
26
Machine Learning Descomplicado
generated with Summaryze Forem 🌱
Quando se fala em tecnologia, um termo que está na boca do povo é aprendizado de máquina (machine learning em inglês). Mas o que exatamente é isso? Uma busca simples no Google, retorna uma multitude de artigos, fóruns, documentos, fontes.
Existem inúmeras definições sobre o que é o aprendizado de máquina, mas uma que nos serve bastante por agora é: “A pesquisa em aprendizado de máquina é um campo de estudo dentro da pesquisa em inteligência artificial, que busca fornecer conhecimento aos computadores através de dados, observações e interações com o mundo. Esse conhecimento adquirido permite que computadores generalizem corretamente novos eventos e configurações”.
Sendo assim, o intuito deste post é introduzir você que está lendo, a esse mundo maravilhoso que será nosso futuro. Hoje, você aprenderá como abrir um dado e visualizar as principais informações dele.
Agora que você está introduzido neste mundo, vamos nos preparar para começarmos nossa exploração. Primeiro, precisamos definir qual será nossa base de dados, para este projeto, fiz uma adaptação na base de dados chamada de credit data, hospedada no site Kaggle.
Após baixar a base, vamos importar as bibliotecas que utilizaremos durante todo o processo.
Usaremos a biblioteca pandas e numpy para o processamento dos dados e cálculos estatísticos. A seaborn, matplotlib e a ploty, usamos na parte da visualização dos dados. Tudo explicado, agora vamos importar as bibliotecas no nosso código:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import plotly.express as pxSempre que importamos uma biblioteca, passamos um apelido para ela, para que fique mais fácil nossa utilização, e é isso que o as pd, as np, e os demais significam.
Após importado as bibliotecas, vamos finalmente abrir nossa base pela primeira vez. Para isso, utilizaremos a biblioteca pandas e seu método read_csv.
base_credit = pd.read_csv('credit_data.csv')Adicionamos esse método em uma variável, e passamos o path do arquivo como parâmetro.
Agora vamos fazer nossa primeira visualização, para isso, utilizaremos o comando .head() do próprio pandas. Ele nos retornará as 5 primeiras linhas do arquivo.
base_credit.head()Saída: 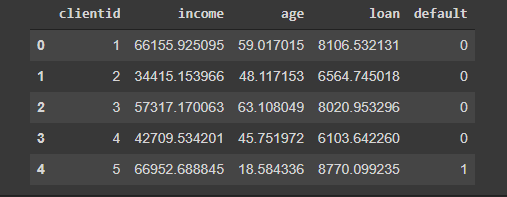
Podemos ver que temos uma tabela, com 6 colunas.
- A primeira coluna corresponde ao índice da nossa tabela, qual o tamanho dela;
- A segunda coluna (clientid) corresponde ao id do cliente;
- A terceira coluna (income) corresponde ao salário do respectivo cliente ao ano.
- A quarta coluna (age), mostra a idade do cliente;
- A quinta coluna (loan), representa o valor da dívida que o cliente está devendo;
- E por ultimo, a sexta coluna, representa se o cliente quitou, ou não, a dívida. Esses valores são representados por 1 e 0, respectivamente.
Para fazer a exploração, utilizaremos o comando describe, do pandas. Ele retornará diversas informações estatísticas dos valores números existentes na nossa tabela.
base_credit.describe()Saída: 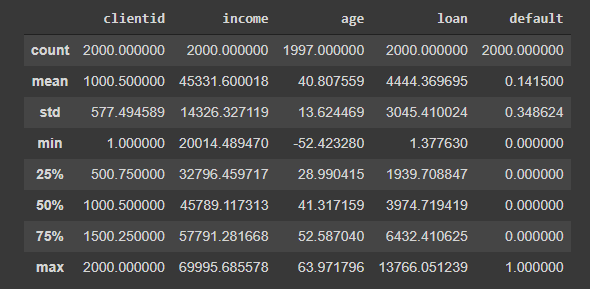
Com esse comando podemos observar a quantidade de linhas contidas na tabela, a média de cada uma das colunas, o desvio padrão, o valor mínimo encontrado, o primeiro quartil de 25%, a mediana, o segundo quartil de 75% e o valor máximo encontrado.
E aqui finalizamos o post de hoje. Neste post, foi mostrado uma ideia geral sobre machine learning e os primeiros passos para construir um projeto nesta área. Ao longo da semana as demais partes irão sair, espero que acompanhem! Até a próxima!!
26