
"pink": "#FFC0CB",
"purple": "#800080",
}
When instantiating or passing such dict to a function, consider hiding implementation details by annotating the variable type as Mapping or MutableMapping. On the one hand, it may sound like overkill. Dict is default and by far the most common implementation of a MutableMapping. On the other hand, by annotating a variable with mapping, you can specify the types for keys and values. Besides, in the case of a Mapping type, you send a clear message that an object is supposed to be immutable.
Example
I defined a color mapping and annotated a function. Notice how the function uses the operation allowed for dicts but disallowed for Mapping instances.
# file: colors.py
from typing import Mapping
colors: Mapping[str, str] = {
"red": "#FF0000",
"pink": "#FFC0CB",
"purple": "#800080",
}
def add_yellow(colors: Mapping[str, str]):
colors["yellow"] = "#FFFF00"
if __name__ == "__main__":
add_yellow(colors)
print(colors)Despite wrong types, no issues in runtime.
$ python colors.py
{'red': '#FF0000', 'pink': '#FFC0CB', 'purple': '#800080', 'yellow': '#FFFF00'}To check the validity, I can use mypy, which raises an error.
$ mypy colors.py
colors.py:11: error: Unsupported target for indexed assignment ("Mapping[str, str]")
Found 1 error in 1 file (checked 1 source file)Keep an eye on your dicts. Don't let them take control of your application. As with every piece of technical debt, the further you postpone introducing proper data structures, the more complex the transition becomes.
35