
23
How to automate financial data collection and storage in CrateDB with Python and pandas
In this step-by-step post, I introduce a method to get financial data from stock companies. Then, I show how to store this data in CrateDB and keep it up to date with companies’ data.

This tutorial will teach you how to automatically collect historical data from S&P-500 companies and store it all in CrateDB using the Python language.
tl;dr: I will go through how to
import S&P-500 companies’ data with the Yahoo! Finance API into a Jupyter Notebook
setup a connection to CrateDB with Python
create functions to create tables, insert values, and retrieve data from CrateDB
upload finance market data into CrateDB
Before anything else, I must make sure I have my setup ready.
So, let’s get started.
CrateDB is a robust distributed SQL database and makes it simple to ingest and analyze massive amounts of data in real-time, making it perfect for this project.
To connect to CrateDB for the first time, I follow this step-by-step CrateDB installation tutorial, which has this and more methods to install CrateDB.
With the Ad-Hoc method, I first download CrateDB (version 4.6.1) and unpack it.
I then navigate in my terminal to the unpacked CrateDB root folder with the command
cd /crate-4.6.1
and run a single-node instance from CrateDB with
./bin/crate.
Now I connect to the CrateDB Admin UI from my browser at http://localhost:4200
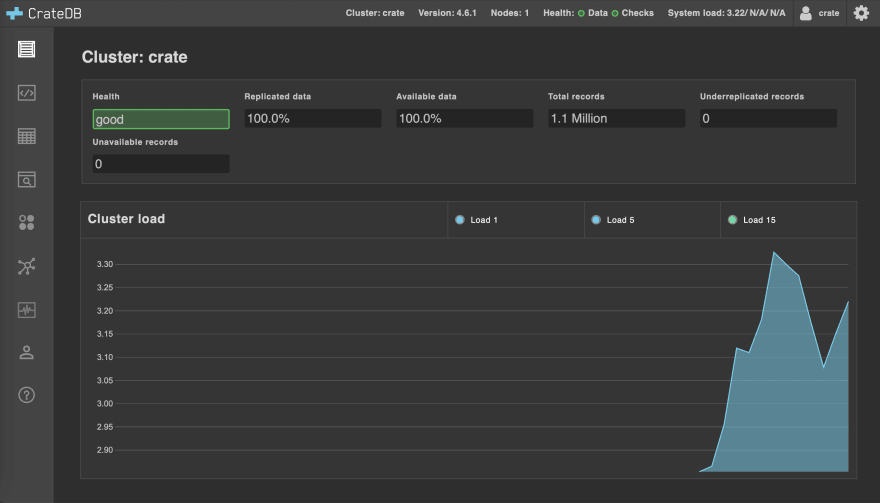
With CrateDB up and running, I can now make sure Python is set up.
The Python language is a good fit for this project: it’s simple, highly readable, and has valuable analytics libraries for free.
I download Python’s latest version, then reaccess the terminal to check if Python was installed and which version I have with the command
pip3 --version,
which tells me I have Python 3.9 installed.
All set!
The Jupyter Notebook is an open-source web application where one can create and share documents that contain live code, equations, visualizations, and narrative text.
A Jupyter Notebook is an excellent environment for this project. It contains both executable documents (the code) and human-readable documents (tables, figures, etc.) in the same place!
I follow the Jupiter Installation tutorial for the Notebook, which is quickly done with Python and the terminal command
pip3 install notebook
and now I run the Notebook with the command
jupyter notebook
Setup done!
Now I can access my Jupyter Notebook by opening the URL printed in the terminal after running this last command. In my case, it is at http://localhost:8888/
On Jupyter’s main page, I navigate to the New button on the top right and select Python 3 (ipykernel)
An empty notebook opens.
To make sure everything works before starting my project, I
- call the notebook “financial-data-with-cratedb”,
- write a ‘Hello World!’ line with
print('Hello World!')- run the code snippet by pressing
Alt+Enter(or clicking on the Run button)
Great, it works! Now I can head to the following steps to download the financial data.
When I read yfinance's documentation, I find the download function, which gets either a ticker symbol or a list of those as a parameter and downloads the data from these companies.
As I want to download data from all S&P-500 companies at once, having a list with all their symbols would be perfect.
I then found this tutorial by Edoardo Romani, which shows how to get the symbols from the List of S&P-500 companies Wikipedia page and store them in a list.
So, in my Notebook, I import BeautifulSoup and requests to pull out HTML files from Wikipedia and create the following function:
import requests
from bs4 import BeautifulSoup
def get_sp500_ticker_symbols():
# getting html from SP500 Companies List wikipedia page
url = "https://en.wikipedia.org/wiki/List_of_S%26P_500_companies"
r = requests.get(url,timeout = 2.5)
r_html = r.text
soup = BeautifulSoup(r_html, 'html.parser')
# getting rows from wikipedia's table
components_table = soup.find_all(id = "constituents")
data_rows = components_table[0].find("tbody").find_all("tr")[1:]
# extracting ticker symbols from the data rows
tickers = []
for row in range(len(data_rows)):
stock = list(filter(None, data_rows[row].text.split("\n")))
symbol = stock[0]
if (symbol.find('.') != -1):
symbol = symbol.replace('.', '-')
tickers.append(symbol)
tickers.sort()
return tickersWhat this function does is:
- it finds the S&P-500 companies table components in the Wikipedia page’s HTML code
- it extracts the table rows from the components and stores it in the
data_rowsvariable - it splits
data_rowsinto thestocklist, where each element of the list contains information about one stock (Symbol, Security, SEC filings, …) - it takes the Symbol for each
stocklist element and adds it to thetickerslist - finally, it sorts the
tickerslist in alphabetical order and returns it
To check if it works, I will call this function and print the results with
tickers = get_sp500_ticker_symbols()
print(tickers)and it looks like this:

Now that I have a list of all the stock tickers, I can move on and download their data with yfinance.
Its key data structure is called a DataFrame, which allows storage and manipulation of tabular data: in this case, the columns are going to be the financial variables (such as “date”, “ticker”, “adjusted closing price”…) and the rows are going to be filled with data about the S&P-500 companies.
So, the first thing I do is import the yfinance and pandas
import yfinance as yf
import pandas as pdAnd now, I design a function to download the data from my list of companies.
Looking again at the documentation for yfinance, I see that the download function returns a pandas.DataFrame object containing different kinds of information for a company, such as Date (which is the index for the DataFrame), Adjusted Close, High, Low, among others.
I am interested in the Date and the Adjusted Close value, so I will extract the ‘Adj Close’ column from the DataFrame, as the index already includes the Date.
Apart from that, I only want to download data from a certain date on. Then, the next time I run this script, I can make sure only new data is being downloaded!
With that in mind, I create the download_YFinance_data function:
def download_YFinance_data(last_date):
tickers = get_sp500_ticker_symbols()
# downloading data from yfinance
data = yf.download(tickers, start = last_date)['Adj Close']
data.index.names = ['closing_date']
data.reset_index(inplace = True)
return dataAt the end of this function, I rename the index (which contains the date) to ‘closing_date’, as this is the column name I prefer for CrateDB, and then I reset the index.
Now, instead of having the date as the index, I have a column called ‘closing_date’, which has the date information, and the rows are indexed trivially (like 0, 1, 2, …). This will make it easier to iterate over the DataFrame in the next steps.
To check if everything works, I execute the function and store it in the my_data variable, and print the result:
my_data = download_YFinance_data('2021-11-16')
print(my_data)and it looks like this:

Great, now that I have my data set, I move on to connecting to CrateDB and creating functions to insert this data into my database.
As CrateDB is highly compatible with PostgreSQL, I can use a PostgreSQL connector to connect to my database. The one I chose is psycopg2 , so I first install it with
import psycopg2 as ps
import mathand I also import the math package, which will be necessary for further steps.
I set the connection credentials as variables and create a function to connect to CrateDB using psycopg’s connect function:
host_name = 'localhost'
dbname = 'doc'
port = '5432'
username = 'crate'
password = ''
def connect_to_crateDB(host_name, dbname, port, username, password):
try:
conn = ps.connect(host = host_name, database = dbname, user = username,
password = password, port = port)
except ps.Error as e:
raise e
else:
print("Connected!")
return conn5432 is the standard port when connecting to CrateDB using PostgreSQL, and I can log in with the standard crate user, which has no password.
I create a conn variable, which stores the connection, and a curr cursor variable, which allows Python code to execute PostgreSQL commands.
conn = connect_to_crateDB(host_name, dbname, port, username, password)
curr = conn.cursor()When I run this code, ‘Connected!’ is printed, which means I have successfully connected to CrateDB.
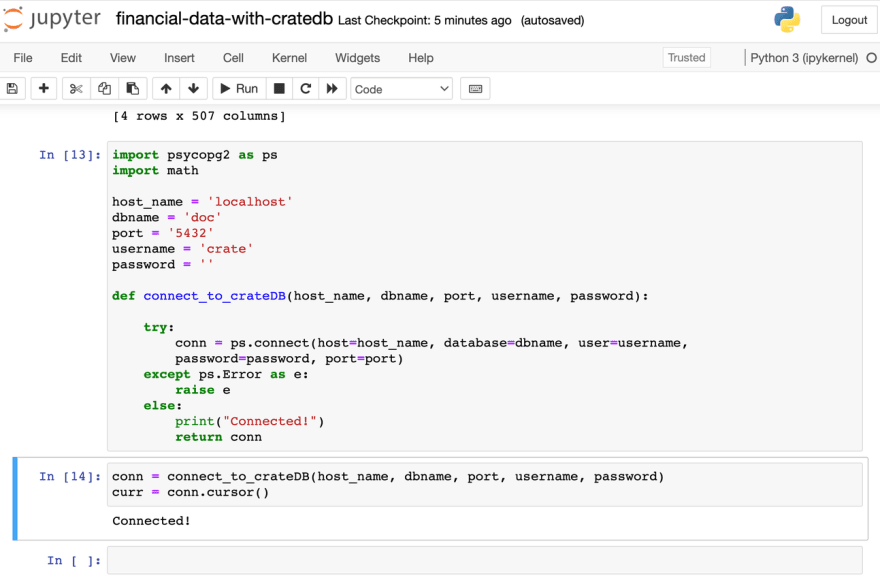
Now I can create more functions to create tables in CrateDB, insert my data values into a table, and retrieve data!
In my table, I will have the closing_date, ticker and adjusted_close columns. Also, I want to give the table name as a parameter, and only create a new table in case the table does not exist yet. That’s why I use the SQL keywords CREATE TABLE IF NOT EXISTS in my function.
Now I need to create the complete statement as a string and execute it with the curr.execute command:
def create_table(table_name):
columns = "(closing_date TIMESTAMP, ticker TEXT, adjusted_close FLOAT)"
statement = "CREATE TABLE IF NOT EXISTS \"" + table_name + "\"" + columns + ";"
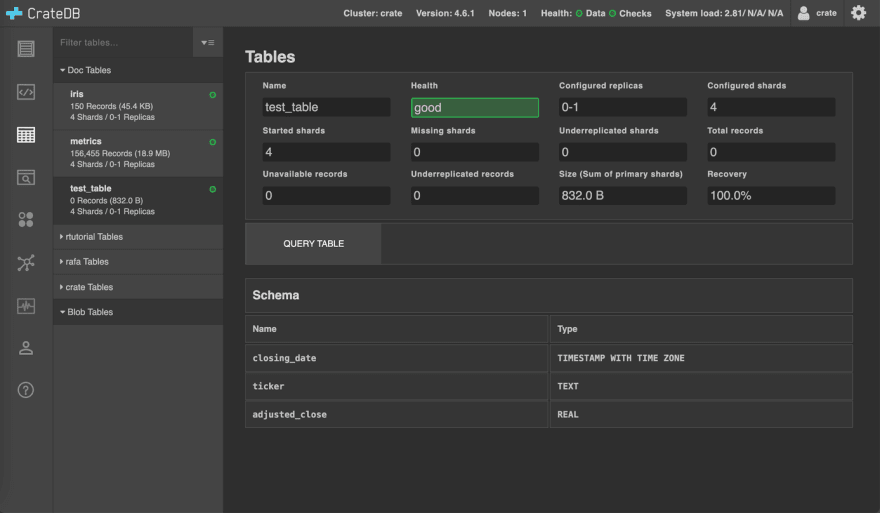
curr.execute(statement)I check if it works by creating a new test_table and then heading to the CrateDB Admin UI to see if my function created a table.
create_table('test_table')
And in fact, I can see the new (empty) table in the CrateBD Admin UI!
Note: the iris and metrics tables, as well as the other database schemas such as rtutorial and crate are not related to this tutorial. By following it step by step, one would only see the new test_table in the doc schema
Now I can move on to creating an insert function.
I want to create a function that:
- gets the table name and the data as parameters
- makes an insert statement for each date in my data, containing data from all S&P-500 companies
- executes these statements until all the data was inserted into CrateDB.
(In the next steps I go through each part of this function. However, I have a snippet of the complete function at the end of this section)
Formatting the entries is crucial for successful insertion.
However, because of that, this function became rather long: so I will go through each section separately and then join them all in the end.
- First, I make a copy from the original data and save it in
df: that way I can edit the DataFrame without changing the original data. Then, I create a table with the table_name (a new table will only be created in case there is no table with such a name). Finally, I create aticker_symbolsvariable, which stores the list of company symbols.
def insert_values(table_name, data):
df = data.copy()
# creates a new table (in case it does not exist yet)
create_table(table_name)
ticker_symbols = get_sp500_ticker_symbols()- Now I must format the closing_dates to a type accepted by CrateDB, which can be found on the CrateDB - Reference page. I print the closing_dates column to get a grasp on the current format and realize it is in the “date” format, which is not supported by CrateDB. So, I change the closing_dates type from “date” to “string” and then format each entry from
dfso that it matches a supported type, in this case, timestamp (without time zone).

# formatting date entries to match timestamp format
df['closing_date'] = df['closing_date'].astype('|S')
for i in range(len(df['closing_date'])):
df['closing_date'][i] = "'{}'".format(df['closing_date'][i] + "{time}".format(time = "T00:00:00Z"))- I can create the insert statements for each line (which represents a date). Here, I get each row of values from
dfand store it as a list indate_values, create the first part of the insert statement ininsert_stmtand create an empty arrayvalues_array, where I will keep the value tuples for each company on that date. - I then create a loop that makes a
(closing_date, ticker, adjusted_close)tuple for each company and adds it to myvalues_array. - I add this
values_arrayto myinsert_stmtand separate all tuples with commas to match the statement standards. - Finally, I print the statement to check if it is correct and then execute it with
curr.execute(insert_stmt)
# formatting data to fit into insert statement and creating statement
for i in range(len(df)):
# saving entries from the ith line as a list of date values
date_values = df.iloc[i, :]
# first part of the insert statement
insert_stmt = "INSERT INTO \"{}\" (closing_date, ticker, adjusted_close) VALUES ".format(table_name)
# creating array of value tuples, as [(c1, c2, c3), (c4, c5, c6), ...]
values_array = []
for k in range(len(ticker_symbols)):
ticker = ticker_symbols[k]
# the date is always the first value in a row
closing_date = date_values[0]
# index is [k+1] because the date itself is in the first position ([0]), so all values are shifted
adj_close = date_values[k+1]
# checking if there is a NaN entry and setting it to -1
if (math.isnan(adj_close)):
adj_close = -1;
# putting a comma between tuples, but not on the last tuple
values_array.append("({},\'{}\',{})".format(closing_date, ticker, adj_close))
insert_stmt += ", ".join(values_array) + ";"
print(insert_stmt)
curr.execute(insert_stmt)I test this function by running
insert_values('test_table', my_data)And it works!

And here is the complete insert_values function:
def insert_values(table_name, data):
df = data.copy()
# creates a new table (in case it does not exist yet)
create_table(table_name)
ticker_symbols = get_sp500_ticker_symbols()
# formatting date entries to match timestamp format
df['closing_date'] = df['closing_date'].astype('|S')
for i in range(len(df['closing_date'])):
df['closing_date'][i] = "'{}'".format(df['closing_date'][i] + "{time}".format(time = "T00:00:00Z"))
# formatting data to fit into insert statement and creating statement
for i in range(len(df)):
# saving entries from the ith line as a list of date values
date_values = df.iloc[i, :]
# first part of the insert statement
insert_stmt = "INSERT INTO \"{}\" (closing_date, ticker, adjusted_close) VALUES ".format(table_name)
# creating array of value tuples, as [(c1, c2, c3), (c4, c5, c6), ...]
values_array = []
for k in range(len(ticker_symbols)):
ticker = ticker_symbols[k]
# the date is always the first value in a row
closing_date = date_values[0]
# index is [k+1] because the date itself is in the first position ([0]), so all values are shifted
adj_close = date_values[k+1]
# checking if there is a NaN entry and setting it to -1
if (math.isnan(adj_close)):
adj_close = -1;
# putting a comma between values tuples, but not on the last tuple
values_array.append("({},\'{}\',{})".format(closing_date, ticker, adj_close))
insert_stmt += ", ".join(values_array) + ";"
curr.execute(insert_stmt)Now I can move on to the last function, which is quite handy regarding the automation.
I want my stock market data in CrateDB to be up to date, which requires that I run this script regularly.
However, I do not want to download data I already have nor have duplicate entries in CrateDB.
That’s why I decide to create this function, which selects the most recent date from the data I have in my CrateDB table. Then, I give this date as a parameter in the download_YFinance_data function: this way, this function will only download new data!
def select_last_inserted_date(table_name):
# creating table (only in case it does not exist yet)
create_table(table_name)
# selecting the maximum date in my table
statement = "select max(closing_date) from " + table_name + ";"
curr.execute(statement)
# fetching the results from the query
recent_date = curr.fetchall()
# if the query is empty or the date is None, start by 2015/01/01
if (len(recent_date) == 0 or recent_date[0][0] is None):
print("No data yet, will return: 2015-01-01")
return "2015-01-01"
# format date from timestamp to YYYY-MM-DD
last_date = recent_date[0][0].strftime("%Y-%m-%d")
# printing the last date
print("Most recent data on CrateDB from: " + last_date)
return last_dateI can test this function by running
select_last_inserted_date('test_table')
And now everything is set!
I have all the necessary functions ready to work!
To have a clean final test, I
- place all the functions at the beginning of the Notebook and run their code blocks
- delete the lines where I was testing the functions
- write new lines calling the functions
These new calls look like this:
# Connecting to CrateDB
conn = connect_to_crateDB(host_name, dbname, port, username, password)
curr = conn.cursor()
table_name = "sp500"
# Creating S&P-500 table
create_table(table_name)
# Getting most recent date from sp500 table
last_date = select_last_inserted_date(table_name)
# downloading the data from the last_date on
data = download_YFinance_data(last_date)
# inserting the data values into CrateDB
insert_values(table_name, data)
I navigate to the CrateDB Admin UI, where I see the new table sp500 was created and that it is filled with the financial data

I make a simple query to get Apple’s data from my sp500 table
select *
from sp500
where ticker = 'AAPL'
order by closing_date limit 100;And instantly get the results

Now I can profit from CrateDB’s speed to query over 77k financial records and run this script whenever I want to update my database with new data!
In this post, I introduced a method to download financial data from Yahoo Finance using Python and pandas and showed how to insert this data in CrateDB.
I profited from CrateDB’s high efficiency to rapidly insert a large amount of data into my database and presented a method to get the most recent input date from CrateDB. That way, I can efficiently keep my records in CrateDB up to date!
23