

20
Notes on Kafka: Topics, Partitions, and Offset
In the previous section, we have installed the Kafka and all the required pre-requisites in our machine. You can skip some part of this section that you're already familiar with, but basically we'll be going over:
Recall that we've created the Kafka files directory in /usr/local/bin and copied the extracted contents of the Kafka tarball we downloaded. Note that Kafka the files directory or the Kafka program can be ran from any directory you prefer.
root:kafka_2.13-2.7.0 $ ls -l
total 56
drwxr-xr-x 3 root root 4096 Dec 16 2020 bin
drwxr-xr-x 2 root root 4096 Jun 23 15:05 config
drwxr-xr-x 4 root root 36 Jun 23 15:05 data
drwxr-xr-x 2 root root 8192 Jun 23 15:05 libs
-rw-r--r-- 1 root root 29975 Dec 16 2020 LICENSE
-rw-r--r-- 1 root root 337 Dec 16 2020 NOTICE
drwxr-xr-x 2 root root 44 Dec 16 2020 site-docsThe site-docs contains an archive of all the documentation that's available online.
The libs folder contains on the dependencies needed by Kafka to run.
You'll notice at bottom section that there's an archive for zookeeper and its client library. Kafka can be a self-contained installation and does not require ZooKeeper to be pre-installed.
# Please note that some of the contents are omitted to shorten output
root:kafka_2.13-2.7.0 $ ls -l libs/
total 67052
-rw-r--r-- 1 root root 69409 May 28 2020 activation-1.1.1.jar
-rw-r--r-- 1 root root 27006 Jun 30 2020 aopalliance-repackaged-2.6.1.jar
-rw-r--r-- 1 root root 90347 May 28 2020 argparse4j-0.7.0.jar
-rw-r--r-- 1 root root 20437 Dec 20 2019 audience-annotations-0.5.0.jar
-rw-r--r-- 1 root root 53820 Dec 20 2019 commons-cli-1.4.jar
-rw-r--r-- 1 root root 501879 May 28 2020 commons-lang3-3.8.1.jar
-rw-r--r-- 1 root root 12211 Jan 22 2020 slf4j-log4j12-1.7.30.jar
-rw-r--r-- 1 root root 1945847 Oct 21 2020 snappy-java-1.1.7.7.jar
-rw-r--r-- 1 root root 991098 May 27 2020 zookeeper-3.5.8.jar
-rw-r--r-- 1 root root 250547 May 27 2020 zookeeper-jute-3.5.8.jar
-rw-r--r-- 1 root root 5355050 Aug 12 2020 zstd-jni-1.4.5-6.jarThe config contains all the configuration files for Kafka. Here you can see server.properties. This is the configuration file for the Kafka broker.
root:kafka_2.13-2.7.0 $ ll config/
total 72
-rw-r--r-- 1 root root 906 Dec 16 2020 connect-console-sink.properties
-rw-r--r-- 1 root root 909 Dec 16 2020 connect-console-source.properties
-rw-r--r-- 1 root root 5321 Dec 16 2020 connect-distributed.properties
-rw-r--r-- 1 root root 883 Dec 16 2020 connect-file-sink.properties
-rw-r--r-- 1 root root 881 Dec 16 2020 connect-file-source.properties
-rw-r--r-- 1 root root 2247 Dec 16 2020 connect-log4j.properties
-rw-r--r-- 1 root root 2540 Dec 16 2020 connect-mirror-maker.properties
-rw-r--r-- 1 root root 2262 Dec 16 2020 connect-standalone.properties
-rw-r--r-- 1 root root 1221 Dec 16 2020 consumer.properties
-rw-r--r-- 1 root root 4674 Dec 16 2020 log4j.properties
-rw-r--r-- 1 root root 1925 Dec 16 2020 producer.properties
-rw-r--r-- 1 root root 6876 Jun 23 15:05 server.properties
-rw-r--r-- 1 root root 1032 Dec 16 2020 tools-log4j.properties
-rw-r--r-- 1 root root 1169 Dec 16 2020 trogdor.conf
-rw-r--r-- 1 root root 1237 Jun 23 15:05 zookeeper.propertiesLastly, the bin contains all the programs you cna execute to get Kafka up and running.
# Please note that some of the contents are omitted to shorten output
root:kafka_2.13-2.7.0 $ ll bin/
total 144
-rwxr-xr-x 1 root root 1423 Dec 16 2020 connect-distributed.sh
-rwxr-xr-x 1 root root 1396 Dec 16 2020 connect-mirror-maker.sh
-rwxr-xr-x 1 root root 1420 Dec 16 2020 connect-standalone.sh
-rwxr-xr-x 1 root root 861 Dec 16 2020 kafka-acls.sh
-rwxr-xr-x 1 root root 958 Dec 16 2020 kafka-verifiable-producer.sh
-rwxr-xr-x 1 root root 1714 Dec 16 2020 trogdor.sh
drwxr-xr-x 2 root root 4096 Dec 16 2020 windows
-rwxr-xr-x 1 root root 867 Dec 16 2020 zookeeper-security-migration.sh
-rwxr-xr-x 1 root root 1393 Dec 16 2020 zookeeper-server-start.sh
-rwxr-xr-x 1 root root 1366 Dec 16 2020 zookeeper-server-stop.sh
-rwxr-xr-x 1 root root 1019 Dec 16 2020 zookeeper-shell.sh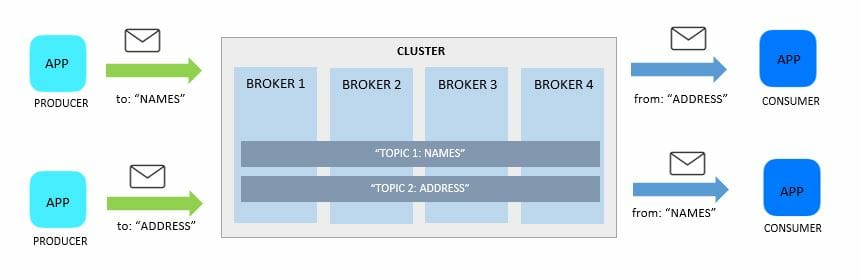
Topics are simply logical collections of messages that can virtually span across the entire clusters.
- it is a named feed - addressable and can be referenced
- Producers send messages to a topic
- Consumers retrieve messaged from a topic
- you can have as many topics as you want
- topics are split into partitions
Producers and consumers don't really care how or where the messages are kept. On the Kafka cluster's side, one or more log files are maintained for each topic.

Every Kafka message will have:
- a timestamp- set when messaged is received by the broker
- unique identifier - a way for consumers to reference the message
- binary payload - data
Recall that Kafka was conceived to resolve the issue of making consumption available to a theoretically unlimited number of independent and autonomous consumers. This means that there could be not just one consumer but hundreds or thousands of consumers that would like to receive the same messages.
Now why is this important to know? If one consumer processed a message erroneously, that fault should not cascade or impact other consumers that are processing the same message.
A single crash in one consumer shouldn't keep others from operating. Each must have its own exclusive boundary
When a producer sends a message to a topic, the messages are appended in a time-ordered sequential stream.
- Each message represents an event or Fact
- Events are intended by the producers to be consumed by the consumers
- Events are also immutable - can't be modified once receive by the topic
- If an event in the topic is no longer valid, the producer should follow-up it up with newer, correct one
- The consumer would have to reconcile messages when processed

These architectural style of maintaining an application's state through the changes captured in the immutable, time-ordered sequence is called Event Sourcing.
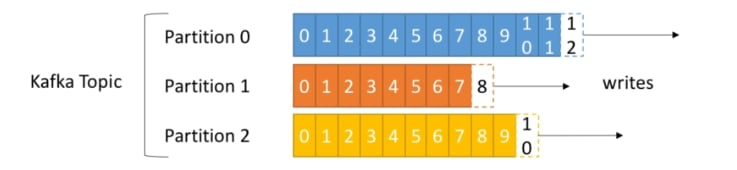
As mentioned, topics can have 1 or more partitions
- number of partitions is configurable
- each partition is ordered
- each message in a partition gets an incremental id called offset
- order of message is only guaranteed within a partition, not across partitions
- essential for scalability and fault-tolerance
Do I need to specify a partition when I create a topic?
Yes, we need to specify the partition when we create a topic but this can be changed any time.
Should I use a single partition or multiple partitions?
A single-partition topic can be used even for production, but this limits scalability and throughput. This is because you cannot simply split a single partition across multiple machines. A single partition may not be able to sustain a growing topic.
For multiple partitions, can I select the partition where the message will go to?
Data is randomly assigned to a partition unless a key is specified. This will be discussed in the succeeding chapters.

The message offset enables consumers to read their messages at their own pace, and process them independently. Similar to a bookmark,
- serves as a message identifier
- maintains last read message position
- tracked and maintained by Consumer
At the beginning, a consumer will establish a connection to a broker. The consumer will then decide what messages it want to consume. There could be two instances here:
- the consumer has not read any message from the topic yet
- the consumer has read from topic but wants to re-read a message
In both cases, the consumer will read from the beginning. It will then set its message offset to zero, indicating it's at the start. As it reads through the sequence of message, it will also move it's message offset.

Let's say we have another consumer that is also reading the messages and is at a different place in the topic. It can choose to stay in that place, reread the messages from the start, or proceed with the remaining messages.
When newer messages arrive at the topic, the connected consumers will receive an event indicating the published messages and both consumer can decide to retrieve and process the new messages.

The idea here is, the consumer knows where it is currently at and it can choose to start over or advance its position, without the need to inform the brokers, producers or other consumers.
Another thing to note here is offset is specific for each partition. This means that offset 3 in partition O will not have the same data as offset 5 in partition 6.

One of the challenges that most messaging system face are slow consumers. The problem with slow consumers is that the queue can get long and some messages might get lost.
Kafka's solution to this is its message retention policy. This allows Kafka to store the messages for a configurable period of time (hours).
- published messages are retained regardless if it's been consumed or not
- default retention time: 168 hours or 7 days
- after that time has passed, messages will be removed
- the cluster will start removing the oldest messages
- retention period is set per-topic
- message retention may be constrained by physical storage

Before we conclude this section about topics and partition, we'll look at Kafka's basis in building its architecture - commit logs.. A database's transaction or commit log is:
- source of truth - a primary record of changes
- appends events in the order they're received
- logs are then read from left to right - in a chronological order
- log entries are stored in physical log files and maintained by database
- higher-order derivative structures can be formed to represent the log
- tables, indexes, views (relaional databases)
- serves as point-in-time recovery during crashes
- basis for replication and distribution
In summary, Kafka can be thinked of as an external commit log for a distributed system which uses publish-subscribe semantics for brokers to read and write.
If you've enjoyed this short but concise article, I'll be glad to connect with you on Twitter!. 😃
20