
45
Kafka Sink
No último artigo foi mostrado como é possível a partir de uma fonte de dados externa, alimentar um tópico do Kafka através do Kafka Source. Agora será visto como podemos fazer a operação inversa onde as informações de um tópico alimentarão uma fonte de dados externa através do Kafka Sink, nesse exemplo será usado o banco de dados não relacional MongoDB.
Como foi visto no artigo passado o Kafka Source é uma ferramenta open source criado pela Apache, essa ferramenta facilita a comunicação em sistemas externos ao Kafka, com isso conseguimos trazer dados de fontes externas e o oposto também pode ocorrer graças ao Kafka Sink, que realiza essa operação de sink (escoar) para sistemas externos.
O Data Mountaineer é uma empresa com foco em BigData e streaming de dados que se juntou com a Landoop e fornece o connector que se liga ao Kafka Connect e realiza a operação de Sink que nesse caso será com o MongoDB.
O projeto consistirá na configuração de um connector que irá receber mensagens de um tópico do Kafka e irá salvar essas informações no MongoDB, também será criado um projeto Java que estará conectado ao banco de dados e irá expor via API REST os dados para consulta.
Focando na parte que será apresentada temos um desenho do fluxo:

Onde podemos ver de forma resumida o fluxo de dados que começa com o banco de dados MySQL, onde as alterações são capturadas pelo Debezium e através do Kafka Connect são enviadas ao broker do Kafka e também via Kafka Connect os dados são consumidos de um tópico e enviados ao Data Mountaineer e serão inseridos no MongoDB.
É necessário adicionar o MongoDB ao docker-compose como abaixo:
mongo:
image: mongo
container_name: mongo
depends_on:
- kafka-cluster
ports:
- 27017:27017
networks:
- kafka-networkVamos acessar o MongoDB via terminal:
docker exec -it mongo mongoE vamos acessar a collection taxpayer:
use taxpayerPara configurar o Kafka Sink basta acessar novamente o dashboard, através da imagem landoop/kafka-lenses-dev e clicar em Connectors no lado esquerdo e depois no botão New Connector.

Será exibida a tela com os conectores disponíveis e entre eles o conector do MongoDB basta clicar nele que será aberta a tela para inserir as configurações.
Nessa tela iremos inserir as seguintes configurações:
connector.class=com.datamountaineer.streamreactor.connect.mongodb.sink.MongoSinkConnector
connect.mongo.kcql=UPSERT INTO taxpayer SELECT after FROM irs-conn.decider.complaint_taxpayer PK after.document;UPSERT INTO taxpayer SELECT after FROM irs-conn.decider.defaulted_taxpayer PK after.document
connect.mongo.connection=mongodb://mongo:27017
tasks.max=2
topics=irs-conn.decider.complaint_taxpayer,irs-conn.decider.defaulted_taxpayer
name=mongo
connect.mongo.db=taxpayerVamos bater ponto a ponto essa configuração:
Após clicar em Create Connector a nova conexão deve ser listada como mostrado abaixo:
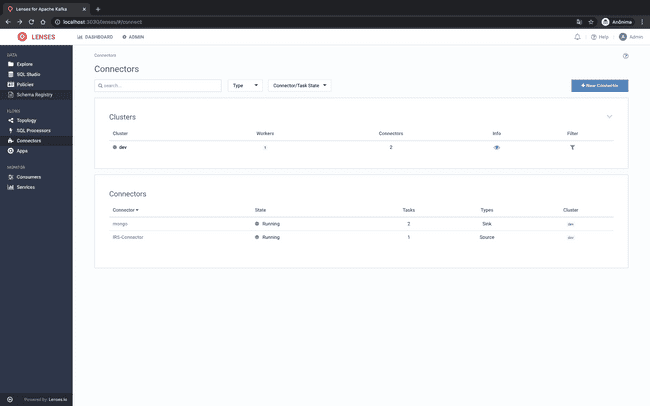
Agora podemos realizar alterações no MySQL e elas serão enviadas para os tópicos correspondentes e serão capturadas pelo Kafka Sink e enviadas ao MongoDB:
> db.taxpayer.find().pretty()
{
"_id" : "890.955.180-19",
"after" : {
"document" : "890.955.180-19",
"email" : "teste@teste.com",
"name" : "Sandra Nair Sueli Ribeiro",
"status" : "DEFAULTED"
}
}
{
"_id" : "869.097.474-10",
"after" : {
"document" : "869.097.474-10",
"email" : "fake@fake.com.br",
"name" : "Joao Alface",
"status" : "COMPLAINT"
}
}Para iniciar o projeto foi utilizado o Spring Initializr onde foi adicionado as dependências de Web, Lombok e Spring Data Mongo.
Iniciando pelo domínio dessa aplicação temos a Taxpayer:
@Data
@Builder
public class Taxpayer {
private String document;
private String email;
private String name;
private String status;
}E nos casos de uso dessa aplicação queremos que seja possível buscar os Taxpayers pelo número de documento, email e listar todos. Para isso foi criado a classe SearchTaxpayer:
@Component
public class SearchTaxpayer {
private final TaxpayerRepository taxpayerRepository;
@Autowired
public SearchTaxpayer(TaxpayerRepository taxpayerRepository){
this.taxpayerRepository = taxpayerRepository;
}
public Taxpayer searchByEmail(String email){
final Optional<Taxpayer> optionalTaxpayer = taxpayerRepository.findByEmail(email);
if(!optionalTaxpayer.isPresent()){
throw new TaxpayerNotFoundException("Taxpayer not found");
}
return optionalTaxpayer.get();
}
public Taxpayer searchByDocument(String document){
final Optional<Taxpayer> optionalTaxpayer = taxpayerRepository.findByDocument(document);
if(!optionalTaxpayer.isPresent()){
throw new TaxpayerNotFoundException("Taxpayer not found");
}
return optionalTaxpayer.get();
}
public List<Taxpayer> findAll(){
return taxpayerRepository.findAll().get();
}
}Para ela funcionar é necessário criar a classe TaxpayerRepository que nada mais é que a interface que servirá como port no conceito de ports and adapters:
public interface TaxpayerRepository {
Optional<Taxpayer> findByEmail(String email);
Optional<Taxpayer> findByDocument(String document);
Optional<List<Taxpayer>> findAll();
}E agora criamos o nosso Adapter para ele, mas primeiro faremos as configurações que o MongoDB necessita, primeiro criando a nossa entidade de banco de dados:
@Data
@Document(collection = "taxpayer")
public class TaxpayerEntity {
@Id
private String id;
private After after;
}@Data
public class After {
private String document;
private String email;
private String name;
private String status;
}Como estamos usando Spring Data o trabalho é muito simplificado bastando criar uma interface que estenda de MongoRepository:
public interface MongoTaxpayerRepository extends MongoRepository<TaxpayerEntity, String> {
Optional<TaxpayerEntity> findByAfter_Email(String email);
Optional<TaxpayerEntity> findByAfter_Document(String document);
}Agora criamos o Adapter implementando a TaxpayerRepository:
@Component
public class MongoTaxpayer implements TaxpayerRepository {
private final MongoTaxpayerRepository mongoTaxpayerRepository;
@Autowired
public MongoTaxpayer(MongoTaxpayerRepository mongoTaxpayerRepository){
this.mongoTaxpayerRepository = mongoTaxpayerRepository;
}
@Override
public Optional<Taxpayer> findByEmail(String email) {
final Optional<TaxpayerEntity> optionalTaxpayerEntity = mongoTaxpayerRepository.findByAfter_Email(email);
if(!optionalTaxpayerEntity.isPresent()){
return Optional.empty();
}
final After after = optionalTaxpayerEntity.get().getAfter();
return Optional.of(Taxpayer.builder().name(after.getName()).document(after.getDocument()).email(after.getEmail()).status(after.getStatus()).build());
}
@Override
public Optional<Taxpayer> findByDocument(String document) {
final Optional<TaxpayerEntity> optionalTaxpayerEntity = mongoTaxpayerRepository.findByAfter_Document(document);
if(!optionalTaxpayerEntity.isPresent()){
return Optional.empty();
}
final After after = optionalTaxpayerEntity.get().getAfter();
return Optional.of(Taxpayer.builder().name(after.getName()).document(after.getDocument()).email(after.getEmail()).status(after.getStatus()).build());
}
@Override
public Optional<List<Taxpayer>> findAll() {
final List<TaxpayerEntity> taxpayerEntityList = mongoTaxpayerRepository.findAll();
if(null == taxpayerEntityList || taxpayerEntityList.isEmpty()){
return Optional.empty();
}
final List<Taxpayer> taxpayerList = taxpayerEntityList.stream().map(taxpayerEntity -> {
final After after = taxpayerEntity.getAfter();
return Taxpayer.builder().name(after.getName()).document(after.getDocument()).email(after.getEmail()).status(after.getStatus()).build();
}).collect(Collectors.toList());
return Optional.of(taxpayerList);
}
}Com o adaptador criado vamos criar o controller que irá receber as requisições REST e delegar para a classe SearchTaxpayer:
@RestController
@RequestMapping("/taxpayer")
public class TaxpayerController {
@Autowired
private SearchTaxpayer searchTaxpayer;
@GetMapping
public ResponseEntity<List<Taxpayer>> getAllTaxpayers(){
return ResponseEntity.ok(searchTaxpayer.findAll());
}
@GetMapping("document")
public ResponseEntity<Taxpayer> getTaxpayerByDocument(@RequestParam("document") String document){
return ResponseEntity.ok(searchTaxpayer.searchByDocument(document));
}
@GetMapping("email")
public ResponseEntity<Taxpayer> getTaxpayerByEmail(@RequestParam("email") String email){
return ResponseEntity.ok(searchTaxpayer.searchByEmail(email));
}
}Após subir a aplicação e fazendo uma requisição para url
teremos como resultado:
```json
[
{
"document": "890.955.180-19",
"email": "teste@teste.com",
"name": "Sandra Nair Sueli Ribeiro",
"status": "DEFAULTED"
},
{
"document": "1234567890",
"email": "fake@fake.com.br",
"name": "Joao Alface",
"status": "COMPLAINT"
}
]Aqui vimos a outra ponta do Kafka Connect, o Kafka Sink e foi apresentado um exemplo prático de como podemos ter bases ou até mesmo aplicações que podem receber dados através de streams com as ferramentas que o Kafka disponibiliza.
O código do projeto está no GitHub
45