
26
What is the sorting algorithm behind ORDER BY query in MySQL?
Since the last couple of weeks, I have been working on MySQL more closely. MySQL is a brilliant piece of software. I remember reading about all the sorting algorithms in college so I was curious to know which algorithm MySQL uses and how ORDER BY query works internally in such an efficient manner.
I started exploring & digging deeper into its open source code and I was amazed with its implementation.
MySQL is canny. It’s sorting algorithm depends on a couple of factors -
- Available Indexes
- Expected size of result
- MySQL version
MySQL has two methods to produce sorted/ordered streams of data.
Firstly MySQL optimiser analyses the query and figures out if it can just take advantage of sorted indexes available. If yes, it naturally returns records in index order. (The exception is NDB engine, which needs to perform a merge sort once it gets data from all storage nodes)
Hands down to the MySQL optimiser, who smartly figures out if the index access method is cheaper than other access methods.
Really interesting thing to see here is-
The index may also be used even if ORDER BY doesn’t match the index exactly, as long as other columns in ORDER BY are constant.
Sometimes, the optimizer probably may not use Index if it finds indexes expensive as compared to scanning through the table.
For example -
Assume, we have an index on userId and mobileNumber in the user table and we run below query -
SELECT * FROM USER
ORDER BY userId , mobileNumber;Here, you might feel Indexes on userId and mobileNumber enables optimizer to use index BUT this query has “ *SELECT ** ”, which is selecting more columns than just userId and mobileNumber.
In this case, scanning through an entire index, to find columns which are not in the index, is more expensive than scanning the table and sorting the results. Here, the optimizer probably does not use the index.
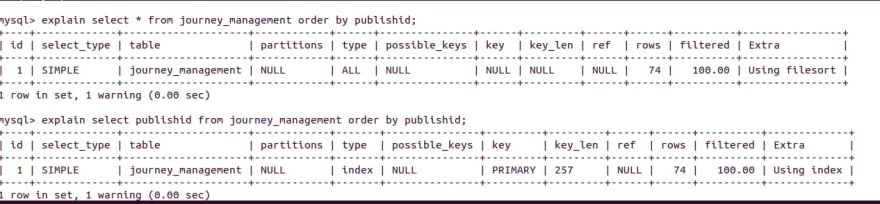
If Indexes can not be used to satisfy an ORDER BY clause, MySQL utilises filesort algorithm. This is a really interesting algorithm. In a nutshell, It works like this -
- It scans through the table and finds the rows which matches the WHERE condition
- It maintains a buffer and stores a couple of values (sort key value, row pointer and columns required in the query) from each row in it. The size of this chunk is system variable sort_buffer_size.
- When, buffer is full, it runs a quick sort on it based on the sort key and stores it safely to the temp file on disk and remembers a pointer to it.
- It will repeat the same step on chunks of data until there are no more rows left.
- Now, it has a couple of chunks which are sorted.
- Finally, it applies merge sort on all sorted chunks and puts it in one result file.
- In the end, it will fetch the rows from the sorted result
If the expected result fits in one chunk, the data never hits disk, but remains in RAM.
To your surprise, suppose, if we have 1 Billion rows in our user table and if we run below two queries -
SELECT * FROM users ORDER BY userId ;SELECT * FROM users ORDER BY userId LIMIT 5;MySQL optimizer is smart enough to understand, it's not worth using merge sort. So, It uses heap sort if we just want a set of results, not the entire data.
Ordering by multiple columns does not require scanning the database twice! In MySQL (<v4.1), it used to read the data twice, once to match rows in WHERE clause and one, in the end to prepare the result from row pointers.
- External merge sort (quick sort + merge sort) if data doesn’t fits into the memory
- Quick sort, if data fits into the memory and we want all of it
- Heap sort, if data fits into the memory but we are using LIMIT to fetch only some results
- Index lookup (not exactly a sorting algorithm, just a pre-calculated binary tree)
With the help of EXPLAIN statement, we can see if query is making use of filesort or indexes.
26