
40
Deploy Kafka + Filebeat + ELK - Docker Edition - Part 1
This article is the first part of a two part series where we will deploy ELK stack using docker/docker-compose.
In this article, we will be configuring Filebeat and Kafka.
- You need to have docker/docker-compose installed. Click Here for the bash file that will help you install it on Ubuntu 18.04 LTS.
- An Idea about ELK.
So lets say, you have several servers in place for which you need to aggregate application logs. Some servers might be in the same VPC
and some might even belong to a different cloud provider.
For this particular example, lets say we have three servers and Kafka server (to be installed) in the same VPC and the fourth application server outside it.
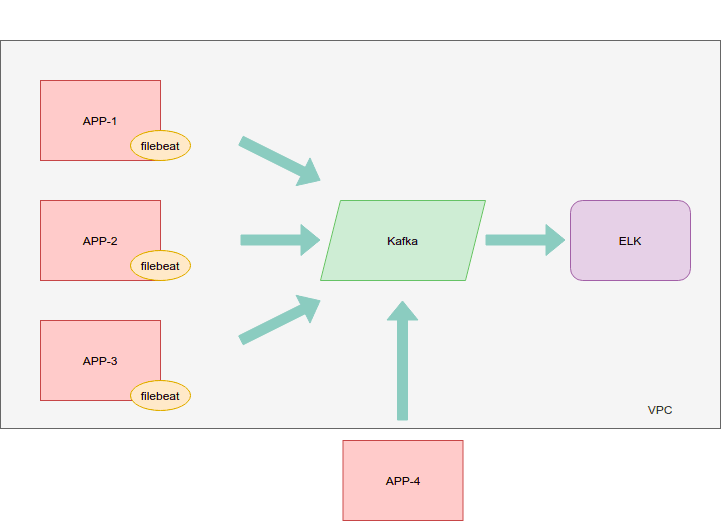
Filebeat is used for forwarding the log data from your application server. The same can be done by logstash.
Filebeat is pretty lightweight. It would need lesser resources than a logstash instance. But that raises another question.
Logstash would still be required as logstash aggregates logging data from different sources and pass it over to elasticsearch for indexing.
So there are two components present for the installation of filebeat.
- filebeat.yml
- docker-compose.yml
This is what the docker-compose file looks like:
version: "3"
services:
filebeat:
image: docker.elastic.co/beats/filebeat:6.6.0
container_name: filebeat
user: root
environment:
- strict.perms=false
volumes:
- './filebeat.yml:/usr/share/filebeat/filebeat.yml:ro'
- './data:/usr/share/filebeat/data:rw'
- '/var/log/nginx:/usr/share/services/nginx'
- '/home/ubuntu/.pm2/logs:/usr/share/services/node'
command: filebeat -e
logging:
driver: "json-file"
options:
max-file: "5"
max-size: "10m"I have added a log-rotator as filebeat itself generates several logs.
Here we have mounted 4 directories:
- filebeat.yml which holds the configuration
- data folder to persist the information filebeat saves.
- 2 directories where logs are being generated by the applications.You can change it according to your own application.
filebeat.prospectors:
- type: log
enabled: true
tags:
- app_1_nginx
paths:
- /usr/share/services/nginx/*.log
- type: log
enabled: true
tags:
- app_1_pm2
paths:
- /usr/share/services/node/*.log
output.kafka:
version: 0.10.2.1
hosts: ["KAFKA_IP:KAFKA_PORT"]
topic: 'applogs'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000Here we have mentioned a list of inputs, where each input begins with -.
Tags are added so that we are able to identify the source of the log.
The paths shared in the filebeat.yml are the paths where our actual logs are mounted in the docker-compose.yml file.
We have configured the output to be forwarded to kafka. The data will be published on the topic applogs.
required_acks here is set to 1. It is recommended not to set it to 0
Depending on whether the server is in the same VPC or not,We will put the ip and port information.
When in the same VPC as the kafka server, this is how the output block will look like:
output.kafka:
version: 0.10.2.1
hosts: ["KAFKA_PRIVATE_IP:9092"]
topic: 'applogs'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000Replace KAFKA_PRIVATE_IP by the actual private ip of your kafka server.
For the public connectivity, this is how the output block will look like:
output.kafka:
version: 0.10.2.1
hosts: ["KAFKA_PUBLIC_IP:19092"]
topic: 'applogs'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000Replace KAFKA_PUBLIC_IP by the actual public ip of your kafka server.
Make sure the owner of the file (aka filebeat.yml) must be either root or the user who is executing the Beat process.
Note: prospectors has now been replaced by inputs in recent versions.
Now lets run the application
docker-compose up -dAnd Voila! filebeat has been setup.
If you check filebeat logs, You will see that it is filled with connection-error messages as Kafka has not been setup yet.
Now lets setup Kafka.
Kafka is an open source software for storing,reading and analysing stream of data.
ELK would be sufficient if there aren't enough logs to process.
You can direct your filebeat logs towards logstash. Kafka comes in to play when we are logging at scale. It acts as a buffer. Kafka will receive the logs from filebeat and queue it up in case ELK is under heavy load.
I am using Bitnami's Docker Image for Kafka.
It is well documented and frequently updated. We will be doing a straight forward setup and add a firewall allowing only the private/public ips that belongs to our application servers.
If you are using ubuntu,This is how you add firewall rules for our particular case.
If your firewall is disabled:
sudo ufw allow ssh
sudo ufw enablesudo ufw allow from PRIVATE_IP1 to any port 9092
sudo ufw allow from PRIVATE_IP2 to any port 9092
sudo ufw allow from PRIVATE_IP3 to any port 9092
sudo ufw allow from PUBLIC_IP1 to any port 19092PRIVATE_IP1 through 3 are the private ips of the servers that are present in the same vpc as our kafka server.
version: "2"
services:
zookeeper:
image: docker.io/bitnami/zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
network_mode: host
kafka:
image: docker.io/bitnami/kafka:latest
container_name: kafka
ports:
- "19093:19093"
- "9092:9092"
environment:
- KAFKA_BROKER_ID=1
- KAFKA_CFG_ZOOKEEPER_CONNECT=PRIVATE_IP_OF_KAFKA_SERVER:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:19093
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://PRIVATE_IP_OF_KAFKA_SERVER:9092,EXTERNAL://PUBLIC_IP_OF_KAFKA_SERVER:19093
- KAFKA_INTER_BROKER_LISTENER_NAME=CLIENT
network_mode: host
depends_on:
- zookeeper
networks:
app-tier:
driver: bridgeKafka uses zookeeper to store its metadata(topics, location of partitions, etc) and hence it is needed to be present alongside kafka.
We have aligned two listners, INTERNAL and EXTERNAL.
INTERNAL Listner is for communication within the VPC. EXTERNAL Listner is for the application that is to be connected via the public ip of the kafka server.
I am using host network in this case.
To run the docker-compose file:
docker-compose up -dNext step will be to create the topic applogs
docker exec -it kafka /opt/bitnami/kafka/bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --partitions 1 --replication-factor 1 --topic applogsTo confirm if the topic has been created:
docker exec -it kafka /opt/bitnami/kafka/bin/kafka-topics.sh --list --zookeeper zookeeper:2181Now that the topic has been created, We need to verify the communication by pushing data on one topic and receiving it on the other end.
To subscribe a topic and listen for messages:
docker exec -it kafka /opt/bitnami/kafka/bin/kafka-console-consumer.sh --bootstrap-server PRIVATE_KAFKA_IP:9092 --topic applogs --from-beginningIf you have configured your filebeat.yml file correctly, You will start getting logs from your application server.
To push data to a topic:
docker exec -it kafka /opt/bitnami/kafka/bin/kafka-console-producer.sh --broker-list PRIVATE_KAFKA_IP:9092 --topic applogsYou can install kafkacat on your application server to verify the connections.
In the next article, we will connect ELK with Kafka.
40