
15
Scrape Google Top Stories using Python
Contents: intro, imports, what will be scraped, process, code, links, outro.
This blog post is a continuation of Google's web scraping series. Here you'll see how to scrape Google Top Stories from Organic Search Results using Python with beautifulsoup, requests libraries. An alternative API solution will be shown.
from bs4 import BeautifulSoup
import requests, lxml
from serpapi import GoogleSearch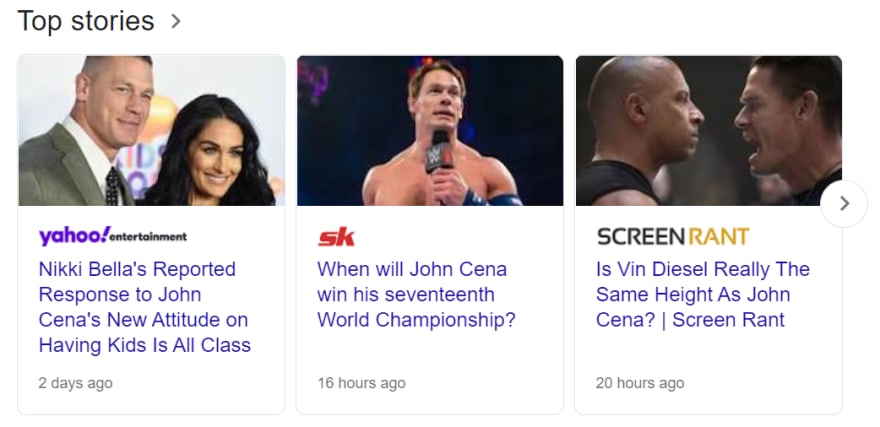
Selecting container, published date, title CSS selectors.

Selecting link CSS selector.

from bs4 import BeautifulSoup
import requests, lxml
headers = {
'User-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
'q': 'john cena',
'hl': 'en',
'gl': 'us',
}
html = requests.get('https://www.google.com/search?q=', headers=headers, params=params).text
soup = BeautifulSoup(html, 'lxml')
for result in soup.select('.yLWA8b'):
title = result.select_one('.nDgy9d').text.replace('\n', '')
link = result.select_one('.WlydOe')['href']
published_date = result.select_one('.ecEXdc span').text
print(f'{title}\n{link}\n{published_date}\n')
----------------
'''
Nikki Bella's Reported Response to John Cena's New Attitude on Having Kids Is All Class
https://www.yahoo.com/entertainment/nikki-bellas-reported-response-john-194941780.html
2 days ago
When will John Cena win his seventeenth World Championship?
https://www.sportskeeda.com/wwe/when-will-john-cena-win-seventeenth-world-championship
16 hours ago
Is Vin Diesel Really The Same Height As John Cena? | Screen Rant
https://screenrant.com/f9-john-cena-vin-diesel-height-comparison-same-different/
20 hours ago
'''Using Google Top Stories API
SerpApi is a paid API with a free trial of 5,000 searches.
In this example, Google Top Stories API provides quite a few more results in relation to the code above. Also, if you do not interested in maintaining the parse, figuring out why things don't behave as they should, or bypassing blocks from Google, an API solution is a way to go.
from serpapi import GoogleSearch
import os, json
params = {
"api_key": os.environ["API_KEY"], # pycharm environment
"engine": "google",
"q": "john cena",
"gl": "us",
"hl": "en"
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['top_stories']:
print(json.dumps(result, indent=2, ensure_ascii=False))
-------------
'''
{
"title": "Nikki Bella's Reported Response to John Cena's New Attitude on Having Kids Is All Class",
"link": "https://www.yahoo.com/entertainment/nikki-bellas-reported-response-john-194941780.html",
"source": "Yahoo",
"date": "2 days ago",
"thumbnail": "https://serpapi.com/searches/60e30aaf1071f423feda11f5/images/b544986d11640bd39c43fea8c2bbc111dec815b3d8089f08.jpeg"
}
{
"title": "When will John Cena win his seventeenth World Championship?",
"link": "https://www.sportskeeda.com/wwe/when-will-john-cena-win-seventeenth-world-championship",
"source": "Sportskeeda",
"date": "17 hours ago",
"thumbnail": "https://serpapi.com/searches/60e30aaf1071f423feda11f5/images/b544986d11640bd38557cb4783461be1ca3dfe7ff6bcb2a0.jpeg"
}
...
'''If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.

15