
47
OpenShift for Dummies - Part 1

The best way to bring value to an existing business is with the development of new applications, whether they be cloud-native applications, AI & machine learning, analytics, IoT, or any other innovative application. OpenShift, created by Red Hat, is the platform large enterprises use to deliver container-based applications. If you have read my previous posts about Docker and Kubernetes, you understand the importance of containerization in the cloud. OpenShift claims to be “the industry's most secure and comprehensive enterprise-grade container platform based on industry standards.” To put it bluntly, OpenShift is like Kubernetes on steroids.
In this post, I will cover a brief history of IT infrastructure, summarize the role of a DevOps engineer and why they use OpenShift, how OpenShift works, and in part 2 I will show how to use OpenShift. Having a good grasp of the evolution of IT infrastructure is important to fully understand why DevOps engineers use OpenShift and appreciate the impact OpenShift on the cloud computing industry.
If you have already read part 1, please stay tuned for part 2!
How IT Infrastructure Has Changed Over Time
Moore’s law is the observation that the number of transistors on a chip doubles every two years. This means that we can expect the speed and capability of computers to increase every couple of years, and that we will pay less for them. Increasingly powerful microchips have consistently brought forth sweeping changes to business and life in general ever since the advent of the internet. It is hilarious how wrong some people were about how the internet would affect our lives.
In 1995, scientist Clifford Stoll was promoting his book, “Silicon Snake Oil.” At the same time, he published an article in Newsweek titled, “The Internet? Bah!,” in which he stated that services like e-commerce would not be viable, and that “no online database will replace your daily newspaper.”

Perhaps it's just that hindsight is 20/20. After all, Clifford Stoll managed computers at Lawrence Berkeley National Laboratory in California, so it’s not like his opinion was coming from a place of ignorance. Today, most people know how ubiquitous internet technology is to some degree, but where did that process start, and where are we now? Let's begin with the development process. There are 3 pertinent development processes that you may be familiar with:
Development Processes
Waterfall: The waterfall process is named for its one-way approach. Progress is typically only made in mode direction, like a waterfall. A project is broken down into linear sequential phases and each phase depends on the deliverables of the previous phase. The main issue with this is if a client decides that their needs have changed, it is difficult to go back and make changes.
Agile: From the waterfall method, the agile method was born. Instead of delivering 100% to the client at each stage, you may deliver about 20% of a functionality. At that point, the client gives their feedback and while you continue to work on the deliverable, you begin the process of creating another functionality. After 5 iterations, developers have a product that they are satisfied with and will continue to use. But what about IT operations; those who run existing servers, websites and databases?
DevOps: Since development and operation teams can have different goals and skills, the division of these two teams often creates an environment where they do not trust each other. The DevOps approach combines these two teams so they have shared passion and common goals. I will touch more on this later.

The next aspect of IT evolution is application architecture, which refers to the software modules and components, internal and external systems, and the interactions between them.
Application Architecture
Monolithic: A monolithic architecture is the traditional unified model for the design of a software program. Monoliths had a main frame that held the entire application stack, so if the mainframe hardware crashed, the entire system was down. These were then broken down over the years into separate tiers.
3-tier: Three-tier systems break down the model of the mainframe into a web tier, an application tier, and a database tier. This is known as service-oriented architecture (SOA). The reality remains, however, if one of these tiers goes down, you have downtime. And still, all of the application logic remains in the app tier. People have moved on from this architecture to a microservice architecture.
Microservices: In this architecture, you build your services not by the tier, but rather by the business functionality. I will go into more detail about microservices later.

The next aspect is application infrastructure, which is the software platform for the delivery of business applications.
Application Infrastructure
Data Centers: These are giant rooms filled with large, powerful computers that make a lot of noise. To put it in perspective, many data centers are larger than 100,000 sq feet and require specially designed air conditioning systems to make sure they do not overheat.
Hosted: Collections of organizations all underneath one umbrella host their computing and storage power for other businesses to use. This is the precursor of cloud computing.
Cloud computing: Cloud computing uses a network of remote servers to take care of storing, managing, and processing data. There are many cloud providers out there, namely Amazon Webservices, Azure and Google Cloud Platform, which dominate the global market. With cloud computing, hosting, availability, redundancy, etc. are taken care of by a cloud provider. Many businesses are wanting to move to cloud computing, but there are logistical challenges that people have to consider and overcome to do so.
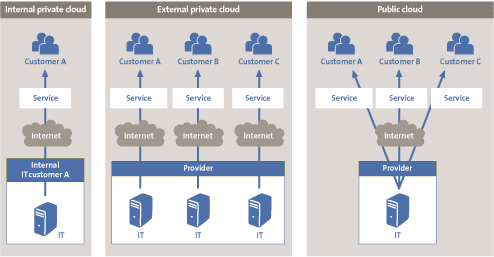
Not only is how applications are developed important, but how they are delivered is also important. The evolution of deployment and packaging is as follows:
Deployment and Packaging
Physical servers: At one point, one physical server hosted one application. By today's standards, this is very inefficient.
Virtual servers: On one physical server you can have many virtual machines, which can host an application.
Containers: Containerization is the next step that businesses are adopting for application development. With containers, multiple applications with all their dependencies can be hosted on a single server without having the OS layer in between.
You should be familiar with containers! If you are not, please read “Docker for Dummies” and "Kubernetes for Dummies". The rest of this post assumes you understand the basics behind containerization and container orchestration.
DevOps Best Practices
We have seen that new technology gives rise to new ways of creating applications. As stated before, there are often issues between development and operation teams, which is why companies are adopting DevOps practices to streamline their development. DevOps engineers use OpenShift because it makes cloud deployments easy and enables them to follow these DevOps best practices:
Everything as Code: The practice of treating all parts of a system as code.
Infrastructure as Code: Simple workflows to auto-provision infrastructure in minutes. (e.g. Terraform, AWS CloudFormation)
Environments as Code: Single workflows to build and deploy virtual machine environments in minutes. (e.g. Vagrant, Docker)
Configuration as Code: Simple, model-based workflows to scale app deployment and configuration management. (Ansible, Puppet, Chef)
Data Pipelines as Code: Programmatically author, schedule and monitor data pipeline workflows as code. (e.g. Apache Airflow, Jenkins)
Security Configuration as Code: Detect and remediate build & production security misconfigurations at scale. (e.g. Checkov)
Encryption Management as Code: Programmatically secure, store and tightly control access across cloud and data center (e.g. Vault, AWS KMS)
Application is always “releasable”: Because everything is code, it is always releasable at any point in time.
Rebuild vs. Repair: This is precisely the point between developers and operations that causes friction (AKA integration hell). For example, someone on the development team changes something in the development environment of the application. Or maybe someone in operations changes something in staging of production. Either way, you have an end product which does not reflect either side. What you should do is instead of tweaking the end product, you should have a golden image that everyone tweaks and can be released at any time.
Continuous Monitoring: You should ensure there is no malware or security vulnerabilities in your application stack, and that any sensitive information like passwords or keys are not exposed to the public.
Automate Everything: Don’t do things manually which can be done automatically like configuration management and testing.
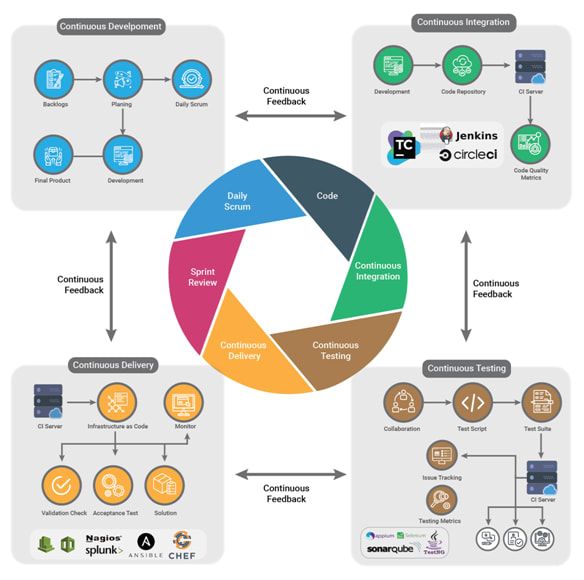
Rapid Feedback: Rapid feedback loops are what make good development teams. The goal behind having rapid feedback is to continuously remove bottlenecks. A simple example of a rapid feedback loop is a CI/CD pipeline.
Delivery pipeline: A delivery pipeline automates the continuous deployment of a project. In a project's pipeline, sequences of stages retrieve input and run jobs, such as builds, tests, and deployments.
Continuous Integration/Continuous Delivery or Deployment(CI/CD): CI/CD is a method to frequently deliver apps to customers.
Continuous Integration: New code changes to an app are regularly built, tested and merged to a shared repository. This solves the problem of having too many branches or an app in development at once that could possibly conflict with one another.
Continuous Delivery: Applications are automatically bug tested and uploaded to a repository (e.g. GitHub, DockerHub) where they can then be deployed to a live production environment.
Continuous Deployment: Automatically testing a developer’s changes from the repository to production where it is usable by customers.
Developing Applications With Monoliths vs. Microservices
Consider the following application: An airline company wants to create an application to book flights. There are three major areas of the application that should be created: Registration, Payment and Service Inquiry.
Monolithic:
With a monolithic architecture, there are some serious drawbacks. All three major areas must be tightly coupled in order to run.
With a monolithic architecture, there are some serious drawbacks. All three major areas must be tightly coupled in order to run.
In the monolithic model, all of the modules and programs only work on one type of system and are dependent on one another. This makes new changes a challenge and drives up cost to scale. There is also low resilience in this system because if anything fails, the whole system fails, which can happen for any number of reasons. Maybe there is a hardware issue, or maybe the application receives more traffic than it is designed to handle. In both cases, the application crashes and the whole system is down.
Microservices:
In a microservices architecture, you split your business function so each function has its own set of independent resources. Each function might have its own application and its own database. This means you can independently scale these services and that you are not limited to the technology that you use for your application stack. Autonomous services (microservices) make systems more resilient, flexible to changes, easy to scale and highly available. With cloud platforms like AWS, you can automate these processes.
In a microservices architecture, you split your business function so each function has its own set of independent resources. Each function might have its own application and its own database. This means you can independently scale these services and that you are not limited to the technology that you use for your application stack. Autonomous services (microservices) make systems more resilient, flexible to changes, easy to scale and highly available. With cloud platforms like AWS, you can automate these processes.

Moving to the Cloud
A notable issue with using virtual machines in infrastructure is that they are not portable across the hypervisor and thus do not provide portable packaging for applications. So in practice, there is no guarantee that applications will migrate smoothly from, say, an employee’s laptop to a virtual machine or to a public cloud. There are different OS layers, different stacks for each environment, so the portability is nonexistent. As explained before in “Docker for Dummies”, containerization software like Docker offers a solution for this. OpenShift uses Red Hat Enterprise Linux which has their own container daemon built into the kernel, eliminating the need for containerization applications like Docker.
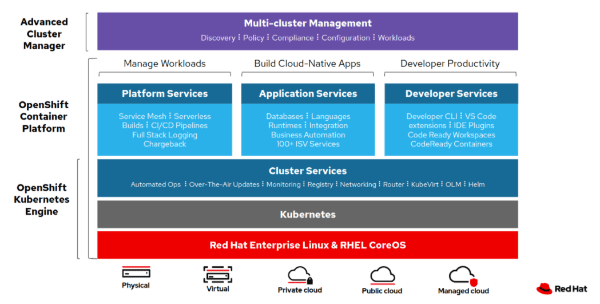
A conceptual way of thinking about it is in terms of microservices. If you have hundreds of microservices, you are not going to want to have hundreds of virtual machines for each service because there would be too much overhead. This is why containerization is necessary if businesses want to adopt a microservice architecture. Here is a simple view of the advantages of using containers vs. virtual machines:

We’ve talked about IT infrastructure, DevOps practices and how OpenShift is used to manage containers. We also discussed some advantages of using OpenShift, but how does OpenShift differ from Kubernetes, and how do you get started?
Please stay tuned for part 2 to learn more!
47