
22
Helpful Tools for Apache Kafka Developers
This blog post was originally published on the Confluent blog.
Apache Kafka® is at the core of a large ecosystem that includes powerful components, such as Kafka Connect and Kafka Streams. This ecosystem also includes many tools and utilities that make us, as Kafka developers, more productive while making our jobs easier and more enjoyable. Below, we'll take a look at a few of these tools and how they can help us get work done.
kafkacat
We like to save the best for last, but this tool is too good to wait. So, we'll start off by covering kafkacat.
$ ~ echo "Hello World" | kafkacat -b localhost:29092 -t hello-topic % Auto-selecting Producer mode (use -P or -C to override)
We’ve sent data to stdout with echo and piped it to kafkacat. We only needed two simple flags: -b for the broker and -t for the topic. kafkacat realizes that we are sending it data and switches into producer mode. Now, we can read that data with the exact same kafkacat command:
$ ~ kafkacat -b localhost:29092 -t hello-topic % Auto-selecting Consumer mode (use -P or -C to override) Hello World % Reached end of topic hello-topic [0] at offset 1
If we want to send a record with a key, we just need to use a delimiter and tell kafkacat what it is with the -K flag. In this case, we'll use a colon:
$ ~ echo "123:Jane Smith" | kafkacat -b localhost:29092 -t customers -K: % Auto-selecting Producer mode (use -P or -C to override)
Again, the same kafkacat command will read the record from the topic:
$ ~ kafkacat -b localhost:29092 -t customers -K: % Auto-selecting Consumer mode (use -P or -C to override) 123:Jane Smith % Reached end of topic customers [0] at offset 1
Alternatively, we can leave the -K flag off when reading, if we only want the value:
$ ~ kafkacat -b localhost:29092 -t customers % Auto-selecting Consumer mode (use -P or -C to override) Jane Smith % Reached end of topic customers [0] at offset 1
Note that piping data from stdout to kafkacat, as we did above, will spin up a producer, send the data, and then shut the producer down. To start a producer and leave it running to continue sending data, use the -P flag, as suggested by the auto-selecting message above.
The consumer will stay running just as the kafka-console-consumer would. In order to consume from a topic and immediately exit, we can use the -e flag.
To consume data that is in Avro format, we can use the -s flag. This flag can be used for the whole record -s avro, for just the key -s key=avro, or just the value -s value=avro. Here's an example using the movies topic from the popular movie rating tutorial:
$ ~ kafkacat -C -b localhost:29092 -t movies -s value=avro -r http://localhost:8081
------------------------------------------------------
{"id": 294, "title": "Die Hard", "release_year": 1988}
{"id": 354, "title": "Tree of Life", "release_year": 2011}
{"id": 782, "title": "A Walk in the Clouds", "release_year": 1995}
{"id": 128, "title": "The Big Lebowski", "release_year": 1998}
{"id": 780, "title": "Super Mario Bros.", "release_year": 1993}There is a lot of power packed into this little tool, and there are many other flags that can be used with it. Running kafkacat -h will provide the complete list. For more great examples of kafkacat in action, check out related posts on Robin Moffatt’s blog. One piece missing from kafkacat is the ability to produce data in Avro format. As we saw, we can consume Avro with kafkacat using the Confluent Schema Registry, but we can't produce it. This leads us to our next tool.
Confluent REST Proxy
$ ~ curl -X POST \
-H "Content-Type: application/vnd.kafka.avro.v2+json" \
-H "Accept: application/vnd.kafka.v2+json" \
--data @newMovieData.json "http://localhost:8082/topics/movies"
------------------------------------------------------------------------------
{"offsets":[{"partition":0,"offset":5,"error_code":null,"error":null}],"key_schema_id":null,"value_schema_id":3}REST Proxy is part of the Confluent Platform under the Confluent Community License, but it can be used on its own with any Kafka cluster. It can do a lot more than what we’ll cover here, as you can see from the docs. As shown above, REST Proxy can be used from the command line with curl or something similar. It can also be used with tools such as Postman to build a user-friendly Kafka UI. Here's an example of producing to a topic with Postman (the Content-Type and Accept headers were set under the “Headers” tab):  As we can see from both the
As we can see from both the curl and Postman versions, REST Proxy does require that the schema for Avro messages be passed in with each produce request. A tool like Postman, which allows you to build up a library of saved queries, can make this easier to manage. To consume from topics with REST Proxy, we first create a consumer in a consumer group, then subscribe to a topic or topics, and finally fetch records to our heart’s content. We'll switch back to curl so that we can see all the necessary bits at once. First, we POST to the consumer’s endpoint with our consumer group name. In this POST request, we will pass a name for our new consumer instance, the internal data format (in this case, Avro), and the auto.offset.reset value.
$ ~ curl -X POST -H "Content-Type: application/vnd.kafka.v2+json" \
--data '{"name": "movie_consumer_instance", "format": "avro", "auto.offset.reset": "earliest"}' \
http://localhost:8082/consumers/movie_consumers
-----------------------------------------------------------------------------------
{"instance_id":"movie_consumer_instance","base_uri":"http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance"}This will return the instance id and base URI of the newly created consumer instance. Next, we'll use that URI to subscribe to a topic with a POST to the subscription endpoint.
$ ~ curl -X POST -H "Content-Type: application/vnd.kafka.v2+json" --data '{"topics":["movies"]}' \ http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/subscriptionThis doesn't return anything, but should get a 204 response. Now we can use a GET request to the records endpoint of that same URI to fetch records.
$ ~ curl -X GET -H "Accept: application/vnd.kafka.avro.v2+json" \ http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/records
---------------------------------------------------------------------------
[{"topic":"movies","key":null,"value":{"id": 294, "title": "Die Hard", "release_year": 1988},"partition":0,"offset":0},
{"topic":"movies","key":null,"value":{"id": 354, "title": "Tree of Life", "release_year": 2011},"partition":0,"offset":1},{"topic":"movies","key":null,"value":{"id": 782, "title": "A Walk in the Clouds", "release_year": 1995},"partition":0,"offset":2},{"topic":"movies","key":null,"value":{"id": 128, "title": "The Big Lebowski", "release_year": 1998},"partition":0,"offset":3},{"topic":"movies","key":null,"value":{"id": 780, "title": "Super Mario Bros.", "release_year": 1993},"partition":0,"offset":4},{"topic":"movies","key":null,"value":{"id":101,"title":"Chariots of Fire","release_year":1981},"partition":0,"offset":5}]The consumer that we created will remain, and we can make the same GET request anytime to check for new data. If we no longer need this consumer, we can DELETE it using the base URI.
$ ~ curl -X DELETE -H "Content-Type: application/vnd.kafka.v2+json" \ http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance
We can also get information about brokers, topics, and partitions with simple GET requests.
$ ~ curl "http://localhost:8082/brokers"
$ ~ curl "http://localhost:8082/topics"
$ ~ curl "http://localhost:8082/topics/movies"
$ ~ curl "http://localhost:8082/topics/movies/partitions"
These requests can return quite a bit of JSON data, which we'll leave off for the sake of space. However, this does lead us nicely to our next tool.
jq: A command line processor for JSON
Though not specific to Kafka, jq is an incredibly helpful tool when working with other command line utilities that return JSON data. jq is a command line utility that allows us to format, manipulate, and extract data from the JSON output of other programs. Instructions for downloading and installing jq can be found on GitHub, along with links to tutorials and other resources.
Let's go back and take a look at the REST Proxy output from the GET call to our consumer above. It's not the largest blob of JSON out there, but it’s still a bit hard to read. Let's try again, this time piping the output to jq:
$ ~ curl -X GET -H "Accept: application/vnd.kafka.avro.v2+json" \
http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/records | jq
[
{
"topic": "movies",
"key": null,
"value": {
"id": 294,
"title": "Die Hard",
"release_year": 1988
},
"partition": 0,
"offset": 0
},
{
"topic": "movies",
"key": null,
"value": {
"id": 354,
"title": "Tree of Life",
"release_year": 2011
},
"partition": 0,
"offset": 1
},
{
"topic": "movies",
"key": null,
"value": {
"id": 782,
"title": "A Walk in the Clouds",
"release_year": 1995
},
"partition": 0,
"offset": 2
},
{
"topic": "movies",
"key": null,
"value": {
"id": 128,
"title": "The Big Lebowski",
"release_year": 1998
},
"partition": 0,
"offset": 3
},
{
"topic": "movies",
"key": null,
"value": {
"id": 780,
"title": "Super Mario Bros.",
"release_year": 1993
},
"partition": 0,
"offset": 4
},
{
"topic": "movies",
"key": null,
"value": {
"id": 101,
"title": "Chariots of Fire",
"release_year": 1981
},
"partition": 0,
"offset": 5
}
]It’s much easier to read now but still a bit noisy. Let's say we only want the movie titles and their release years. We can do that easily with jq:
$ ~ curl -X GET -H "Accept: application/vnd.kafka.avro.v2+json" \
http://localhost:8082/consumers/movie_consumers/instances/movie_consumer_instance/records | jq \
| jq '.[] | {title: .value.title, year: .value.release_year}'
{
"title": "Die Hard",
"year": 1988
}
{
"title": "Tree of Life",
"year": 2011
}
{
"title": "A Walk in the Clouds",
"year": 1995
}
{
"title": "The Big Lebowski",
"year": 1998
}
{
"title": "Super Mario Bros.",
"year": 1993
}
{
"title": "Chariots of Fire",
"year": 1981
}Let's take a look at what we just did (and you can follow along with the live example at jqplay):
- We piped the output from the REST Proxy to
jq. The bit between the single quotes is ajqprogram with two steps.jquses the same pipe character to pass the output of one step to the input of another. - In our example, the first step in
jqis an iterator, which will read each movie record from the array and pass it to the next step. - The second step in
jqcreates a newJSONobject from each record. The keys are arbitrary, but the values are derived from the input usingjq'sidentityoperator,'.'.
Pretty cool, huh? There is much more that can be done with jq, and you can read all about it in the documentation. The way that jq operates on a stream of JSON data, allowing us to combine different operations in order to achieve our desired results, reminds me of Kafka Streams—bringing us to our final tool.
Kafka Streams Topology Visualizer
The Kafka Streams Topology Visualizer takes the text description of a Kafka Streams topology and produces a graphic representation showing input topics, processing nodes, interim topics, state stores, etc. It's a great way to get a big-picture view of a complex Kafka Streams topology. The topology for the movie ratings tutorial is not all that complex, but it will serve nicely to demonstrate this tool.
Here's the text of our topology, which we captured with the Topology::describe method:
Topologies:
Sub-topology: 0
Source: KSTREAM-SOURCE-0000000000 (topics: [movies])
--> KSTREAM-MAP-0000000001
Processor: KSTREAM-MAP-0000000001 (stores: [])
--> KSTREAM-SINK-0000000002
<-- KSTREAM-SOURCE-0000000000
Sink: KSTREAM-SINK-0000000002 (topic: rekeyed-movies)
<-- KSTREAM-MAP-0000000001 Sub-topology: 1 Source: KSTREAM-SOURCE-0000000010 (topics: [KSTREAM-MAP-0000000007-repartition]) --> KSTREAM-JOIN-0000000011
Processor: KSTREAM-JOIN-0000000011 (stores: [rekeyed-movies-STATE-STORE-0000000003])
--> KSTREAM-SINK-0000000012
<-- KSTREAM-SOURCE-0000000010 Source: KSTREAM-SOURCE-0000000004 (topics: [rekeyed-movies]) --> KTABLE-SOURCE-0000000005
Sink: KSTREAM-SINK-0000000012 (topic: rated-movies)
<-- KSTREAM-JOIN-0000000011 Processor: KTABLE-SOURCE-0000000005 (stores: [rekeyed-movies-STATE-STORE-0000000003]) --> none
<-- KSTREAM-SOURCE-0000000004 Sub-topology: 2 Source: KSTREAM-SOURCE-0000000006 (topics: [ratings]) --> KSTREAM-MAP-0000000007
Processor: KSTREAM-MAP-0000000007 (stores: [])
--> KSTREAM-FILTER-0000000009
<-- KSTREAM-SOURCE-0000000006 Processor: KSTREAM-FILTER-0000000009 (stores: []) --> KSTREAM-SINK-0000000008
<-- KSTREAM-MAP-0000000007
Sink: KSTREAM-SINK-0000000008 (topic: KSTREAM-MAP-0000000007-repartition)
<-- KSTREAM-FILTER-0000000009You may be adept at reading this kind of output, but most people will find a graphical representation very helpful: 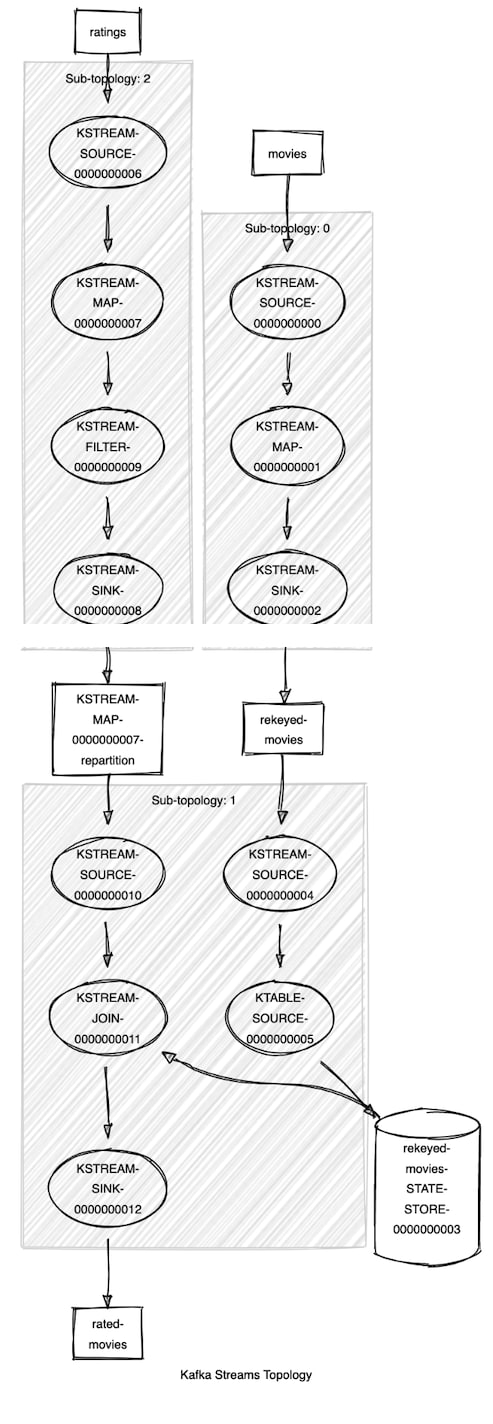 The Kafka Streams Topology Visualizer is a web app that you can host yourself (the source is available on GitHub). For occasional use, the public hosted version is probably sufficient.
The Kafka Streams Topology Visualizer is a web app that you can host yourself (the source is available on GitHub). For occasional use, the public hosted version is probably sufficient.
A complex topology might be difficult to view all at once, so you can also visualize sub-topologies and then combine the images in a way that is easier to view. This can be a huge help in bringing new developers up to speed on an existing Kafka Streams application.
ksqlDB topologies
We can get the topology description from ksqlDB with the EXPLAIN command. First, find the executing query:
ksql> SHOW QUERIES; Query ID | Query Type | Status | Sink Name | Sink Kafka Topic | Query String ------------------------------------------------------------------------------------------------------------------------------- CSAS_SHIPPED_ORDERS_0 | PERSISTENT | RUNNING:1 | SHIPPED_ORDERS | SHIPPED_ORDERS | CREATE STREAM SHIPPED_ORDERS WITH ...
Now we can use that generated query name, CSAS_SHIPPED_ORDERS_0, to get the topology:
ksql> EXPLAIN CSAS_SHIPPED_ORDERS_0;
This gives us a fair amount of output, so we won't show it all here, but toward the end, we see the topology description. Copying and pasting it into the visualizer results in this diagram: 
Tip of the iceberg
We’ve looked at four helpful tools for Apache Kafka developers, but there are many others out there, which is one of the benefits of working in such a vibrant community. If there is a command line tool or a graphical application that you find helpful in getting the most out of Kafka, tell others about it. The Confluent Community Forum is a great place to share this kind of information. We look forward to continuing this discussion with you there!
22