
19
Octo's guide to the Git-verse

Earth to Earth-22. I hope this is a time when things have gone ahead, and we have left the umpteen crises behind. This is the bajillionth article on git floating across the multiverse, and why should we consider this to be any different.
What is git? A life form in a remote planet asks. The human tears up. The excerpts of the conversation that ensued shall be duly paraphrased and translated — because honestly, live translation is an extremely resource-intensive process and we would not want to burden you with the same. If the adjacent xkcd comic is any indication, if there are two words to describe git, one of them is definitely — confusing. The second one might lift you up a little, maybe a lot, when we say that one of git’s many superpowers is that it is absolutely amazing.
Now that brings us neatly back to one question — What is git? And that also ties in with a second question of why we need it in the first place when you also have things like Subversion (duh!) and Mercurial (who is in no way related to Mercury, the Roman brother of Hermes — the Greek God, not the brand)

Git is a version control system. The idea behind git is that you can track changes in your project folder and store snapshots of how the project had looked at certain points in time. It tries to unclutter the ubiquitous problem of creating umpteen folders to maintain snapshots of your code by creating a virtual Checkpoint mechanic you find in games. It is especially helpful when we are collaborating with others, or finding instances of when certain changes were made and reverting them (if they break your existing infrastructure), if necessary. And it is also useful as a documentation tool if used properly with the right set of comments and commit messages. The most powerful aspect of git, and where it ascertains its supremacy over virtually any other version control system is that it was built to be distributed. And because it is distributed, there are certain weird things and quirks that don’t always make perfect sense.
With other version control systems (referred henceforth as vcs) like Subversion or Mercurial, you would notice that they are sequential — your version numbers follow a neat and simple 1,2,3,4,5… In git, you have this uber long commit ID that is a 160-bit long hash string that identifies versions or commits history checkpoints.
Now, while this was done to facilitate the unique naming of commits in a decentralized system, the question naturally pops up is: How likely is it that the hash generated for a future commit will coincide with the hash of some past commit?
The question is closely related to something we normally refer to as the Birthday paradox, from where we see that if we were to randomly select n *from a set of **N* distinct elements, the probability of drawing the same element n more than once will be greater than half if — n ≥ 1.2√N.
Every time a commit is added to a git repository, a hash string that identifies this commit is generated. This hash is computed with the *SHA-1* algorithm and is 160 bits long. Expressed in hexadecimal notation, such hashes are 40 character strings.
To go a bit further into the math of the probability of a hash collision *(without using scary figures) *— *At a high rate where every human in the world (say, 7 billion) makes a commit every second, mankind would need nothing less than 6.66 million years to produce a number of commits large enough to create a hash collision with 50% probability!
Click *here to read more about the Birthday paradox.
The life cycle of a project with git version control initialized starts with the git init command, which initializes the entire set of operations that are to happen on the repository. What git init does is it initializes a directory called .git inside your project folder. Now, for other vcs, it mostly operates on a client-server model where you check-in your code synchronously by coordinating with, often manually, with other clients connected to the same centralized server.
In git, the .git directory is essentially the folder with some metadata where all operations are performed. Since it is decentralized, there is no network communication. All operations are local and file CRUD operations happening inside the .git directory.
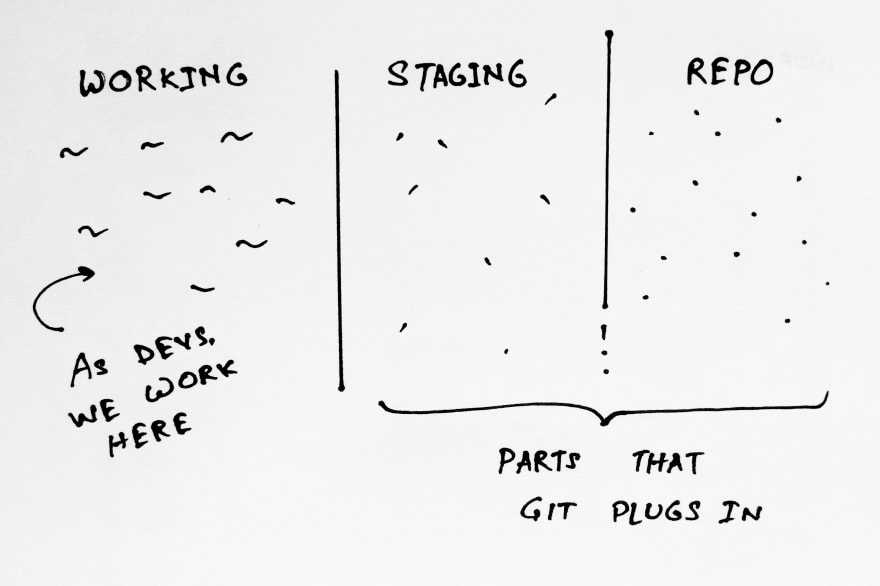
In the git-verse, as we initialize the git tracker in a folder, the underlying mechanism slaps on these two additional zones on top of your working layer.
This brings us to another command — git add that takes your files and moves them to the Staging area as a rough draft that you can later publish to your repository history. In this context, we can imagine staging being this fantastical inter-dimensional layer that holds your data.
You generally use the command as git add . or git add * that adds all the relevant unstaged files in your working area to staging. You can also do a git add to include specific files into this layer.
To undo this step, i.e. to get back data from staging into the working layer, we use the commands git reset for a generic removal of everything from staging and git reset if we just want to do that for a specific file.
We use another command called git commit to move data from the staging layer to the Repository layer. This command takes the rough snapshot of your work that you have in your staging, where you add and remove files and changes, and saves that snapshot forever in the repository later.
So, let’s say we take a file and run git add, you should be ideally able to track changes as they happen in the .git folder, as they are just file operations. There is no actual file movement involved. The system takes the file, observes it’s contents and forms a BLOB, takes some header information like how long the file is, etc. and passes it on to the *SHA-1 *algorithms that give us our 40-character hash, and stores it in the *objects *subfolder under .git .
Now when we run the git commit -m "Some commit message" in terms of the git system, it creates another structure in the *objects *subfolder called a *tree. *The purpose of a commit is to create a snapshot of your project at that point in time, with the message mentioned in quotes — The *tree *represents what your working directory looked like at that point in time.
To see the components of a *tree *snapshot at any point in time, use the command git ls-tree .
The tree essentially contains a reference of UNIX or OS (depends on your Operating System) permission code (say 644 or 755), a numeric reference to your type of file, a reference to your BLOB, the commit ID and the actual file that was added/changed.
Now the interesting bit is, what happens when you rename a file?
On the terminal, you see an old file is deleted and a new file is created. But under the hood, you essentially create a new tree that has a pointer referencing the same old BLOB because the contents remain the exact same. This is the mechanism employed as a redundancy handler and takes up lesser memory.
Read more on *trees *in git here.
Another cool command/tool that we would explore before moving on to the repository layer is a command called gitk.
This is a free GUI tool that gets installed when you install git itself, and helps you visualize the commit, the commit message and commit ID, etc.
The last thing that we would touch base on in this post, is the idea behind branches. The basic idea that pops into our head when we talk about branches is that there is a divergence — that the trackers go sideways, and a whole new route emerges and something of that sort and that idea is probably reinforced when we mention that git uses trees — but that’s the wrong mental model to have.
A branch is essentially a pointer to the elements that the tracker is looking into. For instance, the default branch tracker when you initialize a git repository points to your first commit. Once you do a second commit, the branch pointer points to your second commit, which in turn points to your first commit and so forth.
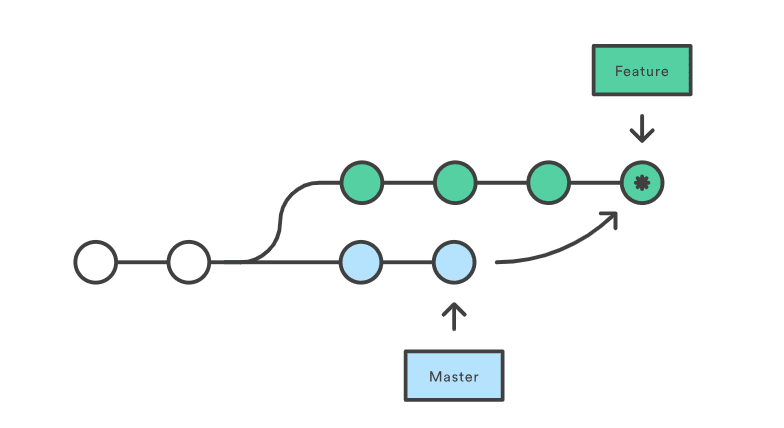
Therefore, in a broad sense of abstraction, branches are essentially pointers to a specific snapshot/commit in your git repository. They are not divergent literally like branches, and these branches are in no way related to the *tree *objects that we mentioned earlier.
This is the inner functioning of git in an extremely abstracted manner — an insight as to how git works under the hood. Obviously, this does not cover all aspects, there are far finer nuances to this amazing version tracking system, for instance, the intelligence layer that groups similar BLOBs to optimize memory usage, or the redundancy checks that take place to ensure that the .git folder does not exceed the repository source code itself in size (That would be hilarious though).
There are some pretty nifty sources to learn more about git around the Web. Use this cheat sheet by Atlassian to learn more about git commands.
Some more commands to enhance your git experience can be found here.
Until next time, keep making Peatigraffes 🤘🏼

If you want to talk about Communities, Tech, Design, Web & Star Wars, get in touch with @shuvam360 on Twitter.
Originally Published on Medium in 2020
19